Clear Sky Science · zh
SciCUEval:用于评估大语言模型科学语境理解的综合数据集
为什么更聪明的科学人工智能很重要
科学家们开始依赖大语言模型——同一类技术也驱动着流行的聊天机器人——来阅读论文、梳理数据库,甚至提出新实验建议。但科学信息通常密集、多样且经常不完整,现有模型也会在错误时表现出自信。本文介绍了 SciCUEval,这是一个新的公开数据集,旨在严谨测试这些模型对科学语境的真实理解能力,目标是让未来的 AI 助手在真实实验室和诊所中更可靠。
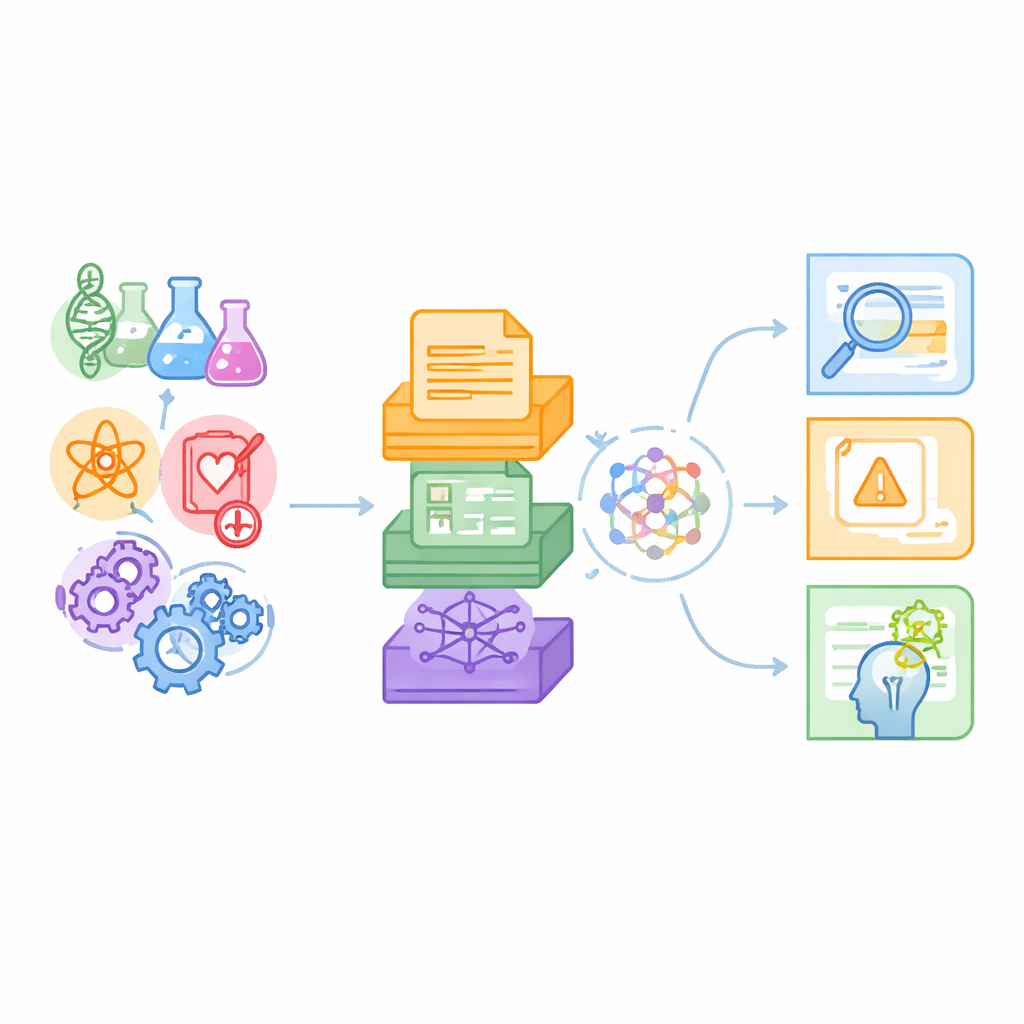
为擅长科学的机器打造的新测试床
作者认为现有基准大多检测日常语言任务或单一的科学细分领域(例如化学问答),并且通常仅依赖纯文本。真实的科学则横跨多个学科,将期刊段落与数据表和复杂关系图混合在一起。SciCUEval 的设计旨在反映这种现实。它捆绑了涵盖生物学、化学、物理学、生物医学和材料科学的十个子数据集,数据来源于可信渠道,如 arXiv 预印本、国际核数据集合、材料数据库和生物医学知识库。最终产生了超过 11,000 道精心构建的问题,旨在考验语言模型真正理解的深度,而非它们的虚张声势能力。
将文本、数值与网络整合在一起
SciCUEval 的一个关键特征是其混合的数据格式。有些问题由非结构化文本支持——来自论文和实验方案的片段;有些依赖结构化表格,例如列出核测量或材料属性的表格;还有些使用“知识图”,在图中基因、药物或疾病等实体通过带类型的连线相互关联。每个问题都包含问题本身、正确答案、真正相关的支持片段,以及包含额外可能干扰项的更大背景上下文。问题以多种常见形式出现——开放式回答、选择题、判断题和填空题——使该基准对多种评估风格都具有灵活性。
四种探测科学理解的方式
为了超越简单的事实检索,该数据集围绕科学家日常需要并且 AI 系统必须学习模仿的四项核心技能进行组织。第一是寻找相关信息:模型能否定位到真正回答问题的关键表格行或图表条目,同时忽略相似但无关的干扰项?第二是识别信息何时缺失或不可靠,并在无法回答时明确拒绝而不是虚构答案。第三是整合来自多个来源的片段——例如,将一张测量表与对实验条件的单独描述联系起来。最后,情境感知推理测试模型能否依据提供的证据得出未明说但明确暗示的逻辑结论。总体上,这些技能构成了在科学场景中“理解”应有含义的结构化清单。
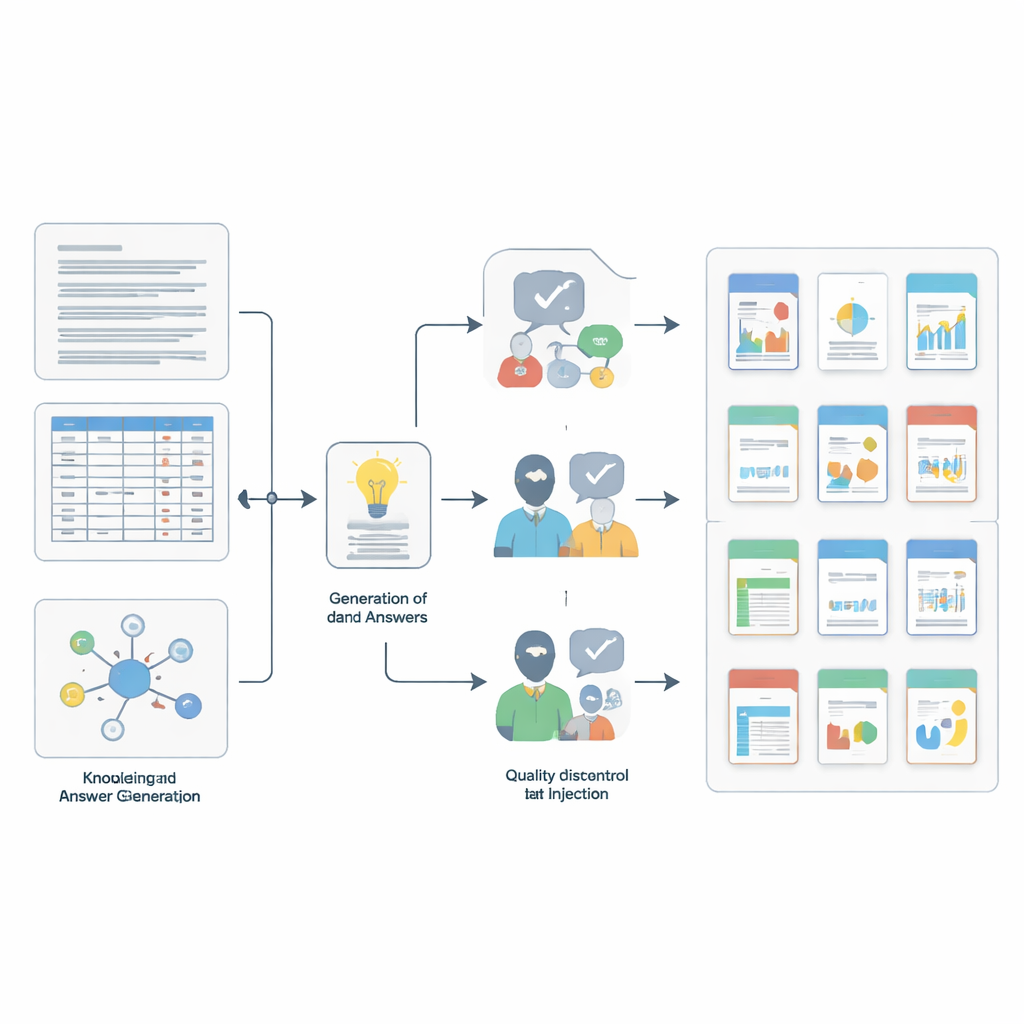
问题如何构建与核查
构建这样的基准本身需要一套小型的科学工作流程。团队首先从源集合中抽样出小而一致的片段——简短的文本段落、单行表格或成套的关联条目。然后他们使用一个强大的语言模型,在详细提示的指导下,为每个片段起草基于该片段并匹配四项技能之一的候选问答对。为了增加测试难度,作者通过插入在意义上看起来相似但实际上无关的额外条目来加入“噪声”,使用先进的相似性搜索和重叠过滤器。最后,双阶段质量检查确保了严格性:另一强模型判断每个答案是否真正由支持上下文得出,随后五位博士级专家人工审查了数千项,剔除任何不清晰、具误导性或未被证据充分支持的条目。
当今模型做对与做错的地方
借助 SciCUEval,作者系统性地评估了 18 款领先的语言模型,包括广泛使用的专有系统以及开源的一般用途和面向科学的模型。他们发现配备明确推理策略且参数量大的模型通常表现最佳,常常优于规模更小或训练更为狭窄的科学模型。大多数系统在基本的相关性查找上表现尚可,并且在处理自由文本上优于密集的表格或图结构数据。然而,几乎所有模型都难以承认信息不足,经常给出自信但无根据的答案。尽管专门的科学模型在领域特定材料上受过训练,但在整体推理能力和处理多模态数据方面,往往落后于最强的一般模型。
这对更安全的科学人工智能意味着什么
对于关注 AI 进入实验室、医院和材料设计领域的非专业人士而言,SciCUEval 既是警示也是前进的道路。警示在于,当科学证据不完整或散布于多种格式时,今天令人印象深刻的语言模型仍然容易过度自信。前进的道路是一套透明且具有挑战性的基准,能够暴露这些弱点并帮助开发者衡量真实进步。通过为社区提供一个共享的、开放的科学语境理解测试,作者旨在引导未来模型不仅在科学方面听起来聪明,而且行为上更像谨慎、以证据为导向的合作者。
引用: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
关键词: 科学基准, 大型语言模型, 语境理解, 多模态科学数据, 人工智能评估