Clear Sky Science · ru
SciCUEval: Всесторонний набор данных для оценки понимания научного контекста в больших языковых моделях
Почему важны более «умные» научные ИИ
Ученые всё чаще полагаются на большие языковые модели — ту же семью инструментов, что стоит за популярными чат-ботами — чтобы читать статьи, просеивать базы данных и даже предлагать новые эксперименты. Но научная информация плотная, разнородная и часто неполная, и современные модели могут звучать уверенно, будучи неправы. В этой статье представлена SciCUEval, новый открытый набор данных, созданный для строгой проверки того, насколько действительно хорошо такие модели понимают научный контекст, с целью сделать будущих ИИ‑помощников более надежными в реальных лабораториях и клиниках.
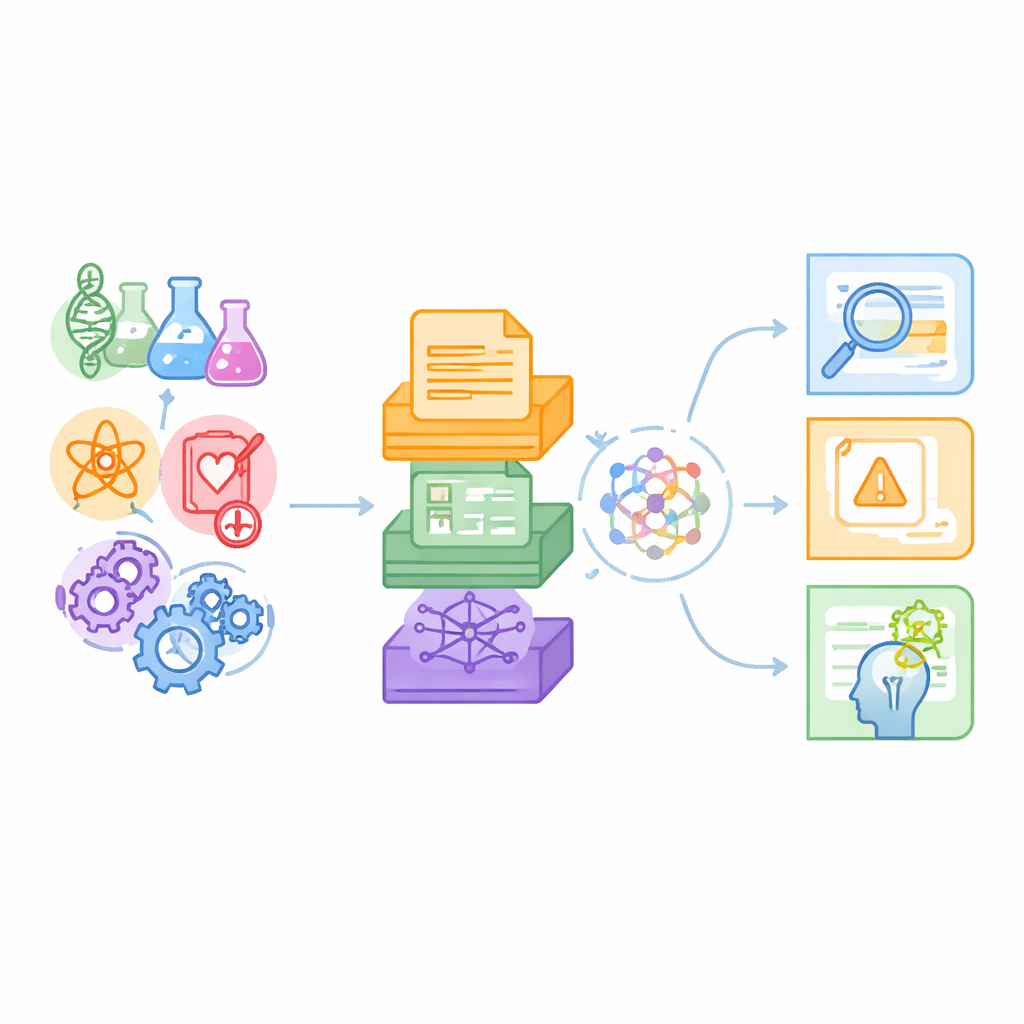
Новая испытательная площадка для «научно грамотных» машин
Авторы утверждают, что существующие бенчмарки в основном проверяют повседневные языковые задачи или отдельные научные ниши, например ответы на вопросы по химии, и обычно опираются только на простой текст. Реальная наука, напротив, охватывает множество дисциплин и сочетает абзацы из журналов с таблицами данных и сложными картами взаимосвязей. SciCUEval задумана так, чтобы отражать эту реальность. Она объединяет десять поднаборов, охватывающих биологию, химию, физику, биомедицину и материаловедение, каждый из которых взят из надежных источников, таких как препринты arXiv, международные коллекции ядерных данных, базы данных материалов и биомедицинские базы знаний. В итоге получилось более 11 000 тщательно составленных вопросов, которые испытывают модели по части того, что они действительно понимают, а не по тому, как хорошо они имитируют знания.
Соединяя текст, числа и сети
Ключевая особенность SciCUEval — её смесь форматов данных. Некоторые вопросы подкреплены неструктурированным текстом — фрагментами статей и протоколов экспериментов. Другие опираются на структурированные таблицы, перечисляющие, например, ядерные измерения или свойства материалов. Третьи используют «графы знаний», в которых сущности вроде генов, препаратов или болезней связаны типизированными связями. Каждая задача включает вопрос, правильный ответ, действительно релевантные поддерживающие фрагменты и более широкий фон, «подсоленный» дополнительными, потенциально вводящими в заблуждение элементами. Вопросы представлены в нескольких привычных формах — открытые ответы, множественный выбор, правда/ложь и заполнение пропусков — что делает бенчмарк гибким для разных стилей оценки.
Четыре способа проверить научное понимание
Чтобы выйти за рамки простого поиска фактов, набор данных организован вокруг четырёх ключевых навыков, которые учёным регулярно требуются и которые системы ИИ должны уметь имитировать. Первый — нахождение релевантной информации: может ли модель сосредоточиться на одной критической строке таблицы или записи графа, которая действительно отвечает на вопрос, игнорируя сходные отвлекающие элементы? Второй — признание того, когда информация отсутствует или ненадёжна, и явный отказ отвечать вместо выдумывания. Третий — комбинирование фрагментов из нескольких источников, например связывание таблицы измерений с отдельным описанием условий эксперимента. Наконец, контекстно‑осмысленное построение вывода проверяет, может ли модель сделать логический вывод, который прямо не сформулирован, но явно следует из представленных доказательств. Вместе эти навыки формируют структурированный чек‑лист того, что должно означать «понимание» в научных условиях.
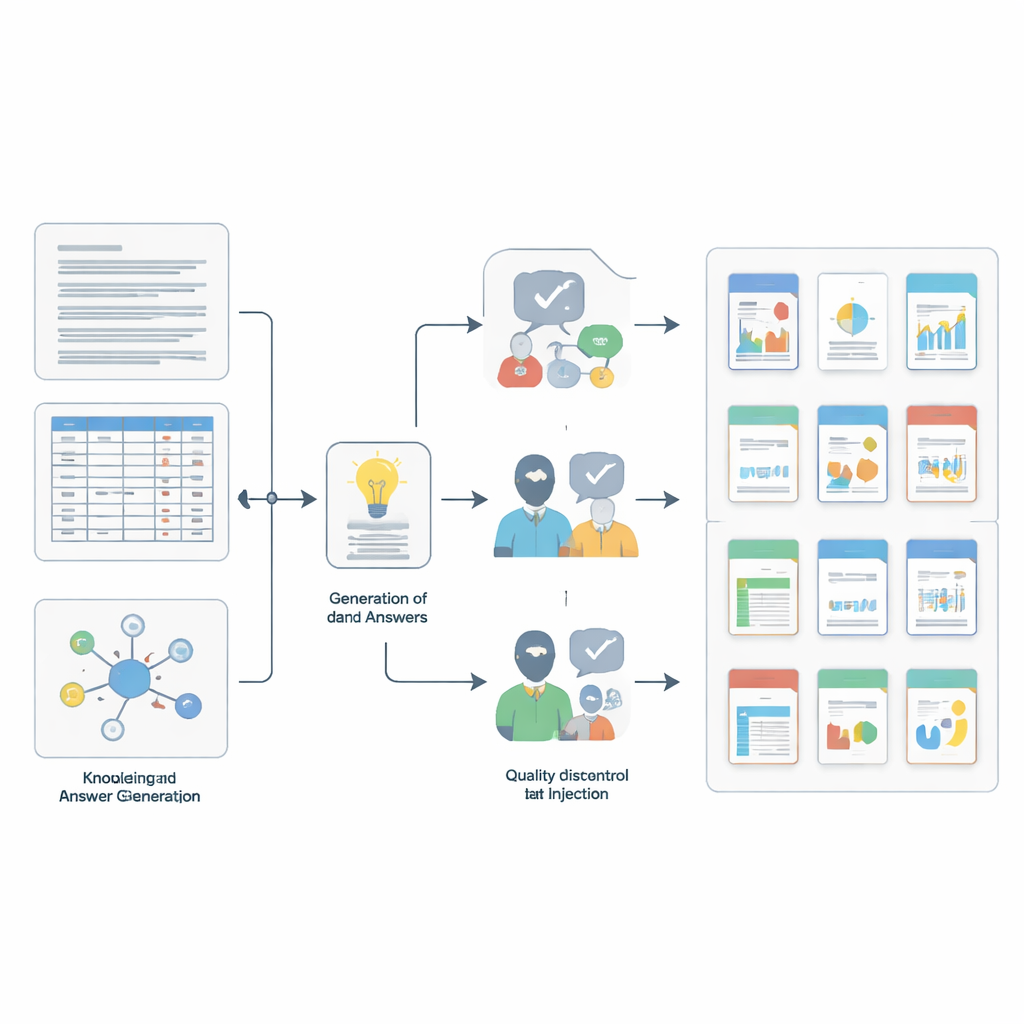
Как строились и проверялись вопросы
Создание такого бенчмарка потребовало собственной миниатюрной научной рабочей схемы. Команда сначала отбирала небольшие, согласованные фрагменты из исходных коллекций — короткие текстовые отрывки, отдельные строки таблиц или наборы связанных записей. Затем они использовали мощную языковую модель, направляемую подробными подсказками, чтобы составить кандидатные пары «вопрос‑ответ», основанные на каждом фрагменте и соответствующие одному из четырёх навыков. Чтобы усложнить задачу моделям, проходящим тест, авторы добавляли «шум», вставляя дополнительные записи, похожие по смыслу, но фактически не относящиеся к делу, с помощью продвинутого поиска по похожести и фильтров перекрытия. Наконец, двухэтапная проверка качества обеспечивала строгость: другая сильная модель оценивала, действительно ли каждый ответ следует из поддерживающего контекста, а затем пять экспертов уровня PhD вручную проверяли тысячи элементов, отклоняя любые неясные, вводящие в заблуждение или не полностью подтверждённые доказательствами вопросы.
Что современные модели делают правильно и где ошибаются
Имея SciCUEval, авторы систематически оценили 18 ведущих языковых моделей, включая широко используемые проприетарные системы и открытые модели общего назначения и ориентированные на науку. Они обнаружили, что модели, оснащённые явными стратегиями рассуждения и большим количеством параметров, как правило, показывали лучшие результаты, часто превосходя более мелкие или узкоспециализированные научные модели. Большинство систем справлялись с базовым поиском релевантности относительно неплохо и лучше работали с свободным текстом, чем с плотными таблицами или данными в виде графов. Тем не менее почти все испытывали трудности с признанием недостатка информации, часто предлагая уверенные, но необоснованные ответы. Специализированные научные модели, несмотря на обучение на материаловом, специфичном для поля, часто отставали от сильнейших общих моделей по общему качеству рассуждений и по работе с несколькими модальностями данных.
Что это значит для более безопасного научного ИИ
Для неспециалистов, наблюдающих за тем, как ИИ входит в лаборатории, больницы и проектирование материалов, SciCUEval представляет и предупреждение, и путь вперёд. Предупреждение состоит в том, что современные впечатляющие языковые модели по‑прежнему склонны к избыточной уверенности, особенно когда научные доказательства неполны или разбросаны по форматам. Путь вперёд — прозрачный, сложный бенчмарк, который выявляет эти слабости и помогает разработчикам измерять реальный прогресс. Предоставляя сообществу общий открытый тест на понимание научного контекста, авторы стремятся направить будущие модели не только к тому, чтобы они звучали умно о науке, но и чтобы вели себя как осторожные, ориентированные на доказательства коллеги.
Цитирование: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Ключевые слова: научный бенчмарк, большие языковые модели, понимание контекста, мультимодальные научные данные, оценка ИИ