Clear Sky Science · fr
SciCUEval : un jeu de données complet pour évaluer la compréhension du contexte scientifique par les grands modèles de langage
Pourquoi des IA scientifiques plus intelligentes comptent
Les scientifiques commencent à s’appuyer sur les grands modèles de langage — la même famille d’outils derrière les chatbots populaires — pour lire des articles, parcourir des bases de données et même suggérer de nouvelles expériences. Mais l’information scientifique est dense, variée et souvent incomplète, et les modèles actuels peuvent paraître sûrs d’eux alors qu’ils se trompent. Cet article présente SciCUEval, un nouveau jeu de données public conçu pour tester rigoureusement dans quelle mesure ces modèles comprennent réellement le contexte scientifique, dans le but de rendre les futurs assistants IA plus fiables dans de vrais laboratoires et cliniques.
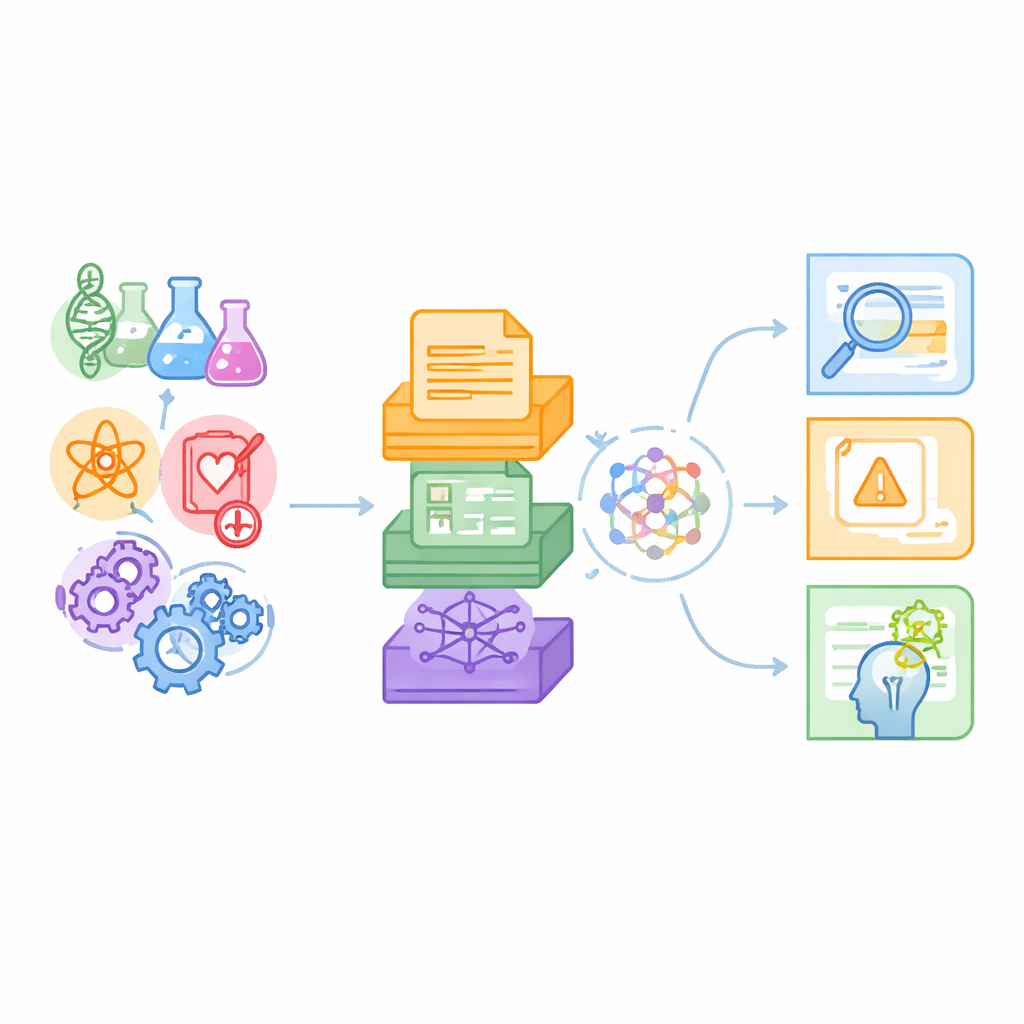
Un nouveau banc d’essai pour des machines versées en science
Les auteurs soutiennent que les benchmarks existants sondent principalement des tâches de langage courant ou des niches scientifiques uniques, comme le question–réponse en chimie, et s’appuient généralement uniquement sur du texte brut. La vraie science, en revanche, couvre de multiples disciplines et mêle des paragraphes d’articles à des tableaux de données et des cartes de relations complexes. SciCUEval a été conçu pour refléter cette réalité. Il regroupe dix sous-ensembles couvrant la biologie, la chimie, la physique, la biomédecine et la science des matériaux, chacun issu de sources fiables comme des prépublications arXiv, des collections internationales de données nucléaires, des bases de données de matériaux et des bases de connaissances biomédicales. Le résultat dépasse les 11 000 questions soigneusement construites qui testent ce que les modèles de langage comprennent réellement, plutôt que leur capacité à feindre la connaissance.
Rassembler texte, chiffres et réseaux
Une caractéristique clé de SciCUEval est son mélange de formats de données. Certaines questions sont étayées par du texte non structuré — extraits d’articles et protocoles expérimentaux. D’autres reposent sur des tableaux structurés listant, par exemple, des mesures nucléaires ou des propriétés de matériaux. D’autres encore utilisent des « graphes de connaissances », où des entités telles que gènes, médicaments ou maladies sont reliées par des liens typés. Chaque problème inclut la question, la bonne réponse, les éléments de soutien réellement pertinents et un contexte de fond plus large parsemé d’entrées supplémentaires potentiellement trompeuses. Les questions apparaissent sous plusieurs formes familières — réponses ouvertes, choix multiple, vrai ou faux et exercices à compléter — rendant le benchmark flexible pour de nombreux styles d’évaluation.
Quatre manières de sonder la compréhension scientifique
Pour dépasser la simple recherche de faits, le jeu de données s’organise autour de quatre compétences centrales dont les scientifiques ont couramment besoin et que les systèmes d’IA doivent apprendre à imiter. La première est la recherche d’information pertinente : un modèle peut-il se focaliser sur la ligne de tableau ou l’entrée de graphique cruciale qui répond réellement à la question, tout en ignorant des distractions ressemblantes ? La seconde est la capacité à reconnaître quand l’information manque ou est peu fiable, et à refuser explicitement de répondre plutôt que d’inventer. La troisième est la combinaison d’éléments provenant de sources multiples — par exemple relier un tableau de mesures à une description distincte des conditions expérimentales. Enfin, l’inférence sensible au contexte teste si un modèle peut tirer une conclusion logique qui n’est pas énoncée explicitement mais qui est clairement impliquée par les preuves fournies. Ensemble, ces compétences forment une grille structurée de ce que « comprendre » devrait signifier en contexte scientifique.
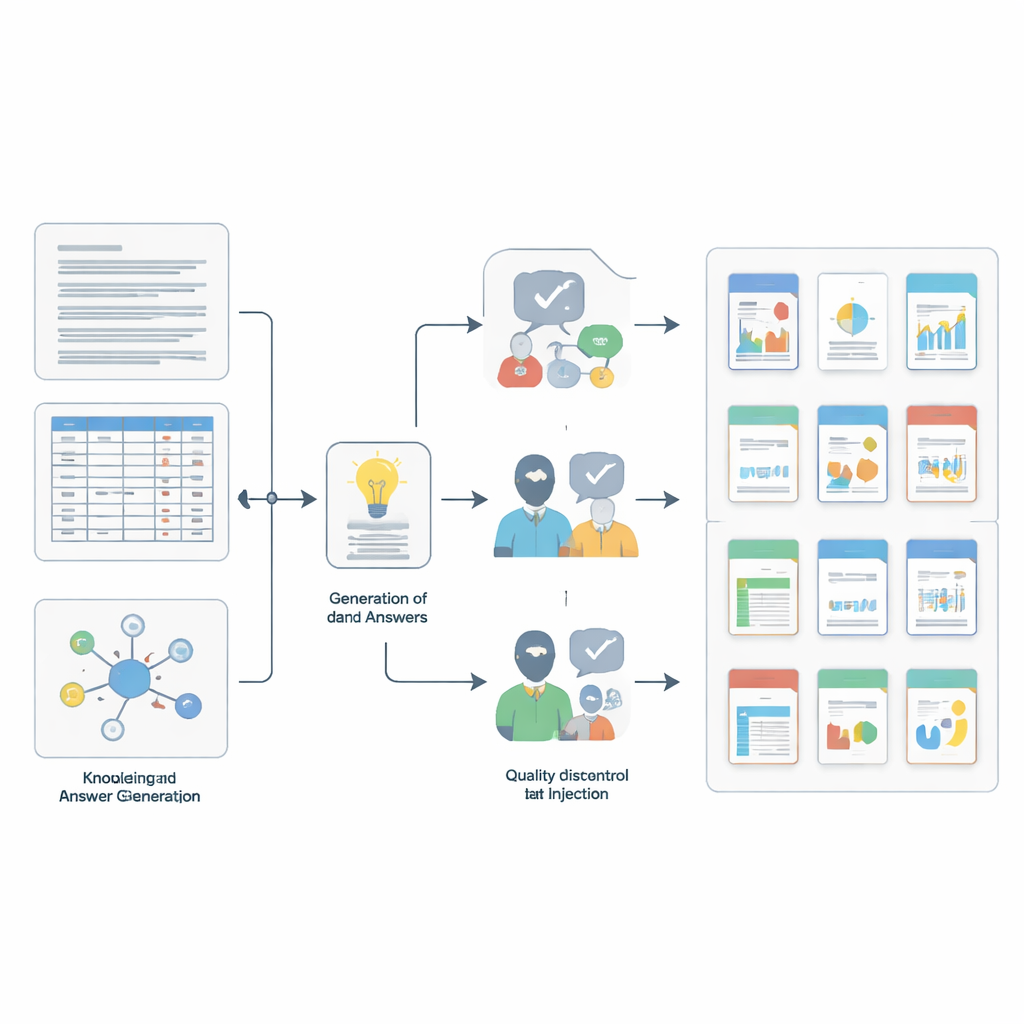
Comment les questions ont été construites et vérifiées
Construire un tel benchmark a nécessité son propre petit protocole scientifique. L’équipe a d’abord échantillonné de petits morceaux cohérents issus des collections sources — courts passages de texte, lignes de tableau individuelles ou ensembles d’entrées liées. Ils ont ensuite utilisé un modèle de langage puissant, guidé par des invites détaillées, pour rédiger des paires question–réponse candidates ancrées dans chaque extrait et correspondant à l’une des quatre compétences. Pour corser l’exercice pour les modèles évalués, les auteurs ont ajouté du « bruit » en insérant des entrées supplémentaires qui semblent sémantiquement proches mais sont en fait sans rapport, en utilisant des recherches de similarité avancées et des filtres de recouvrement. Enfin, une vérification de qualité en deux étapes a garanti la rigueur : un autre modèle robuste a jugé si chaque réponse découlait réellement du contexte de soutien, puis cinq experts au niveau doctorat ont manuellement examiné des milliers d’éléments, rejetant ceux qui étaient ambigus, trompeurs ou insuffisamment étayés par les preuves.
Ce que les modèles actuels réussissent et ratent
Avec SciCUEval en main, les auteurs ont évalué systématiquement 18 modèles de langage de premier plan, incluant des systèmes propriétaires largement utilisés et des modèles open source à usage général ou axés sur la science. Ils ont constaté que les modèles dotés de stratégies de raisonnement explicites et d’un grand nombre de paramètres avaient tendance à performer le mieux, dépassant souvent des modèles scientifiques plus petits ou plus spécialisés. La plupart des systèmes géraient raisonnablement bien la recherche de pertinence de base et s’en sortaient mieux sur du texte libre que sur des tableaux denses ou des données structurées en graphe. Cependant, presque tous peinaient à admettre l’insuffisance d’information, offrant fréquemment des réponses confiantes mais non fondées. Les modèles spécialisés en sciences, malgré un entraînement sur du matériel de domaine, accusaient souvent un retard par rapport aux modèles généraux les plus performants en raisonnement global et en gestion de modalités de données multiples.
Ce que cela signifie pour une IA scientifique plus sûre
Pour les non‑spécialistes qui voient l’IA s’implanter dans les laboratoires, les hôpitaux et la conception de matériaux, SciCUEval offre à la fois un avertissement et une voie à suivre. L’avertissement est que les modèles de langage impressionnants d’aujourd’hui restent enclins à la surconfiance, surtout lorsque les preuves scientifiques sont incomplètes ou dispersées entre plusieurs formats. La voie à suivre est un benchmark transparent et exigeant qui met en lumière ces faiblesses et aide les développeurs à mesurer le progrès réel. En donnant à la communauté un test ouvert et partagé de la compréhension du contexte scientifique, les auteurs visent à orienter les modèles futurs non seulement pour qu’ils paraissent érudits en science, mais pour qu’ils se comportent comme des collaborateurs prudents et attentifs aux preuves.
Citation: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Mots-clés: référence scientifique, grands modèles de langage, compréhension du contexte, données scientifiques multimodales, évaluation IA