Clear Sky Science · fr
Jeu de données de dialogues narratifs : corpus conversationnel annoté par locuteur et émotion
Pourquoi les histoires parlées comptent
Quand nous lisons une histoire, nous suivons instinctivement qui parle et ce qu’il ressent. Les ordinateurs, en revanche, ont du mal avec ce type de conversation subtile et émotionnelle. Cet article présente un nouveau jeu de données qui aide les machines à comprendre le dialogue narratif comme les humains : pas seulement les mots, mais quel personnage parle et quelle émotion il exprime. La ressource est construite à partir de milliers d’histoires pour enfants et est conçue pour alimenter des chatbots plus naturels et sensibles aux émotions, des systèmes de narration et des livres parlants.
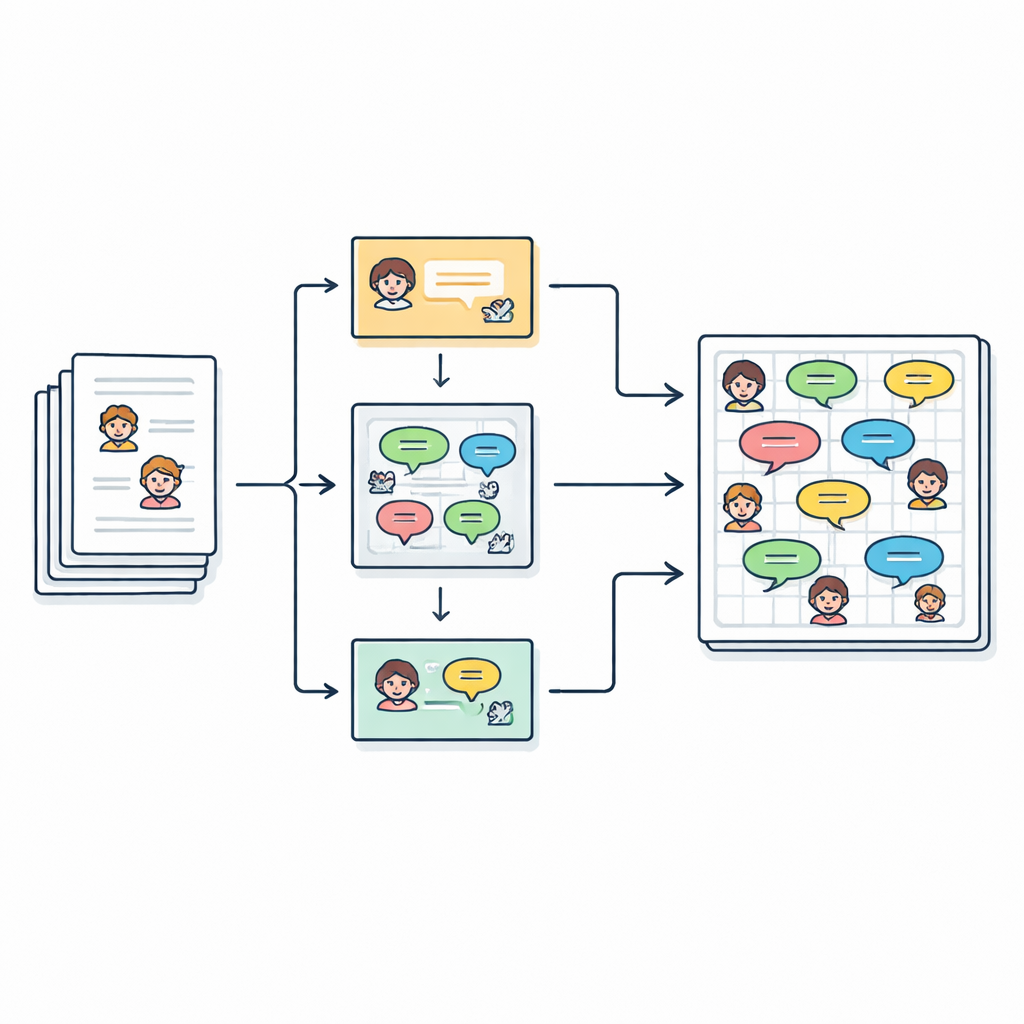
Transformer des histoires en conversations
Les auteurs partent de 2 588 courtes histoires pour enfants en anglais, collectées depuis une archive en ligne. Chaque histoire énumère déjà ses personnages principaux, mais le texte est rédigé en prose continue, avec des morceaux de dialogue encadrés par des guillemets. L’objectif de l’équipe est de transformer cet écrit libre en un script clair composé de lignes du type « Locuteur (Émotion) : Dialogue », afin que chaque phrase prononcée puisse être analysée, modélisée ou même interprétée par une voix synthétique. Au total, ils extraient plus de 27 000 répliques liées à plus de 2 500 personnages distincts.
Déterminer qui a dit quoi
Identifier qui parle dans une histoire est plus délicat qu’il n’y paraît. Les auteurs utilisent souvent des pronoms comme « elle » ou des expressions comme « l’enfant » au lieu de répéter les noms. Pour démêler cela, le pipeline masque d’abord temporairement chaque ligne entre guillemets, puis exécute un outil appelé FastCoref pour renvoyer les pronoms et les descriptions vers le bon personnage. Après avoir rétabli le dialogue original, un autre outil, BookNLP, assigne chaque réplique à un locuteur spécifique et étiquette aussi les personnages avec des traits de base tels que le genre. Les lignes qui ne sont pas entre guillemets sont traitées comme de la narration, prononcées par un « Narrateur » implicite et reçues d’une étiquette émotionnelle neutre, de sorte que l’histoire complète puisse être représentée sous forme de script.
Apprendre aux machines à percevoir les émotions
Ensuite, les chercheurs étiquettent la tonalité émotionnelle de chaque réplique. Ils entraînent un réseau de neurones sur un large jeu de données Twitter où des courts textes ont été annotés avec l’une des six émotions : joie, tristesse, colère, peur, amour et surprise. Le modèle utilise un GRU bidirectionnel, un type de réseau récurrent adapté à la gestion de l’ordre des mots dans les phrases. Après nettoyage et tokenisation des textes, ils entraînent le modèle en donnant un poids supplémentaire aux émotions rares pour réduire les biais. Sur des données Twitter tenues à l’écart, il atteint environ 94 % de précision au global. Ce modèle entraîné est ensuite appliqué aux dialogues des histoires, attribuant une émotion à chaque réplique sans changer la formulation, afin de préserver le style littéraire original.
Capturer le cœur de chaque conte
Au-delà de qui parle et de leur émotion, le jeu de données enregistre aussi le sujet de chaque histoire. Pour cela, les auteurs utilisent un grand modèle de langage (Mistral-7B) avec une consigne soigneusement conçue qui demande exactement cinq mots-clés extraits du texte de l’histoire. Ces mots-clés servent de résumé compact — par exemple des noms, des lieux ou des objets centraux — et peuvent ensuite être utilisés pour « orienter » de nouvelles générations d’histoires. Le résultat final est une représentation stratifiée pour chaque histoire : un ensemble de mots-clés, une liste de personnages et un script où chaque ligne possède un locuteur et une étiquette d’émotion. 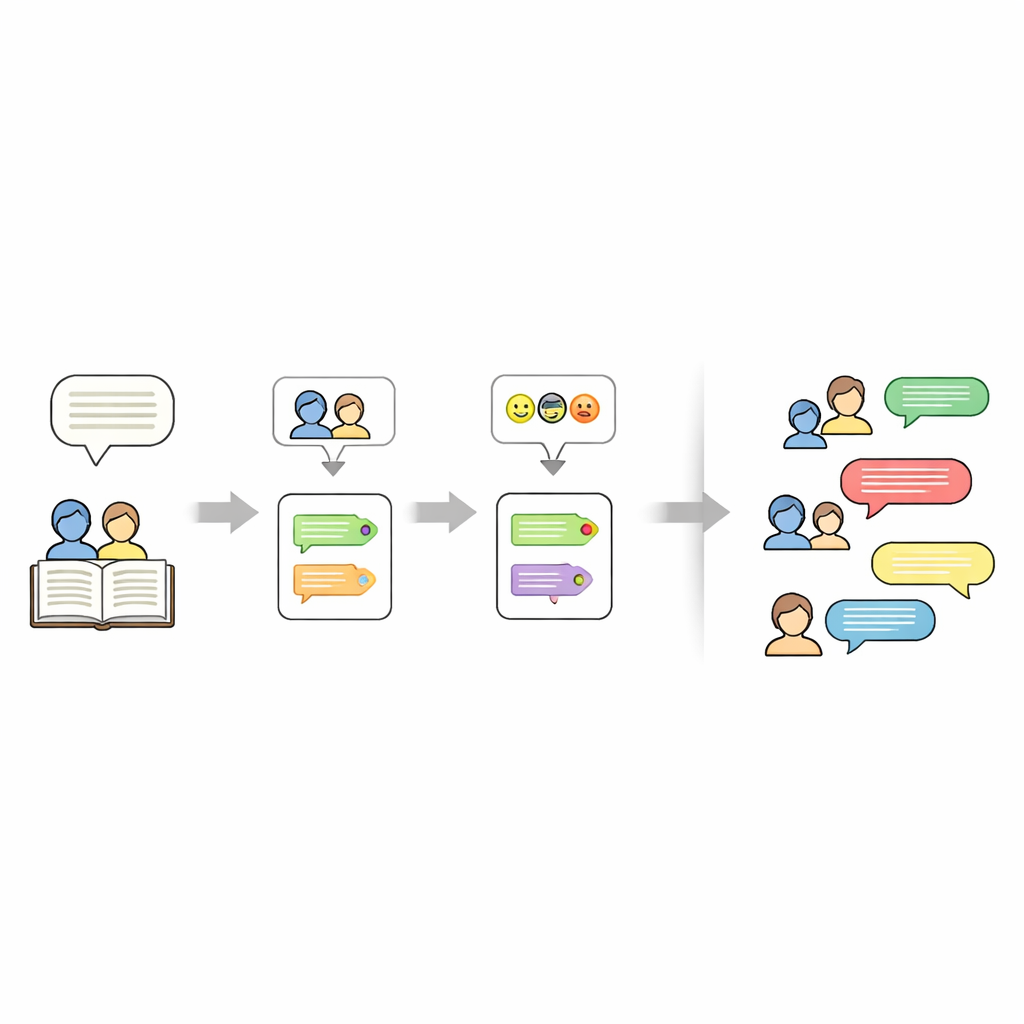
Tester la précision et l’usage réel
Pour vérifier la fiabilité des étiquettes de locuteur, l’équipe examine manuellement des centaines de répliques. En utilisant uniquement BookNLP, environ 73 % des énoncés sont correctement attribués, mais lorsqu’il est combiné avec FastCoref, la précision monte à environ 90 %, notamment dans les passages riches en pronoms. Ils analysent également la manière dont les émotions se succèdent d’une ligne à l’autre et observent des schémas réalistes : par exemple, la joie suit souvent la joie ou mène à la surprise, tandis que la tristesse a plus de chance d’évoluer vers la colère que de basculer instantanément vers la joie. Enfin, ils ajustent un modèle de langage génératif sur ces données, montrant qu’il peut produire de nouveaux dialogues qui conservent en grande partie l’émotion ou les mots-clés demandés, et ils pilotent un système de synthèse vocale émotionnelle que les auditeurs jugent à la fois naturel et expressivement adapté.
Ce que cela signifie pour les histoires de demain
En termes simples, ce travail transforme des histoires pour enfants ordinaires en une carte riche de qui parle, de ce qu’il ressent et de ce dont parle le récit. Plutôt que de considérer le texte comme un flux plat de mots, le jeu de données permet aux ordinateurs de suivre les personnages et leurs émotions changeantes d’une réplique à l’autre. Cela en fait un élément puissant pour des applications futures, des livres audio qui interprètent chaque personnage avec le ton approprié, aux outils d’écriture créative et aux jeux éducatifs qui répondent avec sensibilité à l’humeur d’un enfant. En publiant librement ce corpus structuré et conscient des émotions, les auteurs offrent aux chercheurs un nouvel outil pour étudier et construire des systèmes narratifs véritablement expressifs.
Citation: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Mots-clés: dialogue sensible aux émotions, jeu de données de narration, attribution du locuteur, synthèse vocale émotionnelle, IA narrative