Clear Sky Science · ar
نماذج هجينة عصبية–معرفية تكشف كيف يشكّل الذّاكرة تعلّم المكافأة لدى البشر
لماذا تهمّ الخبرات الماضية في خياراتنا اليومية
في كل مرة تقرّر أي طريق تقود، أو أي وجبة خفيفة تشتري، أو أي موقع تنقر عليه، فأنت تتعلّم بهدوءٍ من المكافآت وخيبات الأمل الماضية. لطالما صَفَ علماء النفس هذا التعلّم بصيغ بسيطة تجمع النتائج السابقة في درجةٍ واحدة لكل خيار. يسأل هذا البحث عمّا إذا كانت مثل هذه النماذج المبسّطة كافية لشرح كيف يتعلّم الناس فعليًا من المكافآت، ويستخدم الشبكات العصبية الحديثة ليكشف صورة أعمق حول كيف تشكّل الذاكرة اختياراتنا.
من الدرجات البسيطة إلى ذّاكرات أغنى
تفترض النماذج الكلاسيكية لتعلّم المكافأة، المعروفة بنماذج التعلم المعزز، أن كل خيار يمكنك اختياره موسوم بقيمة تشغيلية واحدة يتم تحديثها قليلاً بعد كل نتيجة. تختار وجبة خفيفة، تحصل على 70 نقطة، فتتسلّل القيمة الداخلية لتلك الوجبة نحو الأعلى؛ تحصل على 10 نقاط فتنزلق نحو الأسفل. كانت هذه النماذج مؤثرة جداً، تربط بين السلوك والنشاط الدماغي في أنواعٍ عديدة. ومع ذلك، تشير نتائج متناثرة إلى أنها قد تكون مبسطة للغاية. يمكن للناس أن يضفوا وزنًا خاصًا لأحداث ماضية معينة، ويبدو أنهم حساسون لنطاق المكافآت الذي شاهدوه ككل، وتُظهِر إشارات دماغية لا تتوافق بسلاسة مع قيمة تشغيلية واحدة.
لعبة حظّ كبيرة على الإنترنت
لاستكشاف هذه القضايا، طلب الباحثون من أكثر من 800 متطوع عبر الإنترنت أن يلعبوا لعبة حاسوب مئات المرات. في كل تجربة، اختار اللاعبون أحد أربعة خيارات ملونة ورأوا فورًا عدد النقاط التي ربحوها. دون أن يعلموا، كانت العوائد الحقيقية تنجرف ببطء مع الزمن، بحيث قد يكون الخيار الأفضل في بداية اللعبة متوسطًا في وقت لاحق. عبر أكثر من ستمائة ألف تجربة، تعلّم الناس بوجه عام تفضيل الخيارات الأكثر مكافأة، لكن أنماط تبديلهم المتقنة، وتسلسلات الانتصارات والاستكشاف، احتوت على بنى أكثر تعقيدًا بكثير مما يمكن للنماذج البسيطة أن تلتقط. 
دمج نماذج قابلة للفهم البشري مع الشبكات العصبية
قارن الفريق عدة طرق لوصف هذا السلوك. في طرف واحد وُجِد نموذج تقليدي مضبوط بعناية استخدم عددًا محدودًا من الأرقام لتعقّب قيم الخيارات وميلًا بسيطًا لتكرار أو تبديل الأفعال. وفي الطرف الآخر وُجِد شبكة عصبية متكررة مرنة، نوع من الدماغ الاصطناعي الذي يمكنه تخزين معلومات غنية عن الماضي في حالته الداخلية لكنه عادة ما يكون صعب التفسير. كما هو متوقع، توقّعت الشبكة العصبية اختيارات الناس أفضل بكثير من النموذج الكلاسيكي. وكانت الخطوة الأساسية حينها بناء نماذج هجينة احتفظت بالهيكل الشفاف للنهج الكلاسيكي، لكن استبدلت قطعًا فردية بشبكات عصبية صغيرة كان بإمكانها، من حيث المبدأ، أن تتعلّم أي قاعدة تناسب البيانات.
اكتشاف حالات ذاكرة خفية
أتاح أول هجائن تحديثات أكثر مرونة لقيم الخيارات وحساسية لسياق الخيارات غير المختارة، لكن هذه الإضافات ما زالت أقل من الشبكة العصبية الكاملة. جاء التقدّم الحاسم مع نموذج سُمِّي Memory-ANN. هنا، احتفظ النظام بمتغيّرات ذاكرة مميزة خزّنت ملخصًا غنيًا للمكافآت والأفعال الماضية، منفصلة عن المتغيّرات الأبسط التي تُوجّه الاختيار مباشرة. نُفِّذت هذه المتغيّرات الذاكرية بشبكات متكررة مدمجة داخل النموذج. عند ملاءمتها مع البيانات، ضاهى Memory-ANN قدرة التنبؤ للشبكة العصبية المعتمة بينما بقي قابلاً للتفسير. أظهر التحليل أن ذاكرته تابعت تاريخ المكافآت القصير وطويل الأمد على مقاييس زمنية متعددة، وضبطت مدى تأثير المكافآت الجديدة على الاختيارات المستقبلية. 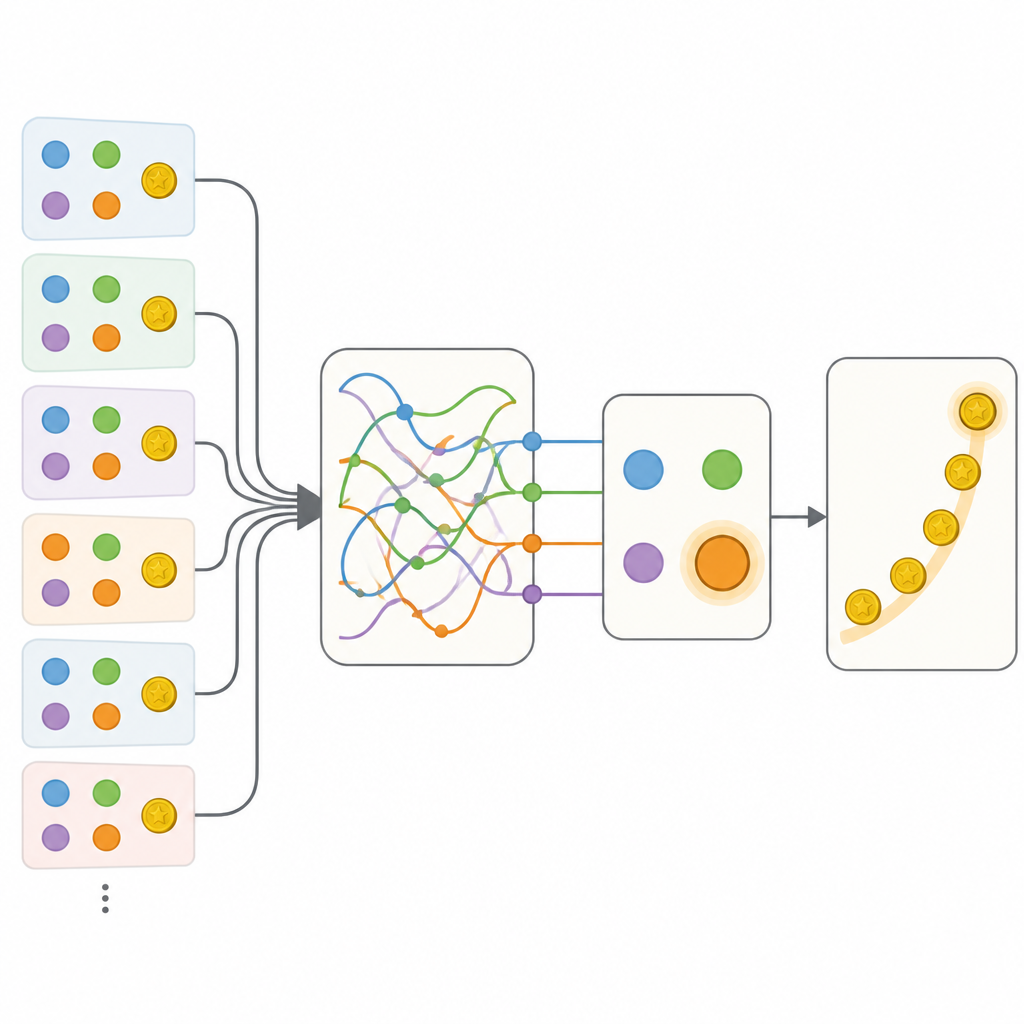
ما يعنيه هذا عن كيفية تعلّمنا من المكافآت
تشير النتائج إلى أن تعلّم المكافأة لدى البشر لا يمكن وصفه بالكامل على أنه تعديل بطيء لدرجة واحدة لكل خيار. بدلاً من ذلك، يبدو أن أدمغتنا تحافظ على سجلات داخلية أغنى عن ما حدث ومتى، وتستخدم هذه السجلات لضبط مدى ردّ فعلنا للمكافآت والخسائر الجديدة. تُظهِر هذه الدراسة أن الجمع بين النظريات المعرفية الكلاسيكية والشبكات العصبية يمكن أن يكشف هذه البنية الخفية، مقدّمًا نماذج تناسب مجموعات بيانات كبيرة وتضيء العمليات الذهنية التي توجّه قراراتنا اليومية.
الاستشهاد: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
الكلمات المفتاحية: تعلّم المكافأة, اتخاذ القرار البشري, الذاكرة, نماذج التعلم المعزز, الشبكات العصبية المتكررة