Clear Sky Science · ru
Гибридные нейро–когнитивные модели показывают, как память формирует обучение человека на основе вознаграждений
Почему прошлый опыт важен для повседневных выборов
Каждый раз, выбирая маршрут, закуску или сайт для клика, вы незаметно учитесь на прошлых наградах и разочарованиях. Психологи давно описывают это обучение с помощью простых формул, которые усредняют прошлые результаты в единую оценку для каждого варианта. В этом исследовании спрашивают, достаточно ли таких упрощённых представлений, чтобы объяснить, как реальные люди на самом деле учатся на вознаграждениях, и используют современные нейронные сети, чтобы выявить более богатую картину того, как память формирует наши выборы.
От простых оценок к более богатой памяти
Классические модели обучения через вознаграждение, известные как модели обучения с подкреплением, предполагают, что каждый вариант помечен одной скользящей величиной, которая обновляется немного после каждого исхода. Выбираете закуску, получаете 70 очков — внутренняя оценка этой закуски немного повышается; получаете 10 очков — она падает. Эти модели оказали большое влияние, связывая поведение и активность мозга у многих видов. Тем не менее разрозненные результаты указывают, что они могут быть чрезмерно упрощёнными. Люди иногда придают особое значение отдельным прошлым событиям, кажутся чувствительными к общему диапазону увиденных вознаграждений и показывают сигналы мозга, которые не укладываются аккуратно в рамки единой скользящей оценки.
Большая онлайн-игра на удачу
Чтобы изучить эти вопросы, исследователи привлекли более 800 онлайн‑добровольцев, которые сыграли в компьютерную игру сотни раз. В каждом испытании игроки выбирали один из четырёх цветных вариантов и тут же видели, сколько очков они выиграли. Им было неизвестно, что истинные выплаты медленно дрейфовали со временем, так что лучший вариант в начале игры мог со временем стать посредственным. В ходе более чем шестисот тысяч испытаний люди в целом научились предпочитать более вознаграждающие варианты, но их детальные паттерны переключений, полос удач и исследования содержали гораздо больше структуры, чем могли захватить простые модели. 
Сочетание понятных моделей с нейронными сетями
Команда сравнила несколько способов описания этого поведения. На одном полюсе была тщательно настроенная традиционная модель, использующая несколько параметров для отслеживания значений вариантов и простую склонность повторять или менять действия. На другом полюсе — гибкая рекуррентная нейронная сеть, своего рода искусственный «мозг», который может хранить богатую информацию о прошлом во внутреннем состоянии, но обычно трудно интерпретируем. Как и следовало ожидать, нейронная сеть предсказывала выборы людей значительно лучше, чем классическая модель. Ключевой шаг заключался в создании гибридных моделей, которые сохраняли прозрачную структуру классического подхода, но заменяли отдельные компоненты малыми нейросетями, способными в принципе выучить любое правило, соответствующее данным.
Обнаружение скрытых состояний памяти
Первые гибриды позволяли более гибко обновлять значения вариантов и учитывали контекст невыбранных опций, но эти дополнения всё ещё не достигали уровня полной нейронной сети. Решающий прогресс пришёл с моделью под названием Memory-ANN. Здесь система сохраняла отдельные переменные памяти, которые хранили богатое резюме прошлых вознаграждений и действий, отдельно от простых переменных, которые напрямую управляли выбором. Эти переменные памяти были реализованы компактными рекуррентными сетями внутри модели. При подгонке к данным Memory-ANN достигла предсказательной силы непрозрачной нейросети, оставаясь при этом интерпретируемой. Анализ показал, что её память отслеживала как недавнюю, так и долгосрочную историю вознаграждений на множественных временных шкалах и регулировала, насколько сильно новые вознаграждения влияют на будущие выборы. 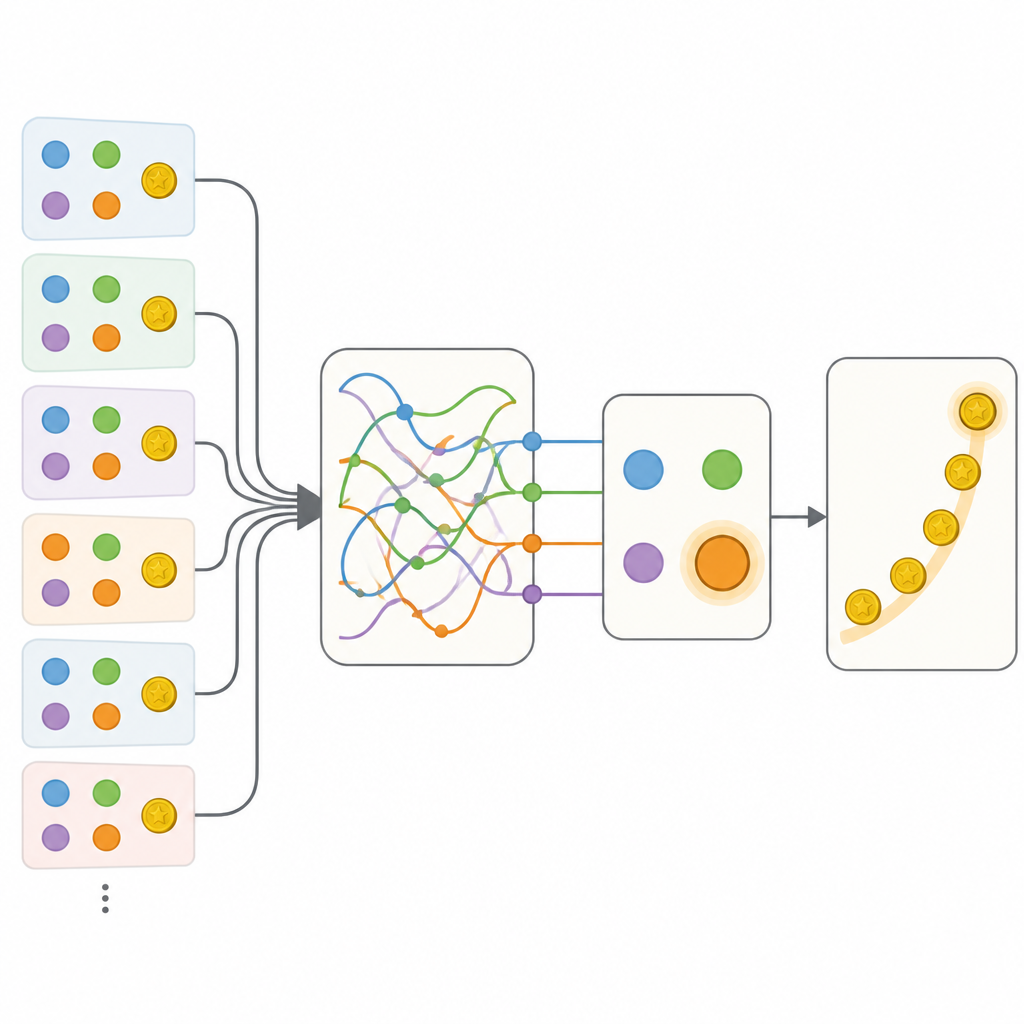
Что это значит для нашего понимания обучения на основе вознаграждений
Результаты указывают, что человеческое обучение на основе вознаграждений не сводится полностью к постепенной корректировке единой оценки для каждого варианта. Скорее похоже, что наш мозг поддерживает более богатые внутренние записи о том, что и когда происходило, и использует эти записи, чтобы настраивать, насколько сильно мы реагируем на новые выигрыши и потери. Работа показывает, что сочетание классических когнитивных теорий с нейронными сетями может выявить эту скрытую структуру, предлагая модели, которые одновременно хорошо подходят к большим наборам данных и проясняют ментальные процессы, управляющие повседневными решениями.
Цитирование: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Ключевые слова: обучение через вознаграждение, принятие решений человеком, память, модели обучения с подкреплением, рекуррентные нейронные сети