Clear Sky Science · it
Modelli ibridi neurali–cognitivi rivelano come la memoria modella l’apprendimento da ricompense umano
Perché le esperienze passate contano nelle scelte di tutti i giorni
Ogni volta che decidi quale strada percorrere, quale snack comprare o su quale sito web cliccare, stai silenziosamente apprendendo da ricompense e delusioni passate. Gli psicologi hanno a lungo descritto questo apprendimento con formule semplici che sintetizzano gli esiti passati in un unico punteggio per ciascuna opzione. Questo studio indaga se tali descrizioni semplificate siano sufficienti a spiegare come le persone imparano realmente dalle ricompense e usa moderne reti neurali per svelare un quadro più ricco di come la memoria influenzi le nostre scelte.
Dai punteggi semplici a memorie più ricche
I modelli classici di apprendimento da ricompense, noti come modelli di apprendimento per rinforzo, presumono che ogni opzione selezionabile sia contrassegnata da un singolo valore correntemente aggiornato dopo ogni esito. Scegli uno snack, ottieni 70 punti e il valore interno di quello snack aumenta leggermente; ottieni 10 punti e scende. Questi modelli sono stati molto influenti, collegando comportamento e attività cerebrale in molte specie. Tuttavia risultati sparsi suggeriscono che possano essere troppo semplici. Le persone possono attribuire peso particolare a eventi passati specifici, sembrano sensibili all’intervallo complessivo delle ricompense osservate e mostrano segnali cerebrali che non si conciliano facilmente con un singolo valore corrente.
Un grande gioco d’azzardo online
Per esplorare queste questioni, i ricercatori hanno chiesto a oltre 800 volontari online di giocare a un gioco al computer per centinaia di volte. In ogni prova, i giocatori sceglievano una tra quattro opzioni colorate e vedevano immediatamente quanti punti avevano guadagnato. A loro insaputa, i ritorni veri scivolavano lentamente nel tempo, così che l’opzione migliore all’inizio di una partita poteva diventare mediocre in seguito. Su più di seicentomila prove, le persone in generale imparavano a favorire le scelte più remunerative, ma i loro modelli dettagliati di cambiamento, sequenze e esplorazione contenevano molta più struttura di quella che i modelli semplici riuscivano a catturare. 
Fondere modelli interpretabili con reti neurali
Il team ha confrontato diversi modi di descrivere questo comportamento. A un estremo c’era un modello tradizionale accuratamente messo a punto che utilizzava poche quantità per tracciare i valori delle opzioni e una semplice tendenza a ripetere o cambiare azione. All’altro estremo c’era una flessibile rete neurale ricorrente, una specie di cervello artificiale che può immagazzinare informazioni ricche sul passato nel suo stato interno ma è di solito difficile da interpretare. Come previsto, la rete neurale ha predetto le scelte delle persone molto meglio del modello classico. Il passo chiave è stato quindi costruire modelli ibridi che mantenessero la struttura trasparente dell’approccio classico, ma sostituissero singoli elementi con piccole reti neurali che potessero, in principio, apprendere qualsiasi regola coerente con i dati.
Scoprire stati di memoria nascosti
I primi ibridi consentivano aggiornamenti più flessibili dei valori delle opzioni e sensibilità al contesto delle opzioni non scelte, ma anche questi miglioramenti non bastavano a raggiungere la rete neurale completa. Il progresso decisivo è arrivato con un modello chiamato Memory-ANN. Qui, il sistema manteneva variabili di memoria distinte che conservavano un ricco riassunto delle ricompense e delle azioni passate, separate dalle variabili più semplici che guidavano direttamente la scelta. Queste variabili di memoria erano implementate con compatte reti ricorrenti all’interno del modello. Una volta adattato ai dati, Memory-ANN eguagliava il potere predittivo della rete opaca restando interpretabile. L’analisi ha mostrato che la sua memoria tracciava sia la storia delle ricompense recente sia a lungo termine su molte scale temporali e regolava quanto fortemente le nuove ricompense influenzassero le scelte future. 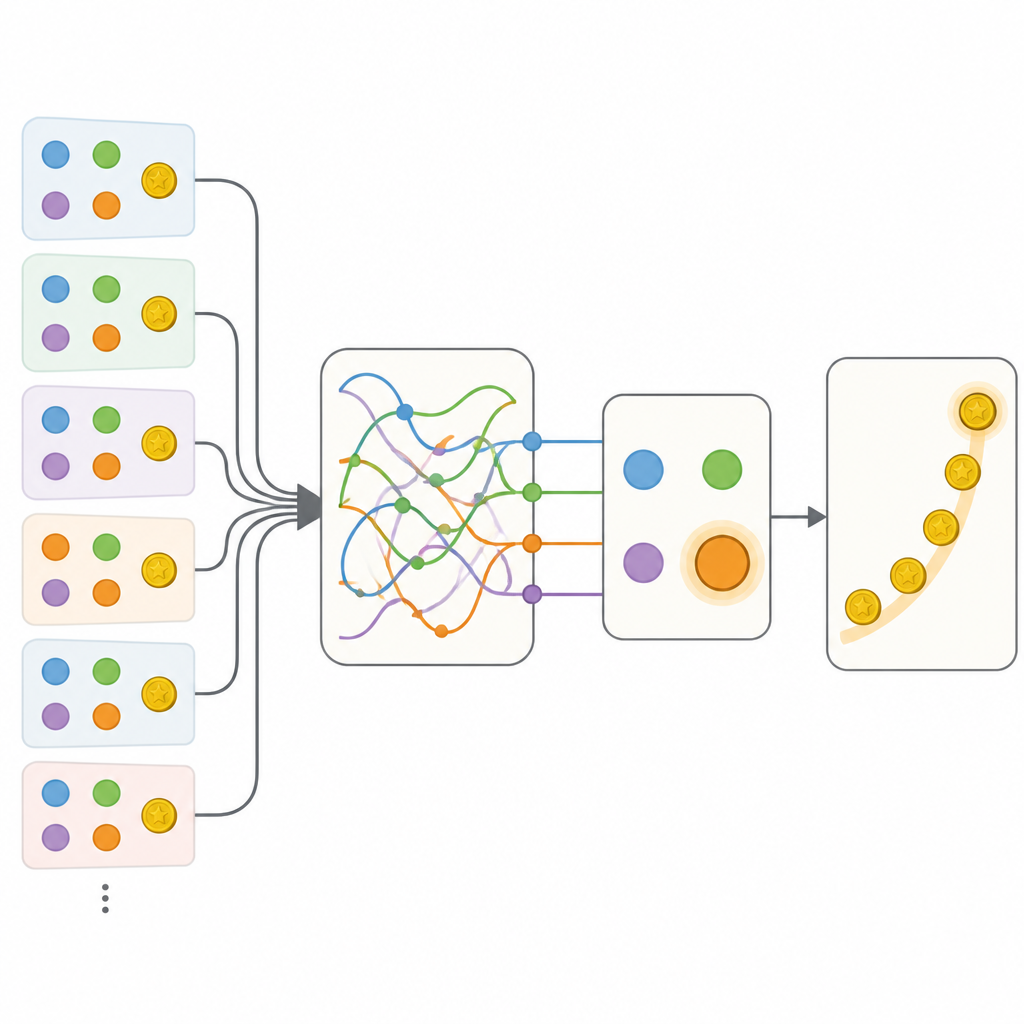
Cosa significa per il modo in cui apprendiamo dalle ricompense
I risultati suggeriscono che l’apprendimento umano dalle ricompense non può essere descritto pienamente come l’aggiustamento lento di un singolo punteggio per ogni opzione. Piuttosto, i nostri cervelli sembrano mantenere registrazioni interne più ricche di ciò che è avvenuto e quando, e usano questi archivi per modulare quanto intensamente reagiamo a nuove vincite e perdite. Il lavoro mostra che combinare teorie cognitive classiche con reti neurali può rivelare questa struttura nascosta, offrendo modelli che si adattano a grandi insiemi di dati e fanno luce sui processi mentali che guidano le decisioni quotidiane.
Citazione: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Parole chiave: apprendimento da ricompense, presa di decisione umana, memoria, modelli di apprendimento per rinforzo, reti neurali ricorrenti