Clear Sky Science · ar
SciCUEval: مجموعة بيانات شاملة لتقييم فهم السياق العلمي في نماذج اللغة الكبيرة
لماذا تهمّنا نماذج الذكاء الاصطناعي العلمية الأذكى
بدأ العلماء يعتمدون على نماذج اللغة الكبيرة — وهي نفس عائلة الأدوات وراء برامج الدردشة الشائعة — لقراءة الأوراق العلمية، والبحث في قواعد البيانات، وحتى اقتراح تجارب جديدة. لكن المعلومات العلمية كثيفة ومتنوعة وغالبًا ما تكون غير كاملة، والنماذج الحالية قد تبدو واثقة بينما تكون مخطئة. يقدم هذا المقال SciCUEval، مجموعة بيانات عامة جديدة صممت لاختبار مدى فهم هذه النماذج للسياق العلمي بشكل صارم، بهدف جعل المساعدين المعتمدين على الذكاء الاصطناعي أكثر موثوقية في المختبرات والعيادات الحقيقية.
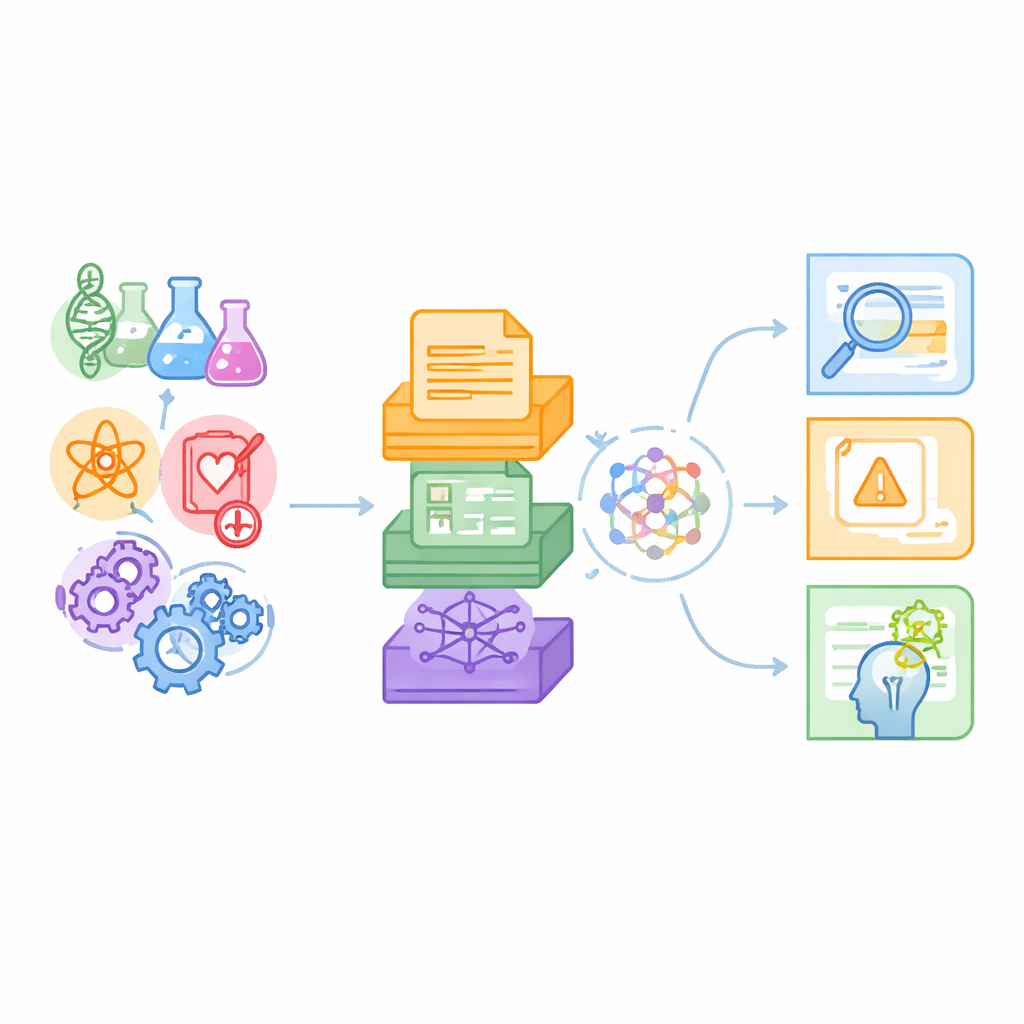
بيئة اختبار جديدة للآلات المطلعة على العلم
يجادل المؤلفون بأن المقاييس الحالية تختبر في الغالب مهام لغة يومية أو تخصصات علمية فرعية منفردة، مثل الإجابة عن أسئلة الكيمياء، وغالبًا ما تعتمد فقط على النص العادي. العلوم الحقيقية، بالمقابل، تمتد عبر العديد من التخصصات وتخلط فقرات المجلات مع جداول بيانات وخرائط علاقات معقدة. صُممت SciCUEval لتعكس هذا الواقع. تضم عشر مجموعات فرعية تغطي علم الأحياء والكيمياء والفيزياء والطب الحيوي وعلوم المواد، كل منها مأخوذ من مصادر موثوقة مثل مسودات arXiv، ومجاميع بيانات نووية دولية، وقواعد بيانات المواد، وقواعد المعرفة الطبية الحيوية. النتيجة أكثر من 11,000 سؤال بُنيت بعناية لاختبار ما تفهمه نماذج اللغة فعليًا، بدلًا من مدى براعتها في التظاهر بالمعرفة.
جمع النصوص والأرقام والشبكات
ميزة أساسية في SciCUEval هي خليطها من صيغ البيانات. بعض الأسئلة مدعومة بنصوص غير منظمة — مقتطفات من أوراق وبروتوكولات تجريبية. تعتمد أسئلة أخرى على جداول منظمة تسرد، على سبيل المثال، قياسات نووية أو خصائص المواد. يستخدم بعضها أيضًا «رسومًا بيانية معرفية» حيث ترتبط كيانات مثل الجينات أو الأدوية أو الأمراض بروابط ذات أنواع محددة. يتضمن كل مسألة السؤال، والإجابة الصحيحة، والقطع الداعمة ذات الصلة فعلًا، وسياق خلفي أوسع محشو بعناصر إضافية يمكن أن تشتت الانتباه. تظهر الأسئلة في عدة أشكال مألوفة — إجابات مفتوحة، اختيار من متعدد، صحّ أو خطأ، واملأ الفراغ — مما يجعل المعيار مرنًا لأنماط تقييم متعددة.
أربع طرق لاختبار الفهم العلمي
للتجاوز عن مجرد استرجاع الحقائق، نُظمت مجموعة البيانات حول أربع مهارات أساسية يحتاجها العلماء بشكل روتيني ويجب أن تتعلمها أنظمة الذكاء الاصطناعي لتقلدها. الأولى هي إيجاد المعلومات ذات الصلة: هل يمكن للنموذج أن يحدد صف الجدول أو مدخل الرسم البياني الحاسم الذي يجيب عن السؤال، مع تجاهل المشتتات الشبيهة؟ الثانية هي معرفة متى تكون المعلومات مفقودة أو غير موثوقة، والامتناع صراحة عن الإجابة بدلًا من الاختلاق. الثالثة هي جمع قطع من مصادر متعددة — على سبيل المثال، ربط جدول قياسات بوصف منفصل لظروف التجربة. وأخيرًا، يختبر الاستدلال الواعي بالسياق ما إذا كان النموذج يستطيع استنتاج نتيجة منطقية ليست منصوصة صراحةً لكنها موحاة بوضوح بالأدلة المقدمة. تشكل هذه المهارات معًا قائمة تحقق منظمة لما يجب أن يعنيه «الفهم» في البيئات العلمية.
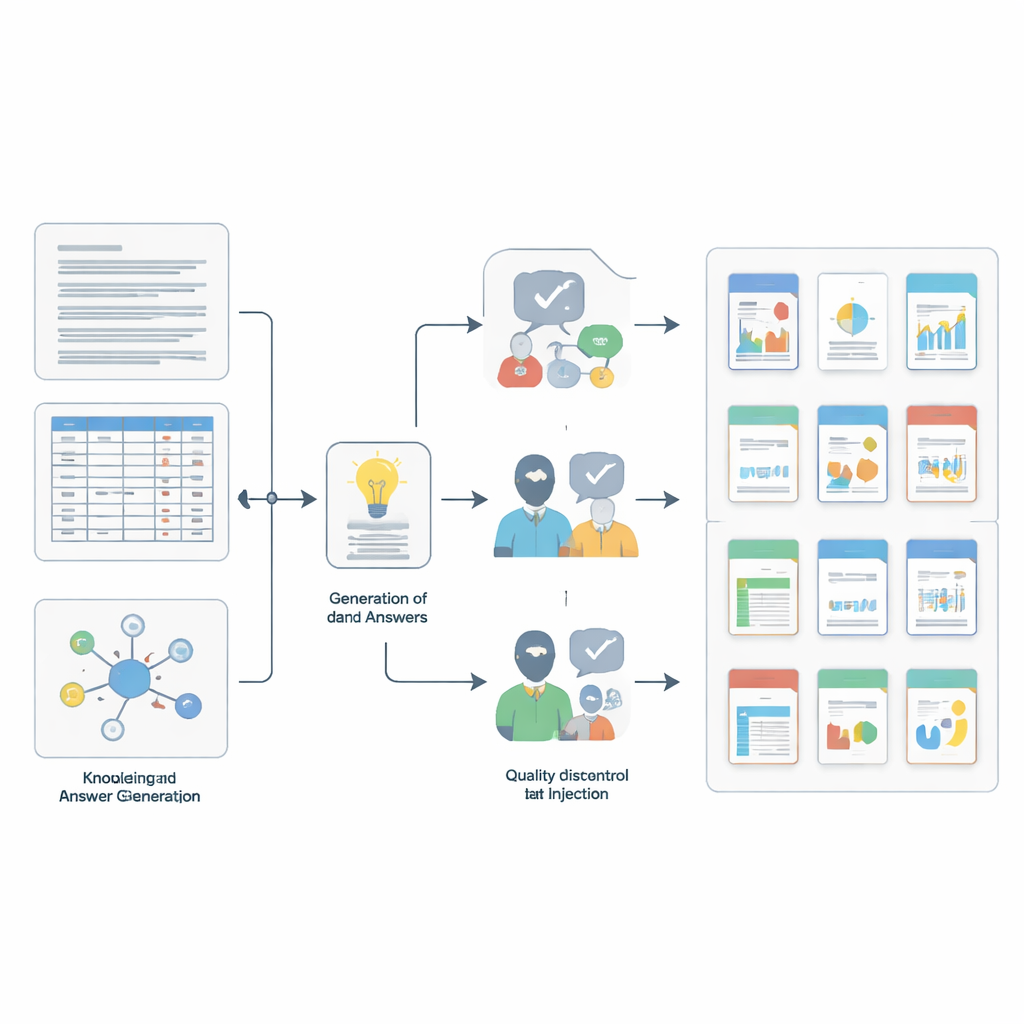
كيف بُنِيت الأسئلة وفُحِصت
تطلب بناء مثل هذا المعيار سير عمل علمي مصغر خاص به. أخذ الفريق أولًا عينات صغيرة ومتناسقة من مجموعات المصدر — مقاطع نص قصيرة، صفوف جدول فردية، أو مجموعات من المدخلات المرتبطة. ثم استخدموا نموذج لغة قويًا، موجّهًا بمطالبات مفصّلة، لصياغة أزواج سؤال-إجابة مرشحة مؤسَّسة على كل مقطع ومرتبطة بإحدى المهارات الأربع. لجعل المهمة أصعب على نماذج الاختبار، أضاف المؤلفون «ضوضاء» بإدراج مدخلات إضافية تبدو متشابهة في المعنى لكنها غير ذات صلة فعليًا، باستخدام بحث تشابه متقدم ومرشحات التداخل. أخيرًا، ضَمِن تدقيق جودة من مرحلتين الصرامة: حكم نموذج قوي آخر بما إذا كانت كل إجابة تتبع فعلاً من السياق الداعم، ثم راجع خمسة خبراء حاملين لدرجة الدكتوراه يدويًا آلاف البنود، رافضين أيًا منها كان غير واضح أو مضلل أو غير مدعوم بالكامل بالأدلة.
ما الذي تجيده النماذج اليوم وما الذي تخطئ فيه
بوجود SciCUEval، قيّم المؤلفون بشكل منهجي 18 نموذجًا رائدًا للغة، بما في ذلك أنظمة احتكارية مستخدمة على نطاق واسع ونماذج مفتوحة المصدر عامة ومتخصصة علميًا. وجدوا أن النماذج المزوَّدة باستراتيجيات استدلال صريحة وعدد كبير من المعاملات تميل إلى الأداء الأفضل، متفوقة في كثير من الأحيان على نماذج علمية أصغر أو مدرَّبة في نطاق أضيق. تعاملت معظم الأنظمة بشكل معقول مع إيجاد الملاءمة الأساسية وأدت أداءً أفضل في النص الحر من الجداول المكتظة أو البيانات المهيكلة كرسوم بيانية. ومع ذلك، كافحت الغالبية للاعتراف عندما تفتقر إلى معلومات كافية، وغالبًا ما قدّمت إجابات واثقة لكن غير مستندة. كما أن النماذج العلمية المتخصصة، على الرغم من تدريبها على مواد ميدانية محددة، غالبًا ما كانت تتأخر عن أقوى النماذج العامة في الاستدلال الكلي وفي التعامل مع وسائط بيانات متعددة.
ما الذي يعنيه هذا لذكاء اصطناعي علمي أكثر أمانًا
بالنسبة لغير المتخصصين الذين يشاهدون دخول الذكاء الاصطناعي إلى المختبرات والمستشفيات وتصميم المواد، تقدم SciCUEval تحذيرًا وطريقًا للمضي قدمًا. التحذير هو أن نماذج اللغة المثيرة للإعجاب اليوم لا تزال عرضة للثقة الزائدة، خصوصًا عندما تكون الأدلة العلمية غير كاملة أو مبعثرة عبر صيغ مختلفة. الطريق للمضي قدمًا هو معيار شفاف وتحدي يكشف عن هذه نقاط الضعف ويساعد المطورين على قياس التقدم الحقيقي. من خلال منح المجتمع اختبارًا مشتركًا ومفتوحًا لفهم السياق العلمي، يهدف المؤلفون إلى توجيه النماذج المستقبلية نحو أن لا تكتفي بالظهور بمظهر الذكي في الأمور العلمية، بل أن تتصرف كمساهمين حريصين ومنطقيي الأدلة.
الاستشهاد: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
الكلمات المفتاحية: معيار علمي, نماذج اللغة الكبيرة, فهم السياق, بيانات علمية متعددة الوسائط, تقييم الذكاء الاصطناعي