Clear Sky Science · tr
Hibrit sinir–bilişsel modeller, belleğin insan ödül öğrenimini nasıl şekillendirdiğini ortaya koyuyor
Geçmiş deneyimler günlük tercihleri neden etkiler
Hangi rotayı kullanacağınıza, hangi atıştırmalığı alacağınıza ya da hangi web sitesine tıklayacağınıza karar verdiğiniz her seferinde, geçmiş ödüller ve hayal kırıklıklarından gizlice öğreniyorsunuz. Psikologlar bu öğrenmeyi uzun zamandır her seçenek için geçmiş sonuçları tek bir puanda ortalayan basit formüllerle tanımladı. Bu çalışma, böyle sadeleştirilmiş yaklaşımların gerçek insanların ödüllerden nasıl öğrendiğini açıklamak için yeterli olup olmadığını soruyor ve belleğin tercihleri nasıl şekillendirdiğine dair daha zengin bir tabloyu ortaya çıkarmak için modern sinir ağlarını kullanıyor.
Basit puanlardan zengin anılara
Ödül öğreniminin klasik modelleri olan pekiştirmeli öğrenme modelleri, seçebileceğiniz her seçeneğin her sonuçtan sonra biraz güncellenen tek bir sürekli değere etiketlendiğini varsayar. Bir atıştırmalığı seçin, 70 puan alın ve o atıştırmalığın içsel değeri yukarı doğru kayar; 10 puan alın, aşağı iner. Bu modeller davranış ve beyin etkinliğini birçok türde bağlayan çok etkili oldu. Yine de dağınık bulgular bunların fazla basit olabileceğine işaret ediyor. İnsanlar belirli geçmiş olaylara özel ağırlık verebiliyor, gördükleri ödüllerin genel aralığına duyarlı görünebiliyor ve beynin tek bir sürekli değere kolayca uymayan sinyalleri gösterdiği gözlemleniyor.
Büyük çevrim içi bir şans oyunu
Bu konuları araştırmak için araştırmacılar 800’den fazla çevrim içi gönüllüden bir bilgisayar oyununu yüzlerce kez oynamalarını istedi. Her denemede katılımcılar dört renkli seçenekten birini seçti ve hemen kaç puan kazandıklarını gördü. Onlara haber verilmediği üzere gerçek kazançlar zaman içinde yavaşça değişiyordu, bu yüzden bir oyunun başında en iyi seçenek daha sonra vasat hale gelebiliyordu. Altı yüz binin üzerinde deneme boyunca insanlar genel olarak daha ödüllendirici seçenekleri tercih etmeyi öğrendi, fakat geçiş yapma, seri davranışlar ve keşfetme örüntüleri basit modellerin yakalayamayacağı kadar daha fazla yapı içeriyordu. 
İnsan tarafından okunabilir modelleri sinir ağlarıyla harmanlamak
Ekip bu davranışı tanımlamanın birkaç yolunu karşılaştırdı. Bir uçta, seçenek değerlerini izlemek için birkaç sayı ve eylemleri yineleme ya da değiştirme eğilimini modelleyen dikkatle ayarlanmış geleneksel bir model vardı. Diğer uçta ise geçmiş hakkında zengin bilgi depolayabilen ama genellikle yorumu zor olan esnek bir rekürrent sinir ağı, yapay bir beyin türü yer aldı. Beklendiği gibi, sinir ağı klasik modele göre insanların seçimlerini çok daha iyi tahmin etti. Ana adım daha sonra klasik yaklaşımın şeffaf yapısını koruyan, ancak bireysel parçaları veriye uyan herhangi bir kuralı öğrenebilecek küçük sinir ağlarıyla değiştiren hibrit modelleri kurmaktı.
Gizli bellek durumlarını keşfetmek
İlk hibritler seçenek değerlerinin daha esnek güncellenmesine ve seçilmeyen seçeneklerin bağlamına duyarlılığa izin verdi, ancak bu eklemeler yine de tam sinir ağının gerisinde kaldı. Belirleyici ilerleme Memory-ANN adlı bir modelle geldi. Burada sistem, doğrudan tercihi yönlendiren daha basit değişkenlerden ayrı olarak geçmiş ödüllerin ve eylemlerin zengin bir özetini saklayan ayrı bellek değişkenlerini korudu. Bu bellek değişkenleri modelin içinde kompakt rekürrent ağlarla uygulandı. Veriye uyarlandığında Memory-ANN opak sinir ağının öngörü gücüne eşit performans gösterirken yorumlanabilirliğini korudu. Analiz, belleğinin hem yakın hem de uzun vadeli ödül geçmişini birden çok zaman ölçeğinde takip ettiğini ve yeni ödüllerin gelecekteki tercihler üzerindeki etkisini nasıl ayarladığını gösterdi. 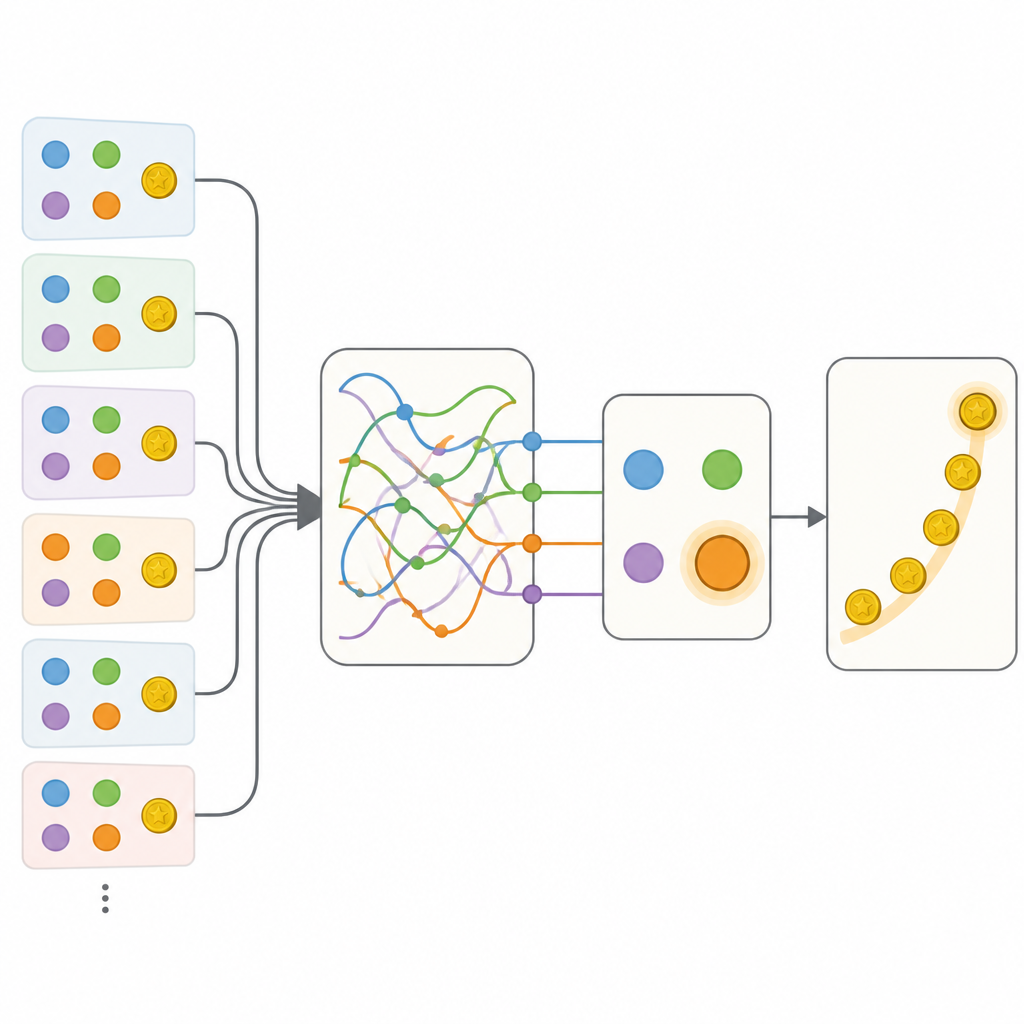
Ödüllerden nasıl öğrendiğimize dair çıkarımlar
Bulgular, insan ödül öğreniminin her seçenek için tek bir puanı yavaşça ayarlamakla tam olarak tanımlanamayacağını öne sürüyor. Bunun yerine, beynimiz nerede ne olduğuna dair daha zengin iç kayıtlar tutuyor gibi görünüyor ve bu kayıtları yeni kazanç ve kayıplara nasıl tepki vereceğimizi ayarlamak için kullanıyor. Çalışma, klasik bilişsel teorileri sinir ağlarıyla birleştirmenin bu gizli yapıyı açığa çıkarabileceğini, büyük veri kümelerine uyum sağlayan ve günlük kararları yönlendiren zihinsel süreçlere ışık tutan modeller sunduğunu gösteriyor.
Atıf: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Anahtar kelimeler: ödül öğrenimi, insan karar verme, hafıza, pekiştirmeli öğrenme modelleri, rekürrent sinir ağları