Clear Sky Science · en
SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
Why smarter science AIs matter
Scientists are beginning to lean on large language models—the same family of tools behind popular chatbots—to read papers, sift through databases, and even suggest new experiments. But scientific information is dense, varied, and often incomplete, and today’s models can sound confident while being wrong. This article introduces SciCUEval, a new public dataset created to rigorously test how well such models truly understand scientific context, with the goal of making future AI helpers more reliable in real labs and clinics.
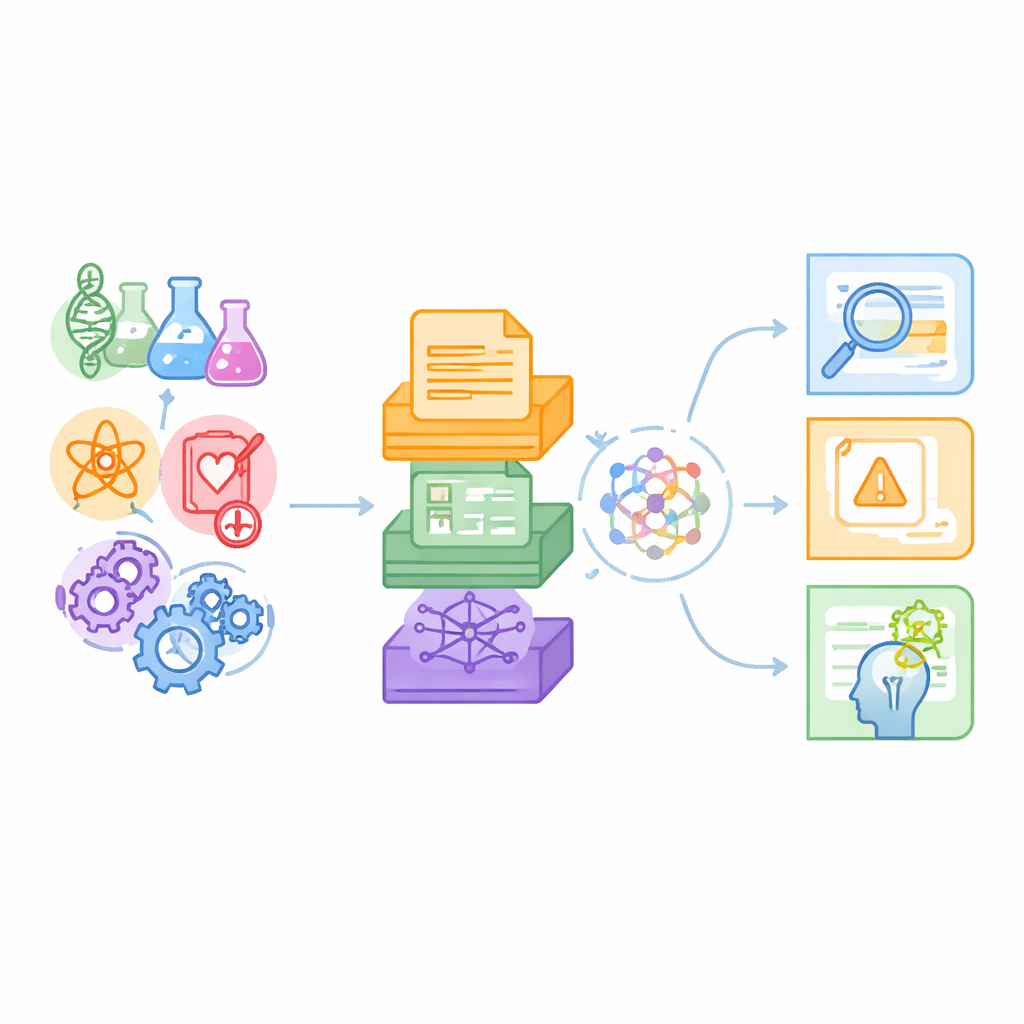
A new testbed for science-savvy machines
The authors argue that existing benchmarks mostly probe everyday language tasks or single scientific niches, such as chemistry question answering, and usually rely only on plain text. Real science, by contrast, spans many disciplines and mixes journal paragraphs with data tables and complex relationship maps. SciCUEval is designed to mirror this reality. It bundles ten sub-datasets covering biology, chemistry, physics, biomedicine, and materials science, each drawn from trusted sources like arXiv preprints, international nuclear data collections, materials databases, and biomedical knowledge bases. The result is more than 11,000 carefully built questions that stress-test what language models actually understand, rather than how well they bluff.
Bringing together text, numbers, and networks
A key feature of SciCUEval is its mix of data formats. Some questions are supported by unstructured text—snippets from papers and experimental protocols. Others rely on structured tables listing, for example, nuclear measurements or material properties. Still others use “knowledge graphs,” in which entities such as genes, drugs, or diseases are connected by typed links. Each problem includes the question, the correct answer, the truly relevant supporting pieces, and a larger background context salted with extra, potentially confusing entries. Questions appear in several familiar forms—open-ended answers, multiple choice, true-or-false, and fill-in-the-blank—making the benchmark flexible for many evaluation styles.
Four ways to probe scientific understanding
To go beyond simple fact lookup, the dataset is organized around four core skills that scientists routinely need and that AI systems must learn to mimic. First is finding relevant information: can a model home in on the one crucial table row or graph entry that actually answers the question, while ignoring look-alike distractions? Second is recognizing when the information is missing or unreliable, and explicitly refusing to answer instead of hallucinating. Third is combining pieces from multiple sources—for instance, linking a table of measurements to a separate description of experimental conditions. Finally, context-aware inference tests whether a model can draw a logical conclusion that is not stated outright but is clearly implied by the provided evidence. Together, these skills form a structured checklist for what “understanding” should mean in scientific settings.
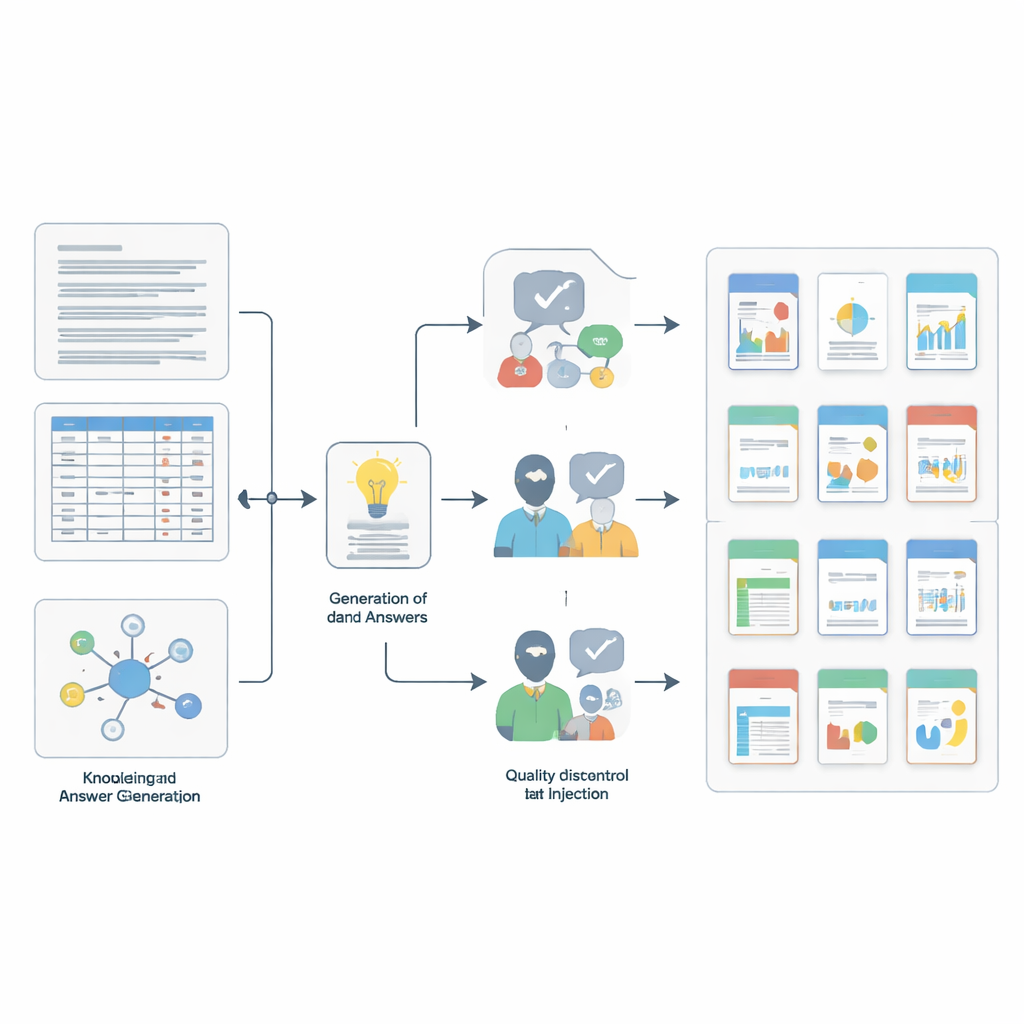
How the questions were built and checked
Constructing such a benchmark required its own miniature scientific workflow. The team first sampled small, coherent chunks from the source collections—short text passages, individual table rows, or sets of linked entries. They then used a powerful language model, guided by detailed prompts, to draft candidate question-and-answer pairs grounded in each chunk and matched to one of the four skills. To make life harder for test-taker models, the authors added “noise” by inserting extra entries that look similar in meaning but are in fact irrelevant, using advanced similarity search and overlap filters. Finally, a two-stage quality check ensured rigor: another strong model judged whether each answer truly followed from the supporting context, and five PhD-level experts then manually reviewed thousands of items, rejecting any that were unclear, misleading, or not fully supported by the evidence.
What today’s models get right and wrong
With SciCUEval in hand, the authors systematically evaluated 18 leading language models, including widely used proprietary systems and open-source general-purpose and science-focused models. They found that models equipped with explicit reasoning strategies and large parameter counts tended to perform best, often surpassing smaller or more narrowly trained scientific models. Most systems handled basic relevance-finding reasonably well and did better on free text than on dense tables or graph-structured data. However, nearly all struggled to admit when they lacked enough information, frequently offering confident but unfounded answers. Specialized scientific models, despite being trained on field-specific material, often lagged behind the strongest general models in overall reasoning and in handling multiple data modalities.
What this means for safer scientific AI
For non-specialists watching AI move into laboratories, hospitals, and materials design, SciCUEval offers both a warning and a path forward. The warning is that today’s impressive language models remain prone to overconfidence, especially when scientific evidence is incomplete or scattered across formats. The path forward is a transparent, challenging benchmark that exposes these weaknesses and helps developers measure real progress. By giving the community a shared, open test of scientific context understanding, the authors aim to steer future models toward not just sounding smart about science, but behaving like careful, evidence-minded collaborators.
Citation: Yu, J., Tang, Y., Feng, K. et al. SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models. Sci Data 13, 530 (2026). https://doi.org/10.1038/s41597-026-06594-9
Keywords: scientific benchmark, large language models, context understanding, multimodal scientific data, AI evaluation