Clear Sky Science · es
Modelos híbridos neurales–cognitivos revelan cómo la memoria moldea el aprendizaje por recompensa humano
Por qué importan las experiencias pasadas para las decisiones cotidianas
Cada vez que decides qué ruta conducir, qué snack comprar o en qué sitio web hacer clic, aprendes silenciosamente de recompensas y decepciones pasadas. Los psicólogos han descrito durante mucho tiempo este aprendizaje con fórmulas sencillas que promedian resultados pasados en una única puntuación para cada opción. Este estudio plantea si esas cuentas simplificadas son suficientes para explicar cómo la gente real aprende de las recompensas y usa redes neuronales modernas para revelar una imagen más rica de cómo la memoria influye en nuestras elecciones.
De puntuaciones simples a memorias más ricas
Los modelos clásicos de aprendizaje por recompensa, conocidos como modelos de aprendizaje por refuerzo, asumen que a cada opción escogible se le asigna un único valor acumulado que se actualiza un poco después de cada resultado. Eliges un snack, obtienes 70 puntos y el valor interno para ese snack sube; obtienes 10 puntos y baja. Estos modelos han sido muy influyentes, vinculando comportamiento y actividad cerebral en muchas especies. Sin embargo, hallazgos dispersos sugieren que pueden ser demasiado simples. Las personas pueden dar un peso especial a eventos pasados concretos, parecer sensibles al rango general de recompensas que han visto y mostrar señales cerebrales que no encajan bien con un único valor acumulado.
Un gran juego de azar en línea
Para explorar estas cuestiones, los investigadores pidieron a más de 800 voluntarios en línea que jugaran un juego por ordenador cientos de veces. En cada prueba, los participantes elegían una de cuatro opciones coloreadas y veían inmediatamente cuántos puntos habían ganado. Sin saberlo, las verdaderas recompensas fluctuaban lentamente con el tiempo, de modo que la mejor opción al inicio podía volverse mediocre más adelante. A lo largo de más de seiscientos mil ensayos, la gente en general aprendió a favorecer las opciones más recompensantes, pero sus patrones detallados de cambio, rachas y exploración contenían mucha más estructura de la que los modelos simples podían captar. 
Combinando modelos legibles con redes neuronales
El equipo comparó varias maneras de describir este comportamiento. En un extremo estaba un modelo tradicional cuidadosamente ajustado que usaba un puñado de números para seguir los valores de las opciones y una tendencia simple a repetir o cambiar acciones. En el otro extremo estaba una red neuronal recurrente flexible, una especie de cerebro artificial que puede almacenar información rica sobre el pasado en su estado interno pero que normalmente es difícil de interpretar. Como era de esperar, la red neuronal predijo las elecciones de las personas mucho mejor que el modelo clásico. El paso clave fue entonces construir modelos híbridos que conservaran la estructura transparente del enfoque clásico, pero reemplazaran piezas individuales con pequeñas redes neuronales que, en principio, pudieran aprender cualquier regla que ajustara a los datos.
Descubriendo estados de memoria ocultos
Los primeros híbridos permitieron una actualización más flexible de los valores de las opciones y sensibilidad al contexto de las opciones no elegidas, pero estas adiciones aún se quedaban cortas frente a la red neuronal completa. El avance decisivo vino con un modelo llamado Memory-ANN. Aquí, el sistema mantenía variables de memoria distintas que almacenaban un resumen rico de recompensas y acciones pasadas, separado de las variables más simples que guiaban directamente la elección. Estas variables de memoria se implementaron con redes recurrentes compactas dentro del modelo. Cuando se ajustó a los datos, Memory-ANN igualó el poder predictivo de la red neuronal opaca a la vez que seguía siendo interpretable. El análisis mostró que su memoria seguía tanto el historial de recompensas reciente como el de largo plazo en múltiples escalas temporales, y ajustaba qué tan fuertemente las recompensas nuevas influían en las elecciones futuras. 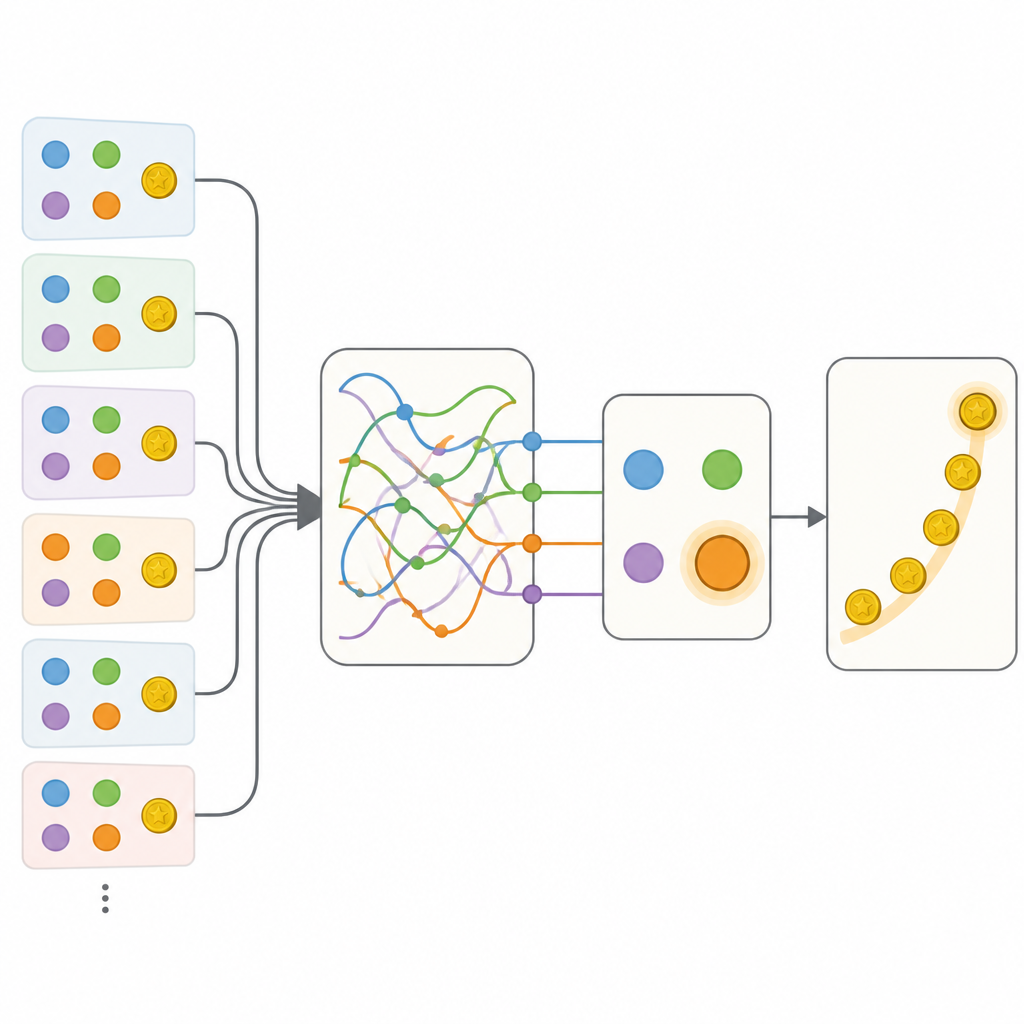
Qué significa esto para cómo aprendemos de las recompensas
Los hallazgos sugieren que el aprendizaje por recompensa humano no puede describirse completamente como el ajuste lento de una única puntuación para cada opción. En su lugar, parece que nuestros cerebros mantienen registros internos más ricos de qué pasó y cuándo, y usan esos registros para afinar qué tan fuerte reaccionamos a nuevas ganancias y pérdidas. El trabajo muestra que combinar teorías cognitivas clásicas con redes neuronales puede revelar esta estructura oculta, ofreciendo modelos que tanto ajustan grandes conjuntos de datos como arrojan luz sobre los procesos mentales que guían las decisiones cotidianas.
Cita: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Palabras clave: aprendizaje por recompensa, toma de decisiones humana, memoria, modelos de aprendizaje por refuerzo, redes neuronales recurrentes