Clear Sky Science · ja
SciCUEval:大規模言語モデルの科学的文脈理解を評価するための包括的データセット
より賢い科学AIが重要な理由
研究者たちは論文の読解、データベースの精査、さらには新しい実験の提案に至るまで、人気のチャットボットの背後にあるのと同じ大規模言語モデルに頼り始めています。しかし科学情報は密度が高く、多様で、しばしば不完全です。今日のモデルは自信を持って語る一方で誤りを含むことがあります。本稿は SciCUEval を紹介します。これは、こうしたモデルが本当に科学的文脈をどれだけ理解しているかを厳密に検証するために作られた新しい公開データセットであり、将来の実験室や臨床現場でのAI支援をより信頼できるものにすることを目指しています。
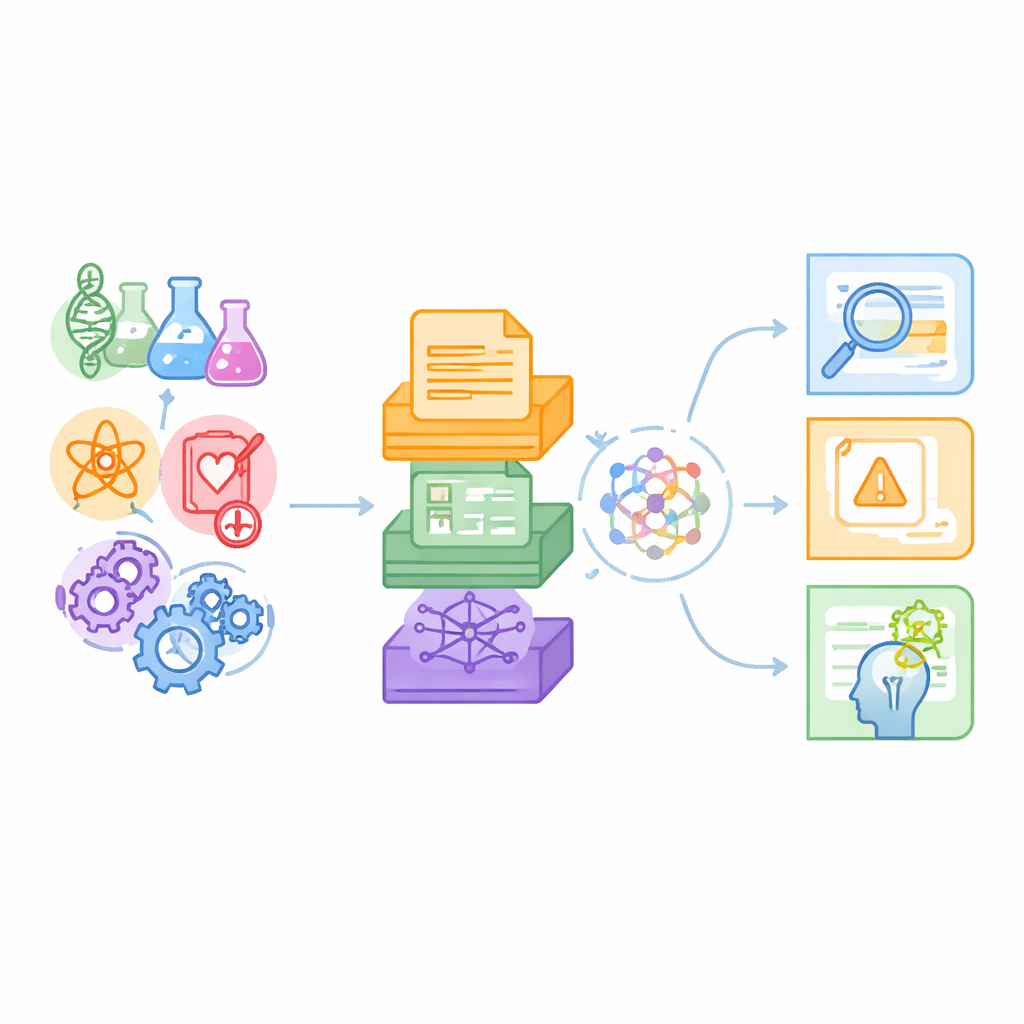
科学に精通した機械のための新しい試験台
著者らは、既存のベンチマークは日常言語の課題や化学のQAなど単一の科学分野を主に扱い、通常はプレーンテキストのみを用いていると指摘します。対照的に実際の科学は多分野にまたがり、論文の段落とデータ表、複雑な関係図を混在させます。SciCUEval はこの現実を反映するよう設計されています。本データセットは、生物学、化学、物理学、生命医科学、材料科学を含む10のサブデータセットを束ねており、arXivのプレプリント、国際的な原子核データ集、材料データベース、医学知識ベースなど信頼できる情報源から引かれています。その結果、言語モデルが“取り繕う”能力ではなく実際に何を理解しているかを試す、1万1千件を超える入念に構築された質問群が得られています。
テキスト、数値、ネットワークを統合
SciCUEval の重要な特徴は、データ形式の混在です。ある質問は論文や実験手順の断片のような非構造化テキストに基づきます。別の質問は、原子核測定値や材料特性といった構造化された表に依存します。さらに「知識グラフ」を利用する問題もあり、遺伝子や薬、疾患といった実体が型付きのリンクで結ばれています。各問題には質問、正解、真に関連する支持情報、そして余分で混乱を招く可能性のあるエントリを混ぜた広い背景コンテキストが含まれます。問題形式は自由記述、選択式、真偽、穴埋めなど馴染みのある複数の形で出題され、評価方式に柔軟に対応できます。
科学的理解を探る4つの方法
単純な事実検索を超えるために、データセットは科学者が日常的に必要とし、AIが模倣すべき4つの核心スキルを軸に整理されています。第一は関連情報の発見:モデルは質問に実際に答える決定的な表の行やグラフの項目を見つけ、類似の紛らわしい項目を無視できるか。第二は情報が欠けている、あるいは信頼できないときに認識し、幻覚せずに明示的に回答を拒否できるか。第三は複数の出典からの断片を結び付ける能力――例えば測定表を実験条件の別の記述と連結すること。最後に文脈依存の推論は、明示的には述べられていないが提供された証拠から明確に示唆される論理的結論を導けるかを試します。これらのスキルは合わせて、科学的場面における「理解」が何を意味するかの構造化されたチェックリストを形成します。
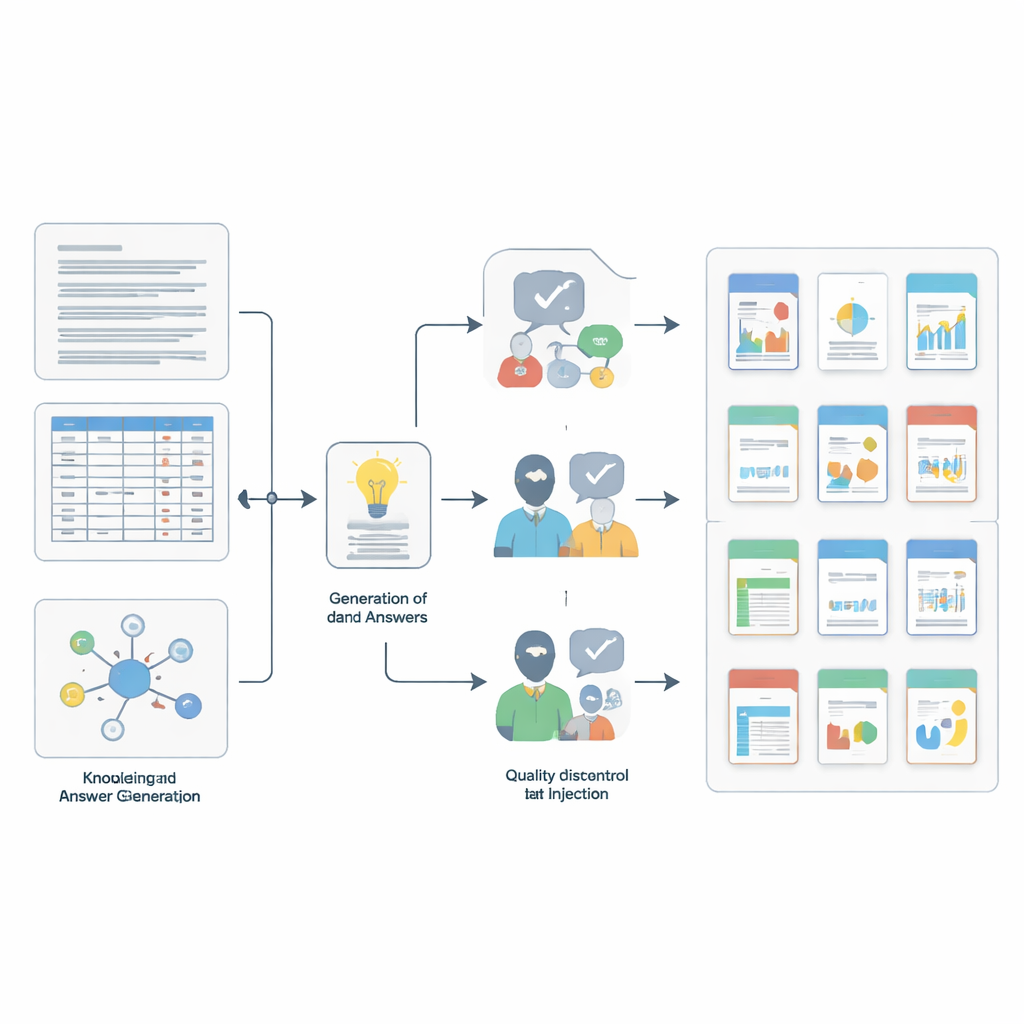
質問の作成と検証方法
このようなベンチマークを構築するには独自の小規模な科学的ワークフローが必要でした。チームはまず情報源コレクションから小さく一貫した断片――短いテキスト抜粋、個別の表の行、あるいはリンクされたエントリの集合――をサンプリングしました。次に強力な言語モデルを詳細なプロンプトで誘導して、各断片に根ざした候補の質問と回答のペアを作成し、それを4つのスキルのいずれかに割り当てました。受験モデルにとって難易度を上げるため、著者らは高度な類似検索とオーバーラップフィルタを使って意味的に似て見えるが実際には無関係な“ノイズ”を挿入しました。最後に二段階の品質チェックで厳密性を確保しました:別の強力なモデルが各回答が本当に支持文脈から導かれるかを判定し、さらに5名の博士レベルの専門家が数千件を手作業でレビューし、不明瞭、誤解を招く、または証拠で十分に裏付けられていない項目を却下しました。
現行モデルの得手・不得手
SciCUEval を用いて、著者らは広く使われる専有システムからオープンソースの汎用・科学特化モデルまで、18の代表的な言語モデルを体系的に評価しました。明示的な推論戦略を持ち、パラメータ数が多いモデルほど良好な傾向があり、しばしば小規模またはより狭い分野で訓練された科学モデルを上回りました。ほとんどのシステムは基本的な関連性検出は比較的うまく処理し、自由記述形式では密な表やグラフ構造データより良い成績を示しました。しかし、ほぼ全てのモデルが情報が不足しているときにそれを認めることに苦労し、自信を持っているが根拠のない回答を頻繁に提示しました。分野特化で訓練された科学モデルは、分野固有の資料で学習しているにもかかわらず、総合的な推論や複数モダリティの処理では最も強い汎用モデルに遅れを取ることが多いことが分かりました。
より安全な科学AIに向けての意義
研究室や病院、材料設計の分野にAIが浸透するのを見守る非専門家にとって、SciCUEval は警告と前進の道筋の双方を示します。警告は、今日の印象的な言語モデルでさえ、科学的証拠が不完全であったり形式が散在している場合に過信しやすい点です。前進の道は、これらの弱点を露呈させ、開発者が実際の進歩を測れるようにする透明で挑戦的なベンチマークです。コミュニティに共有される公開された科学的文脈理解の試験を提供することで、著者らは将来のモデルが単に科学について賢く見えるだけでなく、証拠志向で慎重な協力者として振る舞う方向へ導くことを目指しています。
引用: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
キーワード: 科学的ベンチマーク, 大規模言語モデル, 文脈理解, マルチモーダルな科学データ, AI評価