Clear Sky Science · nl
Hybride neurale–cognitieve modellen onthullen hoe geheugen het menselijke beloningsleren vormt
Waarom eerdere ervaringen van belang zijn voor dagelijkse keuzes
Elke keer dat je besluit welke route je neemt, welke snack je koopt of op welke website je klikt, leer je stilletjes van eerdere beloningen en teleurstellingen. Psychologen beschrijven dit leren al lang met eenvoudige formules die eerdere uitkomsten middelen tot één enkele score per optie. Deze studie onderzoekt of zulke uitgeklede verklaringen voldoende zijn om te verklaren hoe echte mensen daadwerkelijk leren van beloningen, en gebruikt moderne neurale netwerken om een rijker beeld te onthullen van hoe geheugen onze keuzes vormt.
Van eenvoudige scores naar rijkere herinneringen
Klassieke modellen van beloningsleren, bekend als versterkingsleer-modellen, veronderstellen dat elke optie die je kunt kiezen is gemarkeerd met een enkele lopende waarde die na elke uitkomst een beetje wordt bijgewerkt. Kies een snack, ontvang 70 punten en de interne waarde voor die snack kruipt omhoog; krijg je 10 punten, dan glijdt die omlaag. Deze modellen zijn zeer invloedrijk geweest en leggen gedrag en hersenactiviteit bij vele soorten vast. Toch wijzen verspreide bevindingen erop dat ze mogelijk te eenvoudig zijn. Mensen kunnen bepaalde gebeurtenissen uit het verleden extra gewicht geven, lijken gevoelig voor het algemene bereik van beloningen dat ze hebben gezien, en tonen hersensignalen die niet netjes overeenkomen met één enkele lopende waarde.
Een groot online kansspel
Om deze kwesties te onderzoeken vroegen de onderzoekers meer dan 800 online vrijwilligers honderden keren een computergame te spelen. Bij elke trial kozen spelers een van vier gekleurde opties en zagen meteen hoeveel punten ze hadden gewonnen. Zonder dat ze het wisten, dreven de werkelijke opbrengsten langzaam in de tijd, zodat de beste optie bij het begin van een spel later middelmatig kon zijn. Over meer dan zeshonderdduizend trials leerden mensen over het algemeen om de meer lonende keuzes te prefereren, maar hun gedetailleerde patronen van wisselen, reeksen en verkenning bevatten veel meer structuur dan eenvoudige modellen konden vangen. 
Het mengen van menselijk-leesbare modellen met neurale netwerken
Het team vergeleek verschillende manieren om dit gedrag te beschrijven. Aan de ene kant stond een zorgvuldig afgestemd traditioneel model dat een handvol getallen gebruikte om optiewaarden bij te houden en een eenvoudige neiging om acties te herhalen of te wisselen. Aan de andere kant stond een flexibel rekurrent neuraal netwerk, een soort kunstmatig brein dat rijke informatie over het verleden in zijn interne staat kan opslaan maar doorgaans moeilijk te interpreteren is. Zoals verwacht voorspelde het neurale netwerk de keuzes van mensen veel beter dan het klassieke model. De sleutelstap was vervolgens het bouwen van hybride modellen die de transparante structuur van de klassieke benadering behielden, maar individuele onderdelen vervingen door kleine neurale netwerken die in principe elke regel konden leren die bij de gegevens paste.
Het ontdekken van verborgen geheugenstaten
De eerste hybriden maakten flexibeler bijwerken van optiewaarden mogelijk en gevoeligheid voor de context van niet-gekozen opties, maar deze aanvullingen kwamen nog steeds tekort vergeleken met het volledige neurale netwerk. De beslissende vooruitgang kwam met een model genaamd Memory-ANN. Hier hield het systeem afzonderlijke geheugenvariabelen aan die een rijke samenvatting van eerdere beloningen en acties opsloegen, los van de eenvoudigere variabelen die direct de keuze aanstuurden. Deze geheugenvariabelen werden geïmplementeerd met compacte rekurrente netwerken binnen het model. Wanneer passend gemaakt op de data, evenaarde Memory-ANN de voorspellende kracht van het ondoorzichtige neurale netwerk terwijl het interpreteerbaar bleef. Analyse toonde dat zijn geheugen zowel recente als langetermijn beloningsgeschiedenis op meerdere tijdschalen bijhield en hoe sterk nieuwe beloningen toekomstige keuzes beïnvloedden aanpaste. 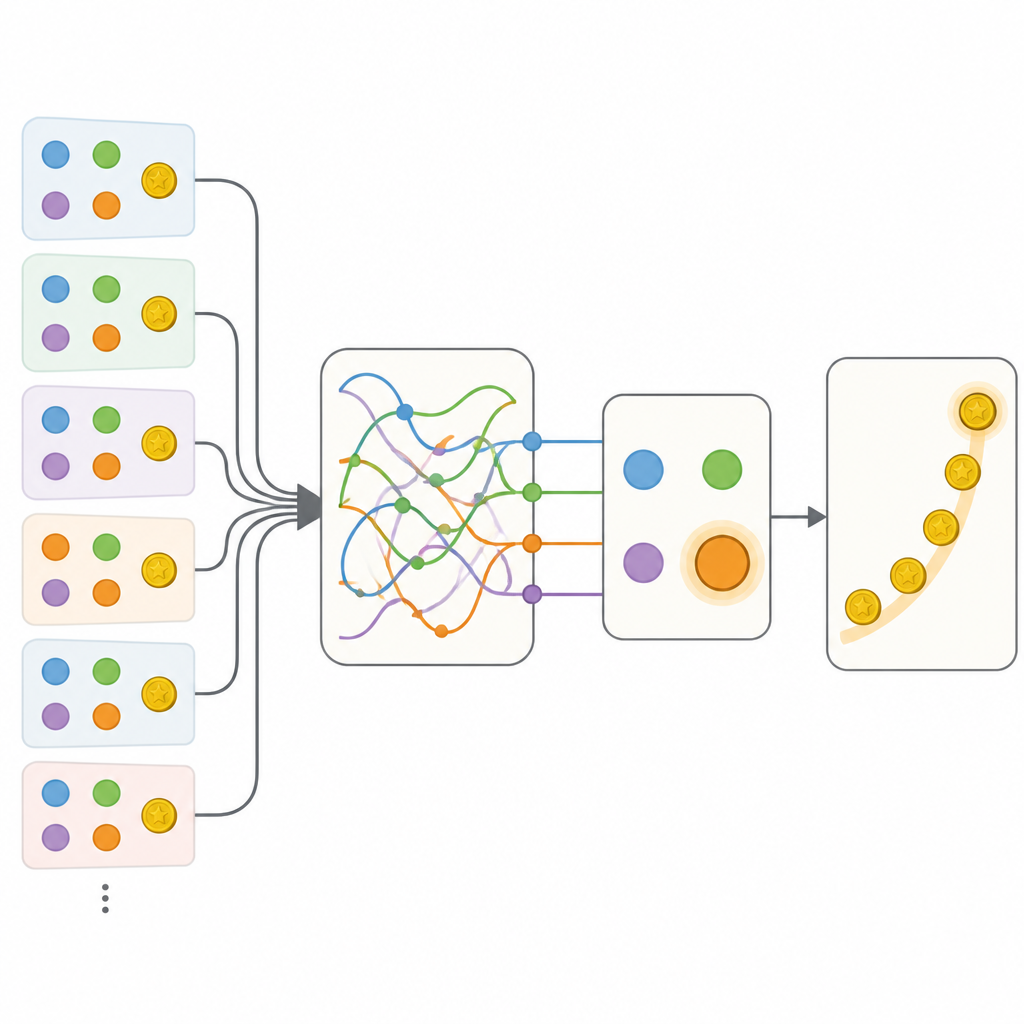
Wat dit betekent voor hoe we leren van beloningen
De bevindingen suggereren dat menselijk beloningsleren niet volledig kan worden beschreven als het langzaam bijstellen van één enkele score voor elke optie. In plaats daarvan lijken onze hersenen rijkere interne registers bij te houden van wat er wanneer gebeurde, en gebruiken ze die registers om af te stemmen hoe sterk we reageren op nieuwe overwinningen en verliezen. Het werk laat zien dat het combineren van klassieke cognitieve theorieën met neurale netwerken deze verborgen structuur kan onthullen, en modellen biedt die zowel grote datasets passen als inzicht geven in de mentale processen die dagelijkse beslissingen sturen.
Bronvermelding: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Trefwoorden: beloningsleren, menselijke besluitvorming, geheugen, versterkingsleer modellen, rekurrente neurale netwerken