Clear Sky Science · it
SciCUEval: un dataset completo per valutare la comprensione del contesto scientifico nei grandi modelli linguistici
Perché contano IA scientifiche più intelligenti
Gli scienziati stanno cominciando a fare affidamento sui grandi modelli linguistici—la stessa famiglia di strumenti alla base dei chatbot più diffusi—per leggere articoli, setacciare banche dati e perfino suggerire nuovi esperimenti. Ma l’informazione scientifica è densa, varia e spesso incompleta, e i modelli attuali possono apparire sicuri pur essendo errati. Questo articolo presenta SciCUEval, un nuovo dataset pubblico creato per testare rigorosamente quanto questi modelli comprendano davvero il contesto scientifico, con l’obiettivo di rendere i futuri assistenti IA più affidabili in laboratori e cliniche reali.
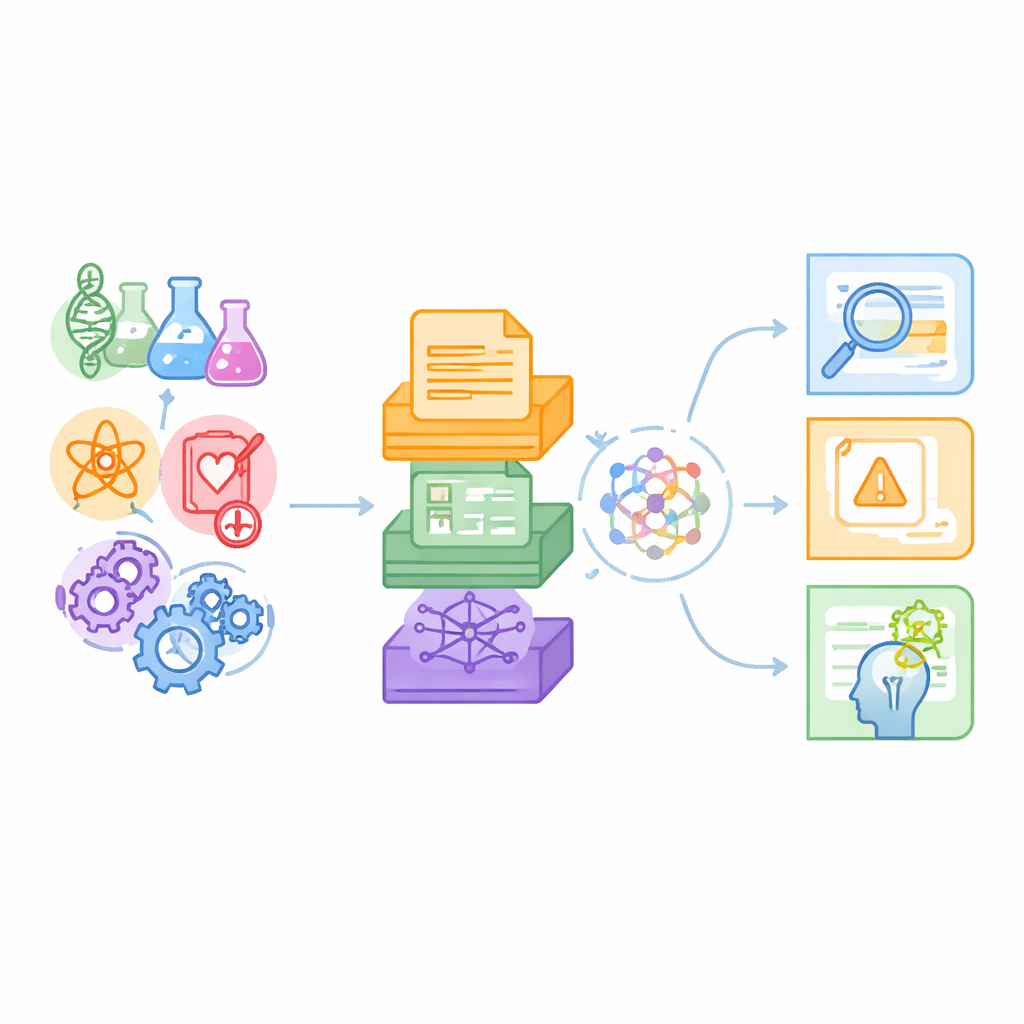
Un nuovo banco di prova per macchine esperte di scienza
Gli autori sostengono che i benchmark esistenti sondano per lo più compiti di linguaggio quotidiano o nicchie scientifiche singole, come il question answering in chimica, e si basano di solito solo su testo semplice. La scienza reale, al contrario, attraversa molte discipline e mescola paragrafi di riviste con tabelle di dati e mappe relazionali complesse. SciCUEval è progettato per rispecchiare questa realtà. Raggruppa dieci sotto-dataset che coprono biologia, chimica, fisica, biomedicina e scienza dei materiali, ciascuno tratto da fonti affidabili come preprint su arXiv, collezioni internazionali di dati nucleari, database dei materiali e basi di conoscenza biomediche. Il risultato sono oltre 11.000 domande costruite con cura che mettono alla prova ciò che i modelli linguistici comprendono realmente, piuttosto che quanto sanno bluffare.
Mettere insieme testo, numeri e reti
Una caratteristica chiave di SciCUEval è la sua mescolanza di formati di dati. Alcune domande sono supportate da testo non strutturato—estratti da articoli e protocolli sperimentali. Altre si basano su tabelle strutturate che elencano, per esempio, misure nucleari o proprietà dei materiali. Altre ancora utilizzano “knowledge graph”, in cui entità come geni, farmaci o malattie sono collegate da legami tipizzati. Ogni problema include la domanda, la risposta corretta, i pezzi di supporto realmente rilevanti e un contesto di fondo più ampio cosparso di voci aggiuntive potenzialmente fuorvianti. Le domande appaiono in diverse forme familiari—risposta aperta, scelta multipla, vero o falso e completamento—rendendo il benchmark flessibile per molti stili di valutazione.
Quattro modi per sondare la comprensione scientifica
Per andare oltre la semplice ricerca di fatti, il dataset è organizzato attorno a quattro competenze fondamentali che gli scienziati usano abitualmente e che i sistemi IA devono imparare a imitare. La prima è trovare informazioni rilevanti: un modello riesce a individuare la riga di tabella o la voce del grafico che risponde davvero alla domanda, ignorando le distrazioni simili? La seconda è riconoscere quando l’informazione è assente o inaffidabile, e rifiutarsi esplicitamente di rispondere invece di inventare risposte. La terza è combinare elementi provenienti da più fonti—per esempio collegare una tabella di misure a una descrizione separata delle condizioni sperimentali. Infine, l’inferenza contestuale testa se un modello può trarre una conclusione logica che non è esplicitamente dichiarata ma è chiaramente implicata dalle prove fornite. Insieme, queste abilità formano una checklist strutturata di cosa dovrebbe significare “comprendere” in contesti scientifici.
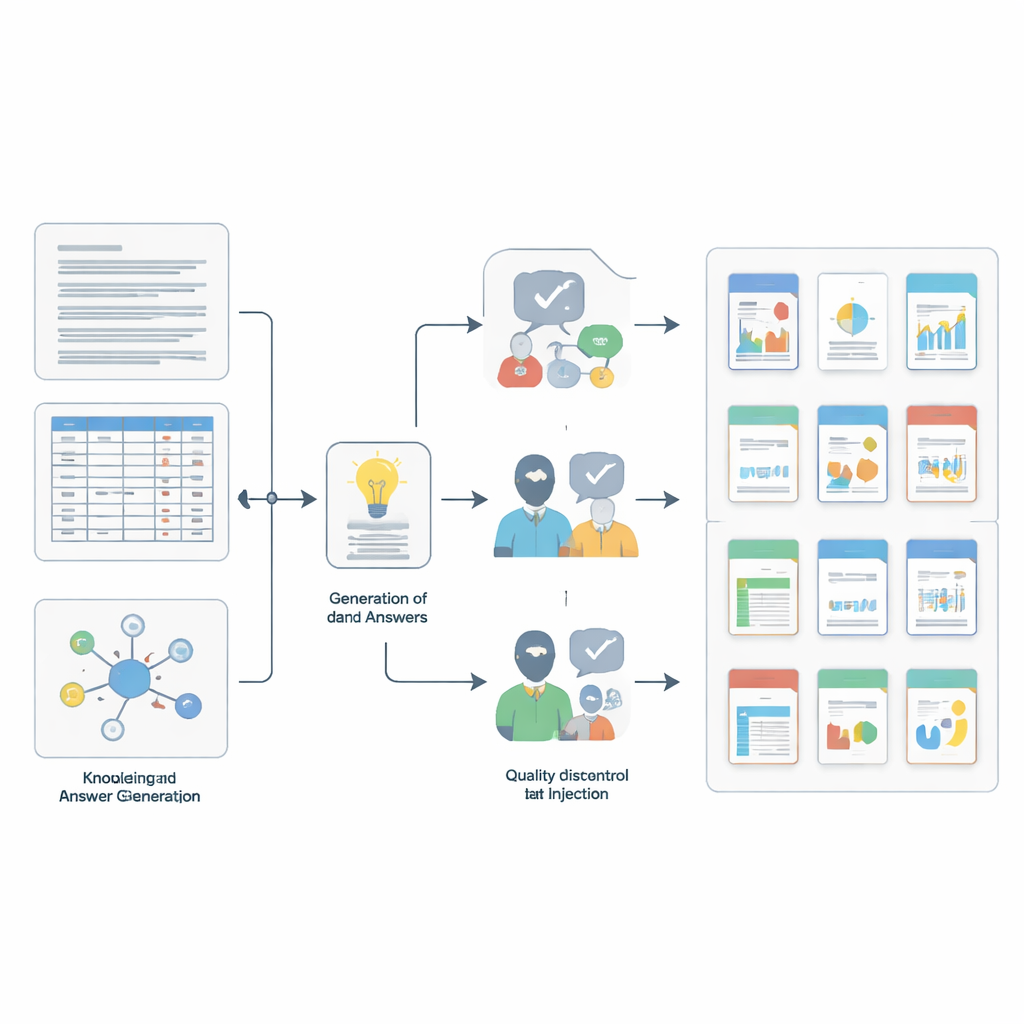
Come sono state costruite e verificate le domande
Costruire un benchmark del genere ha richiesto un proprio mini-workflow scientifico. Il team ha prima campionato piccoli blocchi coerenti dalle raccolte sorgente—brevi passaggi di testo, singole righe di tabella o insiemi di voci collegate. Poi ha usato un potente modello linguistico, guidato da prompt dettagliati, per redigere coppie candidato domanda-risposta ancorate a ciascun blocco e abbinate a una delle quattro competenze. Per rendere il compito più difficile per i modelli valutati, gli autori hanno aggiunto “rumore” inserendo voci extra che sembrano simili per significato ma sono in realtà irrilevanti, utilizzando ricerca di similarità avanzata e filtri di sovrapposizione. Infine, un controllo qualità in due fasi ha garantito rigore: un altro modello robusto ha giudicato se ogni risposta derivava davvero dal contesto di supporto, e poi cinque esperti di livello PhD hanno rivisto manualmente migliaia di elementi, respingendo quelli poco chiari, fuorvianti o non pienamente supportati dalle prove.
Cosa fanno bene e cosa sbagliano i modelli odierni
Con SciCUEval a disposizione, gli autori hanno valutato sistematicamente 18 modelli linguistici di punta, inclusi sistemi proprietari ampiamente usati e modelli open-source sia generali sia focalizzati sulla scienza. Hanno scoperto che i modelli dotati di strategie di ragionamento esplicite e di un gran numero di parametri tendevano a ottenere i risultati migliori, spesso superando modelli scientifici più piccoli o addestrati in modo più ristretto. La maggior parte dei sistemi gestiva ragionevolmente bene la ricerca di rilevanza di base e andava meglio con testo libero rispetto a tabelle dense o dati strutturati in grafi. Tuttavia, quasi tutti faticavano ad ammettere quando le informazioni erano insufficienti, offrendo frequentemente risposte sicure ma infondate. I modelli scientifici specializzati, nonostante l’addestramento su materiali di settore, spesso restavano indietro rispetto ai migliori modelli generali nel ragionamento complessivo e nella gestione di più modalità di dati.
Cosa significa questo per un’IA scientifica più sicura
Per i non specialisti che osservano l’ingresso dell’IA in laboratori, ospedali e nella progettazione dei materiali, SciCUEval offre sia un avvertimento sia una via da seguire. L’avvertimento è che i modelli linguistici oggi impressionanti restano inclini alla sovra-confidenza, specialmente quando le prove scientifiche sono incomplete o disperse su formati diversi. La via da seguire è un benchmark trasparente e impegnativo che espone queste debolezze e aiuta gli sviluppatori a misurare il progresso reale. Fornendo alla comunità un test condiviso e aperto sulla comprensione del contesto scientifico, gli autori mirano a indirizzare i futuri modelli non solo a sembrare esperti di scienza, ma a comportarsi come collaboratori cauti e attenti alle evidenze.
Citazione: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Parole chiave: benchmark scientifico, grandi modelli linguistici, comprensione del contesto, dati scientifici multimodali, valutazione IA