Clear Sky Science · es
SciCUEval: Un conjunto de datos integral para evaluar la comprensión del contexto científico en modelos de lenguaje grandes
Por qué importan las IA científicas más inteligentes
Los científicos están empezando a apoyarse en modelos de lenguaje grandes—la misma familia de herramientas detrás de chatbots populares—para leer artículos, revisar bases de datos e incluso proponer nuevos experimentos. Pero la información científica es densa, variada y a menudo incompleta, y los modelos actuales pueden sonar seguros aunque estén equivocados. Este artículo presenta SciCUEval, un nuevo conjunto de datos público creado para evaluar rigurosamente cuánto entienden realmente estos modelos el contexto científico, con el objetivo de hacer que los futuros asistentes de IA sean más fiables en laboratorios y clínicas reales.
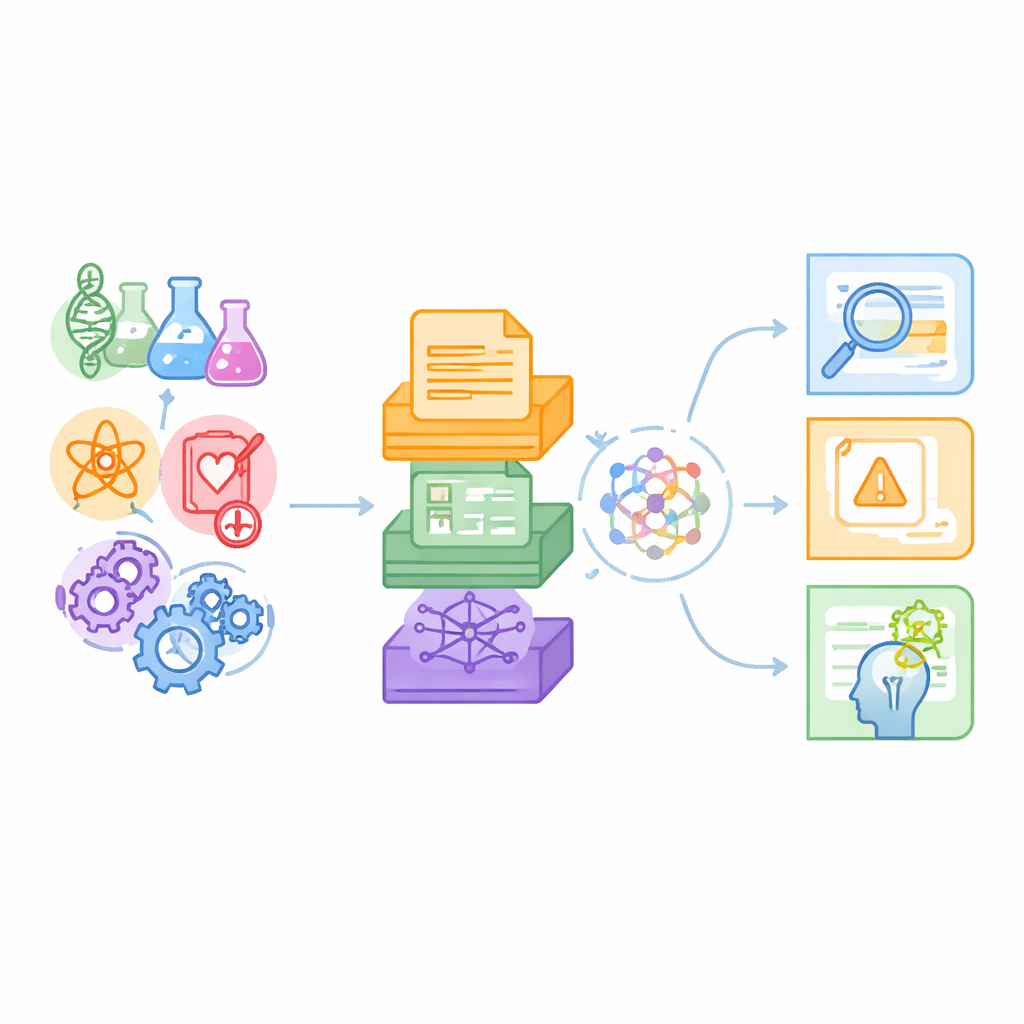
Un nuevo banco de pruebas para máquinas con sentido científico
Los autores sostienen que los puntos de referencia existentes suelen sondear tareas de lenguaje cotidiano o nichos científicos concretos, como preguntas de química, y generalmente se basan solo en texto plano. La ciencia real, en cambio, abarca múltiples disciplinas y combina párrafos de revistas con tablas de datos y complejos mapas de relaciones. SciCUEval está diseñado para reflejar esa realidad. Agrupa diez subconjuntos de datos que cubren biología, química, física, biomedicina y ciencia de materiales, cada uno extraído de fuentes de confianza como preprints de arXiv, colecciones internacionales de datos nucleares, bases de datos de materiales y bases de conocimiento biomédicas. El resultado son más de 11.000 preguntas cuidadosamente construidas que ponen a prueba lo que los modelos de lenguaje realmente entienden, en lugar de cuán bien pueden aparentarlo.
Reunir texto, números y redes
Una característica clave de SciCUEval es su mezcla de formatos de datos. Algunas preguntas se apoyan en texto no estructurado—fragmentos de artículos y protocolos experimentales. Otras se basan en tablas estructuradas que listan, por ejemplo, medidas nucleares o propiedades de materiales. Otras utilizan “grafos de conocimiento”, en los que entidades como genes, fármacos o enfermedades están conectadas por enlaces tipados. Cada problema incluye la pregunta, la respuesta correcta, las piezas de apoyo verdaderamente relevantes y un contexto de fondo más amplio salpicado de entradas adicionales que pueden confundir. Las preguntas aparecen en varias formas familiares—respuestas abiertas, opción múltiple, verdadero o falso y completar espacios—lo que hace que el benchmark sea flexible para diversos estilos de evaluación.
Cuatro maneras de sondear la comprensión científica
Para ir más allá de la simple búsqueda de hechos, el conjunto de datos se organiza en torno a cuatro habilidades centrales que los científicos necesitan rutinariamente y que los sistemas de IA deben aprender a imitar. La primera es encontrar información relevante: ¿puede un modelo localizar la fila de tabla o el punto de un gráfico que realmente responde la pregunta, ignorando distracciones similares? La segunda es reconocer cuando la información falta o es poco fiable, y negarse explícitamente a responder en lugar de alucinar. La tercera es combinar piezas de múltiples fuentes—por ejemplo, vincular una tabla de medidas con una descripción separada de las condiciones experimentales. Finalmente, la inferencia con conciencia del contexto prueba si un modelo puede extraer una conclusión lógica que no se expresa de forma explícita pero que está claramente implícita en la evidencia proporcionada. Juntas, estas habilidades forman una lista de verificación estructurada de lo que “entender” debería significar en entornos científicos.
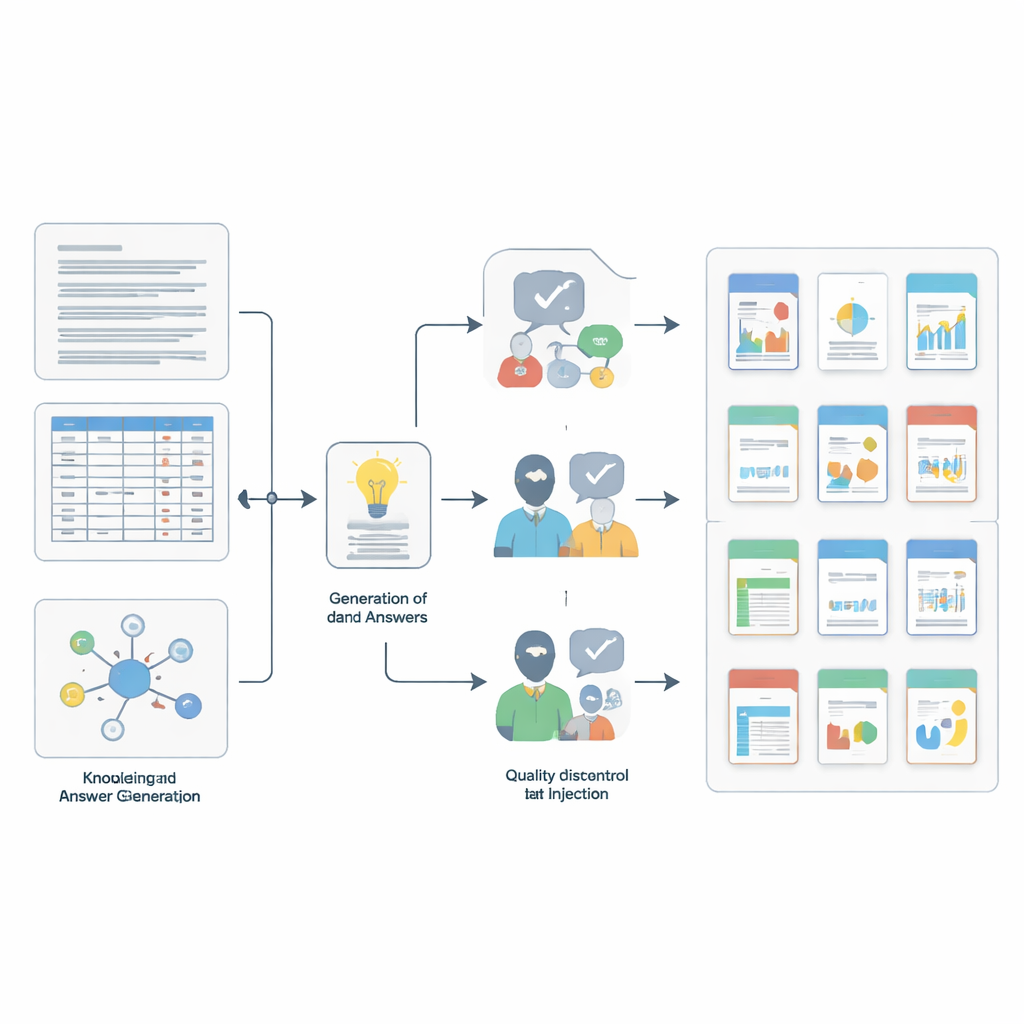
Cómo se construyeron y comprobaron las preguntas
Construir un benchmark así requirió su propio flujo de trabajo científico en miniatura. El equipo primero muestreó pequeños fragmentos coherentes de las colecciones de origen—pasajes de texto breves, filas individuales de tablas o conjuntos de entradas vinculadas. Luego utilizaron un potente modelo de lenguaje, guiado por instrucciones detalladas, para redactar pares de pregunta y respuesta candidatos basados en cada fragmento y asignados a una de las cuatro habilidades. Para complicar la tarea a los modelos evaluados, los autores añadieron “ruido” insertando entradas extra que parecen similares en significado pero que en realidad son irrelevantes, usando búsqueda avanzada por similitud y filtros de solapamiento. Finalmente, un control de calidad en dos etapas garantizó el rigor: otro modelo potente juzgó si cada respuesta realmente se derivaba del contexto de apoyo, y cinco expertos con nivel de doctorado revisaron manualmente miles de ítems, rechazando cualquiera que fuera poco claro, engañoso o que no estuviera completamente respaldado por la evidencia.
Qué aciertan y qué fallan los modelos actuales
Con SciCUEval en mano, los autores evaluaron sistemáticamente 18 modelos de lenguaje líderes, incluidos sistemas propietarios ampliamente usados y modelos de código abierto de propósito general y orientados a la ciencia. Encontraron que los modelos equipados con estrategias explícitas de razonamiento y con grandes cantidades de parámetros tendían a rendir mejor, superando a menudo a modelos científicos más pequeños o entrenados de forma más específica. La mayoría de los sistemas manejaron razonablemente bien la búsqueda básica de relevancia y lo hicieron mejor con texto libre que con tablas densas o datos estructurados en grafos. Sin embargo, casi todos tuvieron dificultades para admitir cuando carecían de información suficiente, ofreciendo con frecuencia respuestas seguras pero infundadas. Los modelos científicos especializados, a pesar de estar entrenados en material de campo específico, a menudo quedaron por detrás de los modelos generales más potentes en razonamiento global y en el manejo de múltiples modalidades de datos.
Qué significa esto para una IA científica más segura
Para los no especialistas que observan cómo la IA entra en laboratorios, hospitales y diseño de materiales, SciCUEval ofrece tanto una advertencia como una vía a seguir. La advertencia es que los modelos de lenguaje impresionantes de hoy siguen siendo propensos al exceso de confianza, especialmente cuando la evidencia científica es incompleta o está dispersa en distintos formatos. La vía a seguir es un benchmark transparente y desafiante que expone estas debilidades y ayuda a los desarrolladores a medir el progreso real. Al proporcionar a la comunidad una prueba compartida y abierta de la comprensión del contexto científico, los autores pretenden orientar a los modelos futuros no solo a sonar inteligentes sobre ciencia, sino a comportarse como colaboradores cuidadosos y guiados por la evidencia.
Cita: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Palabras clave: referencia científica, modelos de lenguaje grandes, comprensión del contexto, datos científicos multimodales, evaluación de IA