Clear Sky Science · de
SciCUEval: Ein umfassender Datensatz zur Bewertung des wissenschaftlichen Kontextverständnisses in großen Sprachmodellen
Warum klügere KI für die Wissenschaft wichtig ist
Wissenschaftlerinnen und Wissenschaftler verlassen sich zunehmend auf große Sprachmodelle — dieselbe Werkzeuggattung, die hinter populären Chatbots steht — um Artikel zu lesen, Datenbanken zu durchsuchen und sogar neue Experimente vorzuschlagen. Wissenschaftliche Informationen sind jedoch dicht, vielfältig und oft unvollständig, und heutige Modelle können selbstsicher klingen, obwohl sie falsch liegen. Dieser Artikel stellt SciCUEval vor, einen neuen öffentlichen Datensatz, der entwickelt wurde, um rigoros zu prüfen, wie gut solche Modelle wissenschaftlichen Kontext wirklich verstehen, mit dem Ziel, künftige KI-Helfer in echten Laboren und Kliniken zuverlässiger zu machen.
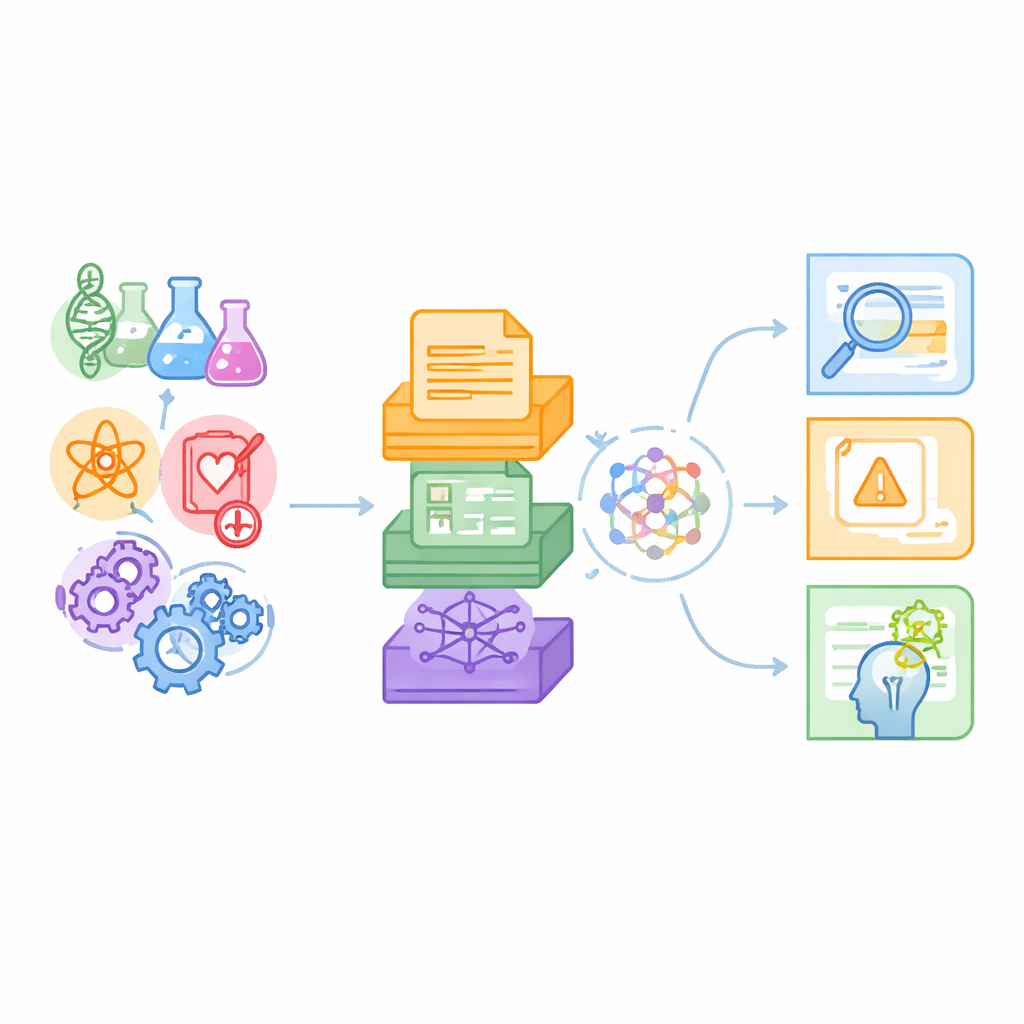
Eine neue Testumgebung für wissenschaftsaffine Maschinen
Die Autorinnen und Autoren argumentieren, dass bestehende Benchmarks meist Alltagssprachaufgaben oder einzelne wissenschaftliche Nischen abdecken, etwa Fragestellungen in der Chemie, und in der Regel nur auf Fließtext setzen. Echte Wissenschaft hingegen spannt viele Disziplinen auf und mischt Zeilen aus Fachartikeln mit Datentabellen und komplexen Beziehungsnetzen. SciCUEval ist darauf ausgelegt, diese Realität abzubilden. Es bündelt zehn Untermengen, die Biologie, Chemie, Physik, Biomedizin und Materialwissenschaften abdecken, jeweils entnommen aus vertrauenswürdigen Quellen wie arXiv-Preprints, internationalen Kernenergiedatenbeständen, Materialdatenbanken und biomedizinischen Wissensbasen. Das Ergebnis sind mehr als 11.000 sorgfältig erstellte Fragen, die prüfen, was Sprachmodelle tatsächlich verstehen, statt nur, wie gut sie bluffen.
Text, Zahlen und Netzwerke zusammenbringen
Ein zentrales Merkmal von SciCUEval ist die Mischung der Datenformate. Einige Fragen stützen sich auf unstrukturierte Texte — Ausschnitte aus Artikeln und experimentellen Protokollen. Andere beruhen auf strukturierten Tabellen, die etwa Kernmessungen oder Materialeigenschaften auflisten. Wieder andere nutzen „Wissensgraphen“, in denen Entitäten wie Gene, Arzneimittel oder Krankheiten durch typisierte Verbindungen verknüpft sind. Jedes Problem enthält die Frage, die richtige Antwort, die wirklich relevanten unterstützenden Teile und einen größeren Hintergrundkontext, der mit zusätzlichen, potenziell verwirrenden Einträgen durchsetzt ist. Fragen treten in mehreren vertrauten Formen auf — offene Antworten, Multiple Choice, Wahr/Falsch und Lückentexte — wodurch das Benchmark flexibel für verschiedene Evaluationsstile bleibt.
Vier Ansätze zur Prüfung wissenschaftlichen Verstehens
Um über einfaches Faktennachschlagen hinauszugehen, ist der Datensatz um vier Kernfähigkeiten strukturiert, die Wissenschaftler routinemäßig benötigen und die KI-Systeme nachahmen müssen. Erstens das Finden relevanter Informationen: Kann ein Modell genau die eine entscheidende Tabellenzeile oder den einen Grapheneintrag identifizieren, der die Frage beantwortet, und dabei ähnlich aussehende Ablenkungen ignorieren? Zweitens das Erkennen, wenn Informationen fehlen oder unzuverlässig sind, und das explizite Verweigern einer Antwort statt zu halluzinieren. Drittens das Kombinieren von Teilen aus mehreren Quellen — zum Beispiel das Verknüpfen einer Messungstabelle mit einer separaten Beschreibung der Versuchsbedingungen. Schließlich prüft kontextbewusste Inferenz, ob ein Modell eine logische Schlussfolgerung ziehen kann, die nicht ausdrücklich formuliert ist, aber klar aus den vorgelegten Belegen folgt. Zusammen bilden diese Fähigkeiten eine strukturierte Checkliste dessen, was „Verstehen" in wissenschaftlichen Kontexten bedeuten sollte.
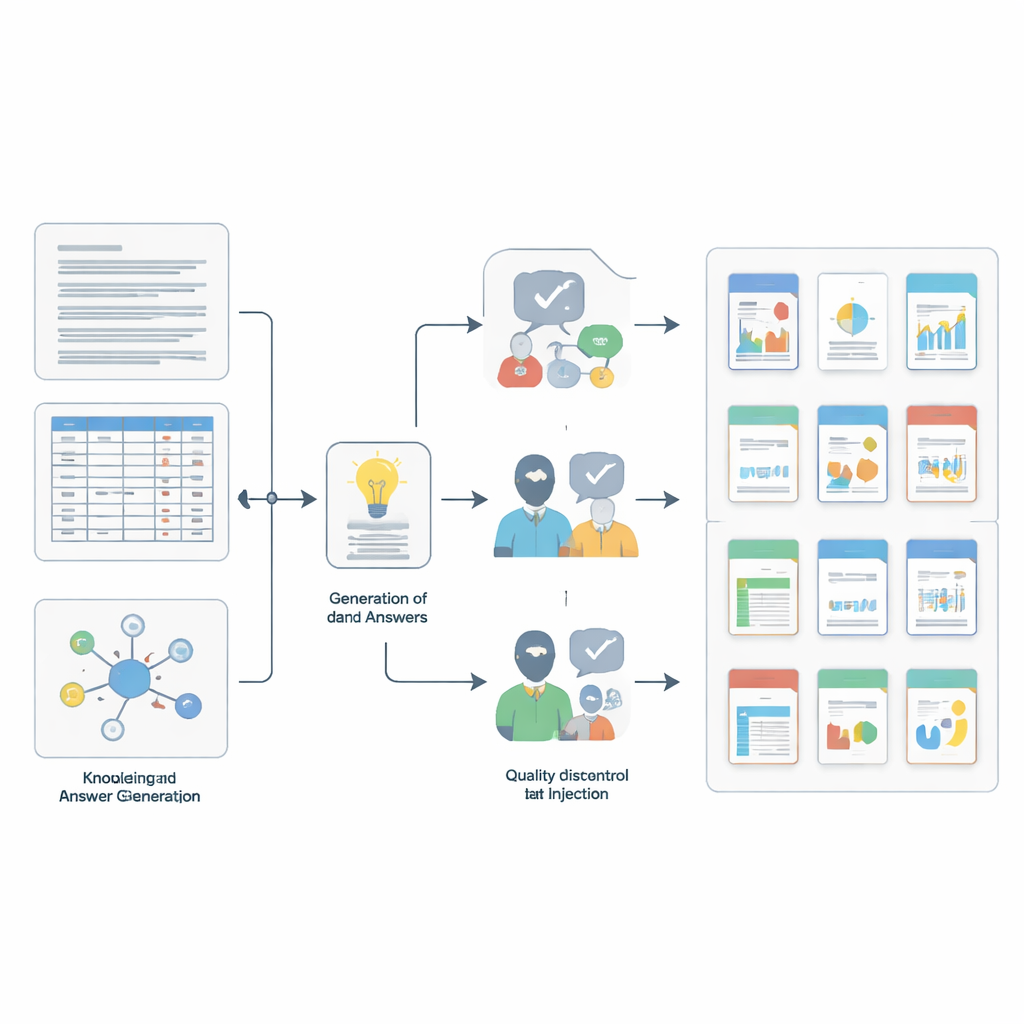
Wie die Fragen erstellt und überprüft wurden
Der Aufbau eines solchen Benchmarks erforderte einen eigenen Miniatur-Wissenschaftsworkflow. Das Team entnahm zunächst kleine, kohärente Ausschnitte aus den Quellsammlungen — kurze Textpassagen, einzelne Tabellenzeilen oder Mengen verknüpfter Einträge. Anschließend nutzten sie ein leistungsfähiges Sprachmodell, gesteuert durch detaillierte Prompts, um Kandidaten für Frage-Antwort-Paare zu entwerfen, die in jedem Ausschnitt verankert und einer der vier Fähigkeiten zugeordnet waren. Um es prüfenden Modellen schwerer zu machen, fügten die Autorinnen und Autoren „Rauschen" hinzu, indem sie zusätzliche Einträge einfügten, die in der Bedeutung ähnlich aussehen, tatsächlich aber irrelevant sind; hierfür wurden fortgeschrittene Ähnlichkeitssuchen und Überlappungsfilter verwendet. Schließlich sorgte eine zweistufige Qualitätskontrolle für Strenge: Ein weiteres starkes Modell beurteilte, ob jede Antwort wirklich aus dem unterstützenden Kontext folgte, und fünf promovierte Expertinnen und Experten überprüften dann manuell Tausende von Einträgen und lehnten alles ab, was unklar, irreführend oder nicht vollständig durch die Belege gestützt war.
Was heutige Modelle richtig und falsch machen
Mit SciCUEval evaluierten die Autorinnen und Autoren systematisch 18 führende Sprachmodelle, darunter weit verbreitete proprietäre Systeme sowie Open-Source-Modelle mit allgemeinem bzw. wissenschaftlichem Fokus. Sie fanden, dass Modelle mit expliziten Schlussfolgerungsstrategien und hoher Parameteranzahl tendenziell am besten abschnitten und oft kleinere oder enger trainierte wissenschaftliche Modelle übertrafen. Die meisten Systeme bewältigten grundlegende Relevanzsuche einigermaßen gut und schnitten bei Freitextaufgaben besser ab als bei dichten Tabellen oder graph-strukturierten Daten. Dennoch taten sich fast alle schwer damit, einzuräumen, wenn nicht genügend Informationen vorliegen, und lieferten häufig selbstsichere, aber unbegründete Antworten. Spezialisierte wissenschaftliche Modelle, obwohl sie auf fachspezifischem Material trainiert wurden, lagen im Gesamtreasoning und im Umgang mit mehreren Datenmodalitäten oft hinter den stärksten allgemeinen Modellen zurück.
Was das für eine sicherere wissenschaftliche KI bedeutet
Für Nichtfachleute, die verfolgen, wie KI in Labore, Krankenhäuser und Materialdesign vordringt, bietet SciCUEval sowohl eine Warnung als auch einen möglichen Weg nach vorn. Die Warnung lautet, dass heutige beeindruckende Sprachmodelle weiterhin zu Überkonfidenz neigen, insbesondere wenn wissenschaftliche Belege unvollständig sind oder über verschiedene Formate verstreut sind. Der Weg nach vorn ist ein transparentes, anspruchsvolles Benchmark, das diese Schwächen offenlegt und Entwicklerinnen und Entwicklern hilft, echten Fortschritt zu messen. Indem die Community ein gemeinsames, offenes Testinstrument für wissenschaftliches Kontextverständnis erhält, zielen die Autorinnen und Autoren darauf ab, künftige Modelle nicht nur so klingen zu lassen, als verstünden sie Wissenschaft, sondern als umsichtig und evidenzorientiert zusammenzuarbeiten.
Zitation: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Schlüsselwörter: wissenschaftliches Benchmark, große Sprachmodelle, Kontextverständnis, multimodale wissenschaftliche Daten, KI-Bewertung