Clear Sky Science · pt
SciCUEval: Um Conjunto de Dados Abrangente para Avaliar a Compreensão de Contexto Científico em Grandes Modelos de Linguagem
Por que IAs científicas mais inteligentes importam
Cientistas estão começando a contar com grandes modelos de linguagem — a mesma família de ferramentas por trás de chatbots populares — para ler artigos, vasculhar bases de dados e até sugerir novos experimentos. Mas a informação científica é densa, variada e frequentemente incompleta, e os modelos atuais podem soar confiantes enquanto estão errados. Este artigo apresenta o SciCUEval, um novo conjunto de dados público criado para testar rigorosamente quão bem esses modelos realmente entendem o contexto científico, com o objetivo de tornar os futuros assistentes de IA mais confiáveis em laboratórios e clínicas reais.
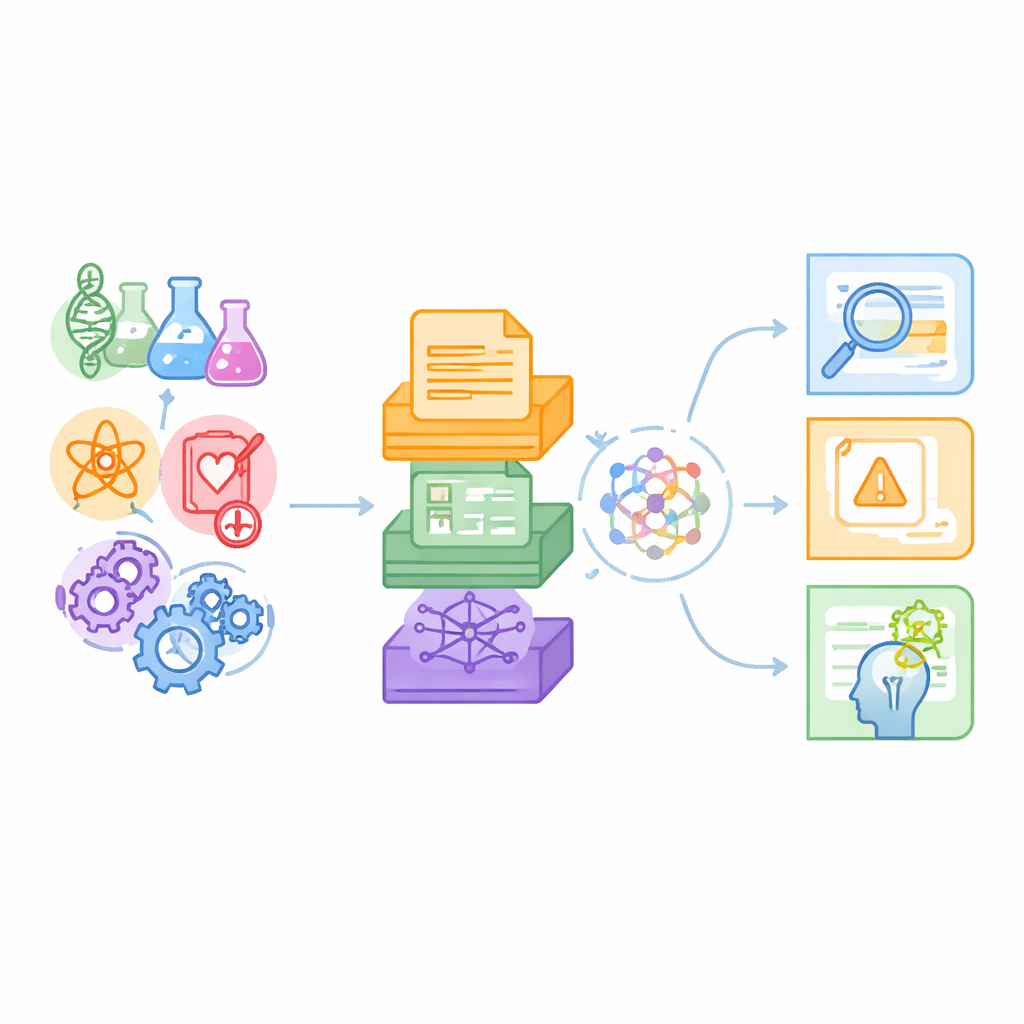
Um novo campo de testes para máquinas afeitas à ciência
Os autores sustentam que benchmarks existentes em sua maioria investigam tarefas de linguagem do dia a dia ou nichos científicos isolados, como perguntas e respostas em química, e geralmente se baseiam apenas em texto simples. A ciência real, em contraste, abrange muitas disciplinas e mistura parágrafos de periódicos com tabelas de dados e mapas complexos de relacionamentos. O SciCUEval foi concebido para espelhar essa realidade. Ele reúne dez subconjuntos cobrindo biologia, química, física, biomedicina e ciência dos materiais, cada um extraído de fontes confiáveis como preprints do arXiv, coleções internacionais de dados nucleares, bancos de dados de materiais e bases de conhecimento biomédicas. O resultado são mais de 11.000 perguntas cuidadosamente elaboradas que testam o que os modelos de linguagem realmente entendem, em vez de quão bem eles fingem saber.
Reunindo texto, números e redes
Uma característica central do SciCUEval é sua mistura de formatos de dados. Algumas questões são sustentadas por texto não estruturado — trechos de artigos e protocolos experimentais. Outras dependem de tabelas estruturadas listando, por exemplo, medidas nucleares ou propriedades de materiais. Ainda outras usam “grafos de conhecimento”, nos quais entidades como genes, medicamentos ou doenças estão conectadas por links tipados. Cada problema inclui a pergunta, a resposta correta, as peças de suporte realmente relevantes e um contexto de fundo maior salpicado com entradas extras que podem confundir. As perguntas aparecem em várias formas familiares — respostas abertas, múltipla escolha, verdadeiro ou falso e preencher a lacuna — tornando o benchmark flexível para muitos estilos de avaliação.
Quatro maneiras de sondar a compreensão científica
Para ir além da simples busca de fatos, o conjunto de dados é organizado em torno de quatro habilidades centrais que os cientistas rotineiramente precisam e que os sistemas de IA devem aprender a imitar. A primeira é encontrar informação relevante: um modelo consegue localizar a linha de tabela ou o ponto de gráfico crucial que realmente responde à pergunta, ignorando distrações semelhantes? A segunda é reconhecer quando a informação está ausente ou é pouco confiável, e recusar-se explicitamente a responder em vez de alucinar. A terceira é combinar fragmentos de várias fontes — por exemplo, ligar uma tabela de medições a uma descrição separada das condições experimentais. Por fim, a inferência sensível ao contexto testa se um modelo pode tirar uma conclusão lógica que não está declarada explicitamente, mas é claramente implicada pela evidência fornecida. Juntas, essas habilidades formam uma lista estruturada do que “compreensão” deveria significar em ambientes científicos.
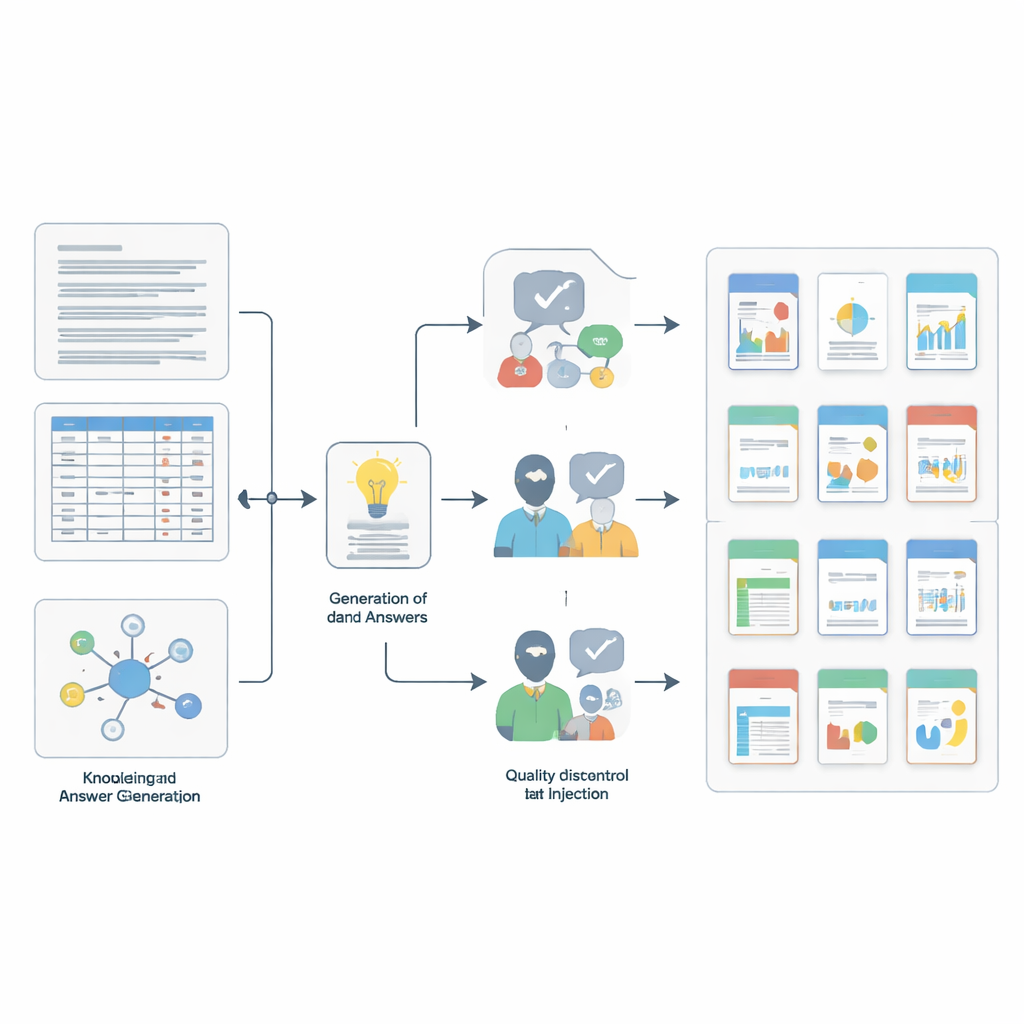
Como as questões foram construídas e verificadas
Construir esse tipo de benchmark exigiu seu próprio fluxo de trabalho científico em miniatura. A equipe primeiro amostrou pequenos trechos coerentes das coleções-fonte — passagens curtas de texto, linhas individuais de tabelas ou conjuntos de entradas vinculadas. Em seguida, usaram um modelo de linguagem poderoso, guiado por prompts detalhados, para rascunhar pares candidatos de pergunta e resposta ancorados em cada trecho e correspondentes a uma das quatro habilidades. Para dificultar a vida dos modelos testados, os autores adicionaram “ruído” inserindo entradas extras que parecem semelhantes em significado, mas que, na verdade, são irrelevantes, usando busca de similaridade avançada e filtros de sobreposição. Finalmente, uma verificação de qualidade em duas etapas garantiu rigor: outro modelo robusto julgou se cada resposta realmente seguia do contexto de suporte, e cinco especialistas com nível de doutorado revisaram manualmente milhares de itens, rejeitando qualquer um que fosse pouco claro, enganoso ou não totalmente suportado pela evidência.
O que os modelos de hoje acertam e erram
Com o SciCUEval em mãos, os autores avaliaram sistematicamente 18 modelos de linguagem de ponta, incluindo sistemas proprietários amplamente usados e modelos de código aberto tanto gerais quanto focados em ciência. Eles descobriram que modelos equipados com estratégias explícitas de raciocínio e com grande número de parâmetros tendiam a ter melhor desempenho, muitas vezes superando modelos científicos menores ou mais especializados. A maioria dos sistemas lidou razoavelmente bem com a tarefa básica de encontrar relevância e se saiu melhor com texto livre do que com tabelas densas ou dados em formato de grafo. Entretanto, quase todos apresentaram dificuldade em admitir quando faltava informação suficiente, frequentemente oferecendo respostas confiantes, mas sem fundamento. Modelos científicos especializados, apesar de terem sido treinados em material específico da área, frequentemente ficaram atrás dos modelos gerais mais fortes em raciocínio geral e no manuseio de múltiplas modalidades de dados.
O que isso significa para IAs científicas mais seguras
Para não-especialistas que observam a IA avançar em laboratórios, hospitais e no design de materiais, o SciCUEval oferece tanto um alerta quanto um caminho a seguir. O alerta é que os impressionantes modelos de linguagem atuais continuam suscetíveis à excesso de confiança, especialmente quando a evidência científica é incompleta ou dispersa entre formatos. O caminho a seguir é um benchmark transparente e desafiador que expõe essas fraquezas e ajuda desenvolvedores a medir progresso real. Ao dar à comunidade um teste aberto e compartilhado da compreensão de contexto científico, os autores buscam orientar os modelos futuros para não apenas soarem inteligentes sobre ciência, mas agirem como colaboradores cuidadosos e orientados por evidências.
Citação: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Palavras-chave: benchmark científico, grandes modelos de linguagem, compreensão de contexto, dados científicos multimodais, avaliação de IA