Clear Sky Science · it
Dataset di Dialoghi Narrativi: Corpus Conversazionale Annotato per Parlatore ed Emozione
Perché le storie parlanti sono importanti
Quando leggiamo una storia, teniamo istintivamente traccia di chi parla e di come si sente. I computer, invece, faticano con questo tipo di conversazione sottile ed emotiva. Questo articolo presenta un nuovo dataset che aiuta le macchine a comprendere i dialoghi delle storie come fanno le persone: non solo le parole, ma anche quale personaggio parla e quale emozione esprime. La risorsa è costruita a partire da migliaia di fiabe per bambini ed è pensata per alimentare chatbot più naturali e sensibili alle emozioni, sistemi di narrazione e libri parlanti.
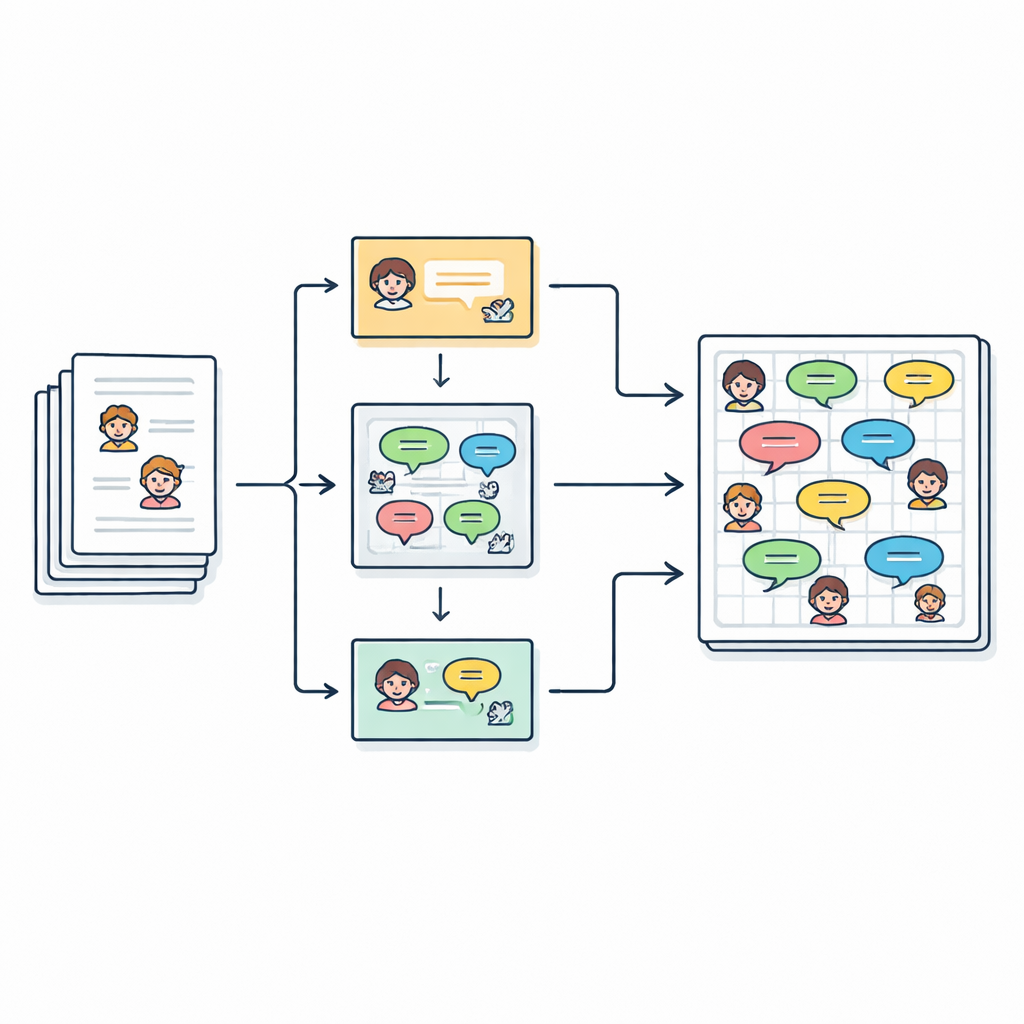
Trasformare le storie in conversazioni
Gli autori partono da 2.588 racconti brevi in inglese per bambini raccolti da un archivio online. Ogni storia elenca già i suoi personaggi principali, ma il testo è scritto come prosa continua, con porzioni di dialogo racchiuse tra virgolette. L’obiettivo del team è trasformare questa scrittura libera in una sceneggiatura pulita composta da righe del tipo “Parlatore (Emozione): Dialogo”, in modo che ogni frase pronunciata possa essere studiata, modellata o perfino interpretata da una voce sintetica. In totale estraggono oltre 27.000 battute dialogiche collegate a più di 2.500 personaggi distinti.
Capire chi ha detto cosa
Stabilire chi sta parlando in una storia è più complicato di quanto sembri. Gli autori spesso usano pronomi come “lei” o frasi come “il bambino” invece di ripetere i nomi. Per sbrogliare questo, la pipeline prima maschera temporaneamente ogni battuta tra virgolette, poi esegue uno strumento chiamato FastCoref per ricondurre pronomi e descrizioni al personaggio giusto. Dopo il ripristino del dialogo originale, un altro strumento, BookNLP, assegna ogni battuta a un parlante specifico e tagga anche i personaggi con tratti di base come il genere. Le righe che non sono tra virgolette vengono trattate come narrazione, pronunciate da un implicito “Narratore” e ricevendo un’etichetta emotiva neutra, così che l’intera storia possa essere rappresentata in forma di copione.
Insegnare alle macchine a cogliere le emozioni
Successivamente i ricercatori etichettano il tono emotivo di ogni battuta dialogica. Addestrano una rete neurale su un ampio dataset di Twitter dove brevi testi sono stati taggati con una delle sei emozioni: gioia, tristezza, rabbia, paura, amore e sorpresa. Il modello usa un GRU bidirezionale, un tipo di rete ricorrente adatta a gestire l’ordine delle parole nelle frasi. Dopo aver pulito e tokenizzato i testi, addestrano il modello attribuendo un peso supplementare alle emozioni più rare per ridurre i bias. Su dati Twitter tenuti da parte, raggiunge circa il 94% di accuratezza complessiva. Questo modello addestrato viene poi applicato ai dialoghi delle storie, assegnando un’emozione a ogni battuta senza alterarne la formulazione, in modo da preservare lo stile letterario originale.
Catturare il cuore di ogni racconto
Oltre a chi parla e a come si sente, il dataset registra anche di cosa tratta ogni storia. Per questo gli autori usano un grande modello linguistico (Mistral-7B) con un prompt accuratamente progettato che richiede esattamente cinque parole chiave estratte dal testo della storia. Queste parole chiave fungono da sommario compatto — per esempio nomi, luoghi o oggetti centrali — e possono poi essere usate per “indirizzare” nuove generazioni di storie. Il risultato finale è una rappresentazione stratificata per ogni racconto: un insieme di parole chiave, una lista di personaggi e una sceneggiatura dove ogni battuta ha un parlante e un tag di emozione. 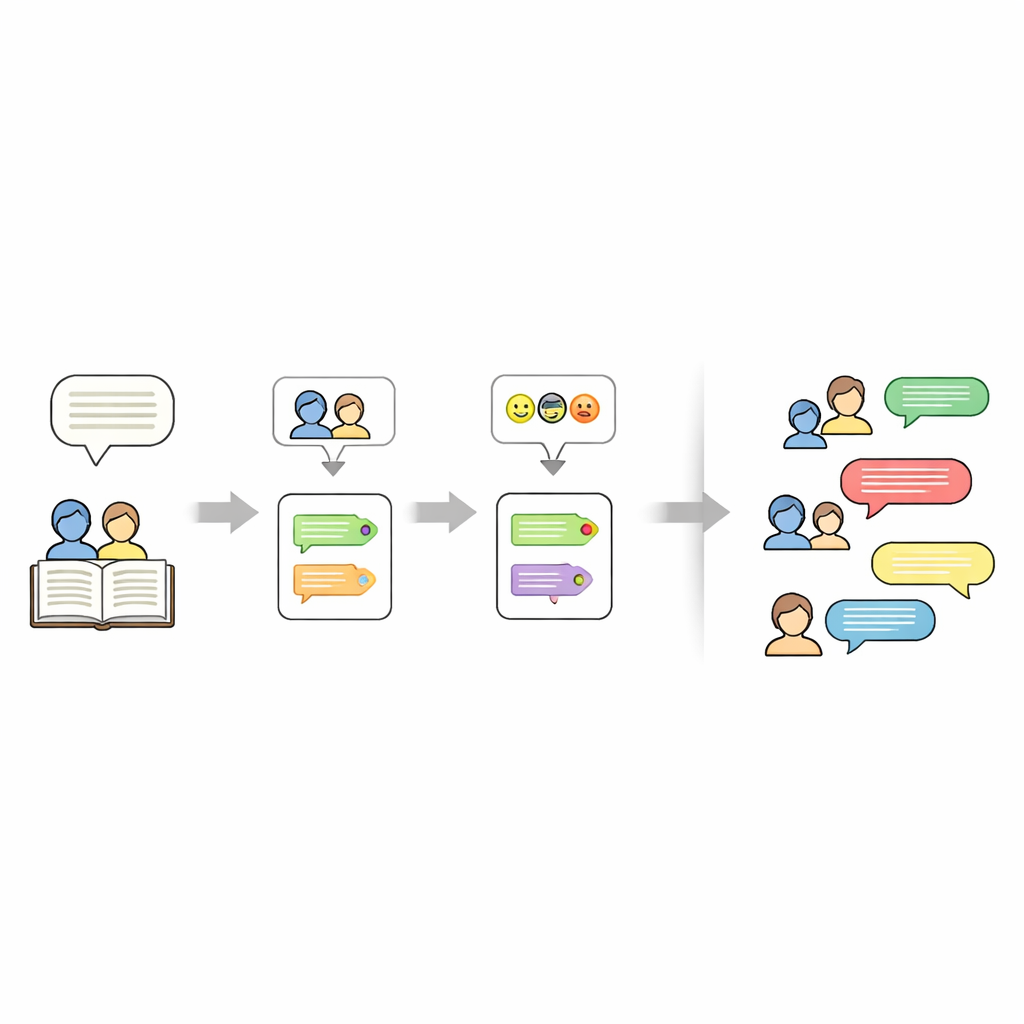
Testare l’accuratezza e l’uso pratico
Per verificare quanto siano affidabili le etichette dei parlanti, il team revisiona manualmente centinaia di battute. Usando solo BookNLP l’attribuzione corretta riguarda circa il 73% delle enunciazioni, ma quando viene combinato con FastCoref l’accuratezza sale a circa il 90%, specialmente nei passaggi con molti pronomi. Analizzano anche come le emozioni si succedono da una battuta all’altra e trovano pattern realistici: per esempio la gioia spesso segue la gioia o conduce alla sorpresa, mentre la tristezza è più probabile che evolva verso la rabbia piuttosto che ribaltare subito in gioia. Infine, mettono a punto un modello generativo linguistico su questi dati, mostrando che può produrre nuovi dialoghi che in larga misura preservano l’emozione o le parole chiave richieste, e pilotano un sistema di sintesi vocale emotiva che gli ascoltatori giudicano sia naturale sia espressivamente appropriato.
Cosa significa questo per le storie future
In termini semplici, questo lavoro trasforma normali racconti per bambini in una ricca mappa di chi parla, come si sente e di cosa tratta il racconto. Invece di trattare il testo come un flusso piatto di parole, il dataset permette ai computer di seguire i personaggi e le loro emozioni mutevoli di battuta in battuta. Questo lo rende un componente potente per applicazioni future, dagli audiolibri che interpretano ogni personaggio con il tono giusto, a strumenti di scrittura creativa e giochi educativi che rispondono con sensibilità all’umore di un bambino. Rilasciando liberamente questo corpus strutturato e consapevole delle emozioni, gli autori offrono ai ricercatori un nuovo modo per studiare e costruire sistemi narrativi davvero espressivi.
Citazione: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Parole chiave: dialogo consapevole delle emozioni, dataset di narrazione, attribuzione del parlante, sintesi vocale emotiva, IA narrativa