Clear Sky Science · ja
ハイブリッド神経–認知モデルが示す、記憶が人間の報酬学習を形作る仕組み
なぜ過去の経験が日常の選択に重要なのか
どの道を走るか、どのおやつを買うか、どのウェブサイトをクリックするかを決めるたびに、私たちは静かに過去の報酬や失望から学んでいます。心理学者たちは長く、過去の結果を平均化して各選択肢にひとつのスコアを割り当てるような単純な式でこの学習を記述してきました。本研究は、そうした簡略化した説明が実際の人々の報酬学習を十分に説明できるかを問うもので、現代のニューラルネットワークを用いて記憶が選択に与えるより豊かな像を明らかにします。
単純なスコアからより豊かな記憶へ
報酬学習の古典的モデル、いわゆる強化学習モデルは、選べる各選択肢にひとつの連続的な価値が付与され、各結果の後にその価値が少しずつ更新されると仮定します。おやつを選んで70点を得ればその価値は上がり、10点しか得られなければ下がる。これらのモデルは多くの種で行動と脳活動を結びつけるうえで大きな影響を与えてきました。しかし散発的な発見は、それらが単純すぎる可能性を示唆しています。人は特定の過去の出来事に特別な重みを置いたり、これまで見た報酬の全体的な範囲に敏感だったり、単一の連続的価値ときれいに一致しない脳信号を示したりします。
大規模なオンラインの確率ゲーム
これらの問題を探るために、研究者たちは800人以上のオンライン参加者に何百回もコンピュータゲームをプレイしてもらいました。各試行で、プレイヤーは4色の選択肢のいずれかを選び、獲得した点数を即座に見ました。参加者には知らせていませんでしたが、真の配当は時間とともにゆっくり変動しており、ゲームの開始時に最良だった選択肢が後では平凡になることがありました。60万回を超える試行を通じて、人々は概してより報酬の高い選択肢を好むようになりましたが、切り替え方、連続した行動、探索の詳細なパターンには単純なモデルでは捉えきれない豊かな構造が含まれていました。 
可読性のあるモデルとニューラルネットワークの融合
チームはこの行動を記述するいくつかの方法を比較しました。一方の極は、選択肢の価値を追跡する少数の数値と行動の反復・切り替えの単純な傾向を用いた注意深く調整された従来モデルでした。もう一方の極は、過去の情報を内部状態に豊かに保持できる一方で解釈が難しい柔軟な再帰型ニューラルネットワーク(RNN)でした。予想どおり、ニューラルネットワークは古典的モデルよりもはるかに人々の選択をよく予測しました。重要な一歩は、古典的アプローチの透明な構造を保ちつつ、個々の要素を小さなニューラルネットワークに置き換え、理論上データに合う任意の規則を学べるようにしたハイブリッドモデルを構築することでした。
隠れた記憶状態の発見
最初のハイブリッドは選択肢の価値のより柔軟な更新や未選択の選択肢の文脈への感度を可能にしましたが、これらの追加だけでは完全なニューラルネットワークには及びませんでした。決定的な前進はMemory-ANNと呼ばれるモデルでした。ここでは、選択を直接駆動する単純な変数とは別に、過去の報酬や行動を豊かに要約した個別の記憶変数が保持されました。これらの記憶変数はモデル内部の小型の再帰ネットワークとして実装されました。データに合わせてフィットさせると、Memory-ANNは解釈可能性を保ちつつ、不透明なニューラルネットワークと同等の予測力を示しました。解析により、その記憶は複数の時間スケールで最近および長期の報酬履歴を追跡し、新しい報酬が将来の選択に与える影響の強さを調整していることが示されました。 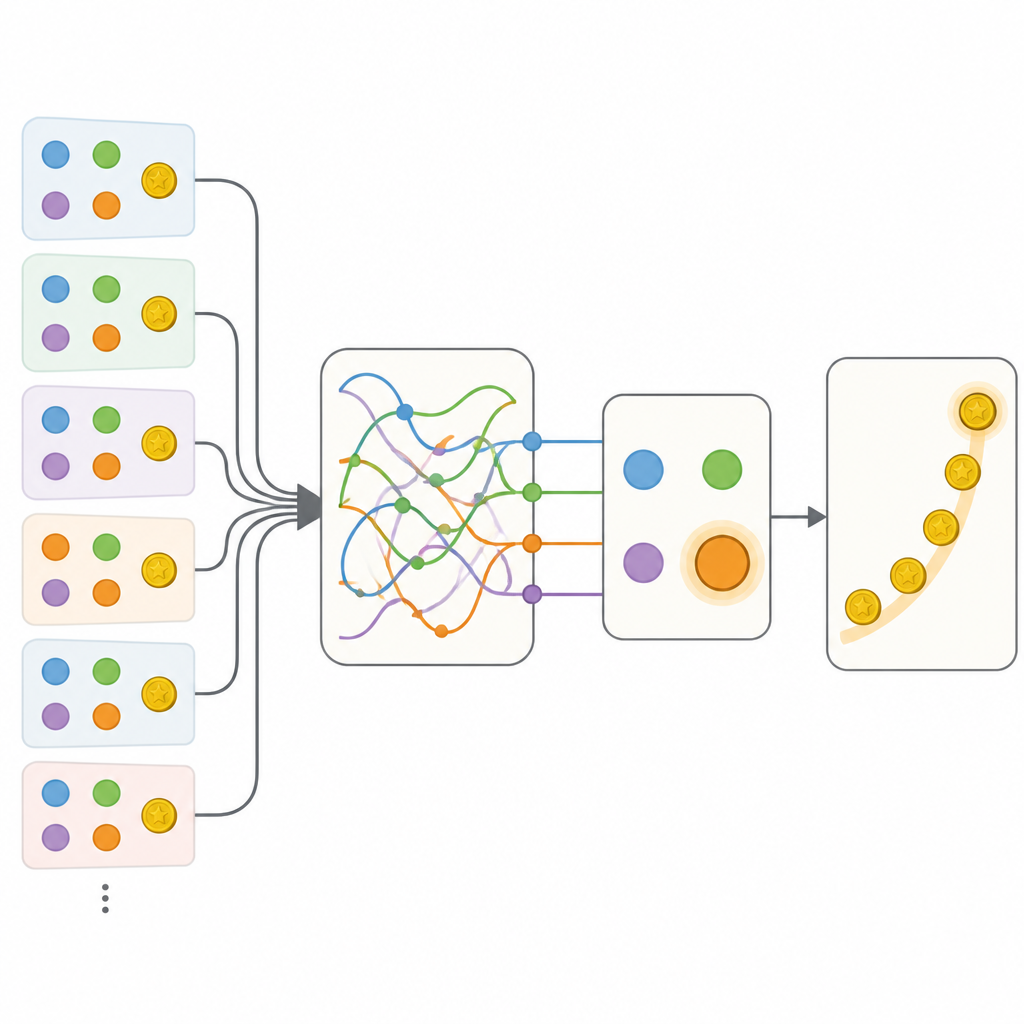
報酬から学ぶ仕組みに対する示唆
これらの発見は、人間の報酬学習を各選択肢について単一のスコアをゆっくり調整するだけで完全に記述することはできないことを示唆します。むしろ、私たちの脳はいつ何が起きたかのより豊かな内部記録を保持し、これらの記録を使って新たな勝ちや負けにどれだけ強く反応するかを調整しているようです。本研究は、古典的な認知理論とニューラルネットワークを組み合わせることで、この隠れた構造を明らかにできることを示しており、大規模データに適合しつつ日常の意思決定を導く心的過程に光を当てるモデルを提供します。
引用: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
キーワード: 報酬学習, 人間の意思決定, 記憶, 強化学習モデル, 再帰型ニューラルネットワーク