Clear Sky Science · zh
混合神经–认知模型揭示记忆如何塑造人类的奖赏学习
为何过去的经验对日常选择很重要
每次你决定走哪条路线、买哪种零食或点击哪个网站时,你都在默默地从过去的奖赏与失落中学习。心理学家长期以来用简单的公式来描述这种学习,把过去的结果平均成每个选项的单一得分。本研究探问,这类简化的描述是否足以解释真实人类如何从奖赏中学习,并利用现代神经网络揭示记忆如何更丰富地影响我们的选择。
从简单得分到更丰富的记忆
经典的奖赏学习模型,被称为强化学习模型,假设每个可选项都有一个单一的运行价值,该价值在每次结果后略微更新。选了一个零食,得到70分,该零食的内部价值就会略微上升;得了10分,就会下降。这些模型影响深远,将行为与许多物种的大脑活动联系起来。然而,零散的发现暗示它们可能过于简单。人们会对某些特定的过去事件赋予特殊权重,似乎对所见奖赏的整体范围敏感,而且大脑信号并不总是与单一运行价值完全一致。
一次大型在线概率游戏
为了探讨这些问题,研究人员邀请了800多名在线志愿者进行数百次电脑游戏。在每一回合,玩家从四个彩色选项中选择一个,立即看到他们赢得了多少分。参与者并不知道,真实的收益会随着时间缓慢漂移,因此游戏开始时最优的选项之后可能变得平庸。在超过六十万次试验中,人们总体上学会偏好更有回报的选择,但他们在切换、连胜/连败模式和探索行为方面的详细模式包含了比简单模型所能捕捉的更多结构。 
将可解读模型与神经网络相结合
团队比较了若干种描述此类行为的方法。一端是经过精心调节的传统模型,它用少量数值来跟踪选项价值以及重复或切换行为的简单倾向。另一端是灵活的递归神经网络,这是一种可以在内部状态中存储丰富过去信息的人造“脑”,但通常难以解释。如预期,神经网络在预测人们选择方面远胜经典模型。关键步骤是构建混合模型:保留经典方法的透明结构,但用小型神经网络替换其中的某些部分,这些小网络理论上可以学到任何与数据相符的规则。
发现隐藏的记忆状态
第一批混合模型允许对选项价值进行更灵活的更新,并对未被选择选项的上下文敏感,但这些改进仍不及完整的神经网络。决定性的进展来自一个称为Memory-ANN的模型。在这里,系统保留了独立的记忆变量,用以存储过去奖赏与行为的丰富摘要,这些与直接驱动选择的简单变量分开。这些记忆变量由模型内部的紧凑递归网络实现。拟合数据后,Memory-ANN在可解释性的同时达到了不透明神经网络的预测能力。分析显示,它的记忆在多个时间尺度上跟踪近期和长期的奖赏历史,并调整新奖赏影响未来选择的强度。 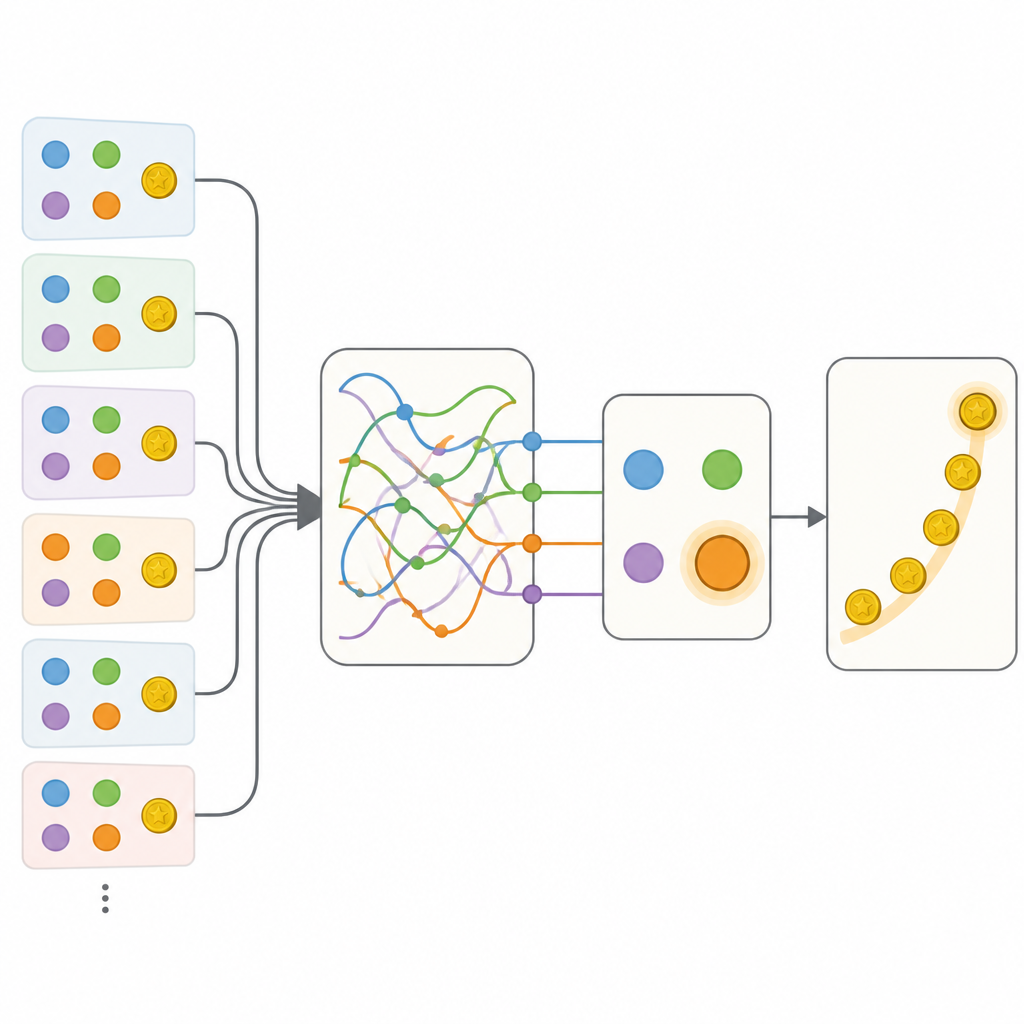
这对我们如何从奖赏中学习的意义
这些发现表明,人类的奖赏学习不能仅仅用对每个选项缓慢调整的单一得分来完全描述。相反,我们的大脑似乎维持着更丰富的内部记录,记下何时发生了什么,并利用这些记录来调整我们对新胜利与失败的反应强度。这项工作表明,将经典认知理论与神经网络结合可以揭示这种隐藏结构,既能拟合大规模数据集,又能阐明指导日常决策的心理过程。
引用: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
关键词: 奖赏学习, 人类决策, 记忆, 强化学习模型, 递归神经网络