Clear Sky Science · pl
Hybrydowe modele neuronowo‑poznawcze ujawniają, jak pamięć kształtuje uczenie się na podstawie nagród u ludzi
Dlaczego przeszłe doświadczenia mają znaczenie dla codziennych wyborów
Za każdym razem, gdy decydujesz, którą trasą jechać, jaki przekąskę kupić czy który link kliknąć, potajemnie uczysz się na podstawie wcześniejszych nagród i rozczarowań. Psychologowie od dawna opisują to uczenie się prostymi wzorami, które uśredniają przeszłe wyniki do jednej oceny dla każdej opcji. W tym badaniu pytano, czy takie odchudzone wyjaśnienia wystarczają, by wytłumaczyć, jak ludzie naprawdę uczą się na podstawie nagród, i wykorzystano nowoczesne sieci neuronowe, by odsłonić bogatszy obraz tego, jak pamięć kształtuje nasze wybory.
Od prostych ocen do bogatszych wspomnień
Klasyczne modele uczenia się przez nagrody, znane jako modele uczenia ze wzmocnieniem, zakładają, że każda opcja jest oznaczona pojedynczą bieżącą wartością, która jest nieco aktualizowana po każdym wyniku. Wybierz przekąskę, zdobądź 70 punktów i wewnętrzna wartość tej przekąski nieco wzrasta; zdobądź 10 punktów i spada. Te modele miały duży wpływ, łącząc zachowanie i aktywność mózgu u wielu gatunków. Jednak rozproszone wyniki sugerują, że mogą być zbyt proste. Ludzie potrafią nadawać szczególne znaczenie konkretnym przeszłym zdarzeniom, wydają się wrażliwi na ogólny zakres otrzymanych nagród i wykazują sygnały mózgowe, które nie układają się ściśle w jedną bieżącą wartość.
Duża internetowa gra losowa
Aby zbadać te zagadnienia, badacze poprosili ponad 800 ochotników online o zagranie w komputerową grę setki razy. W każdym zadaniu gracze wybierali jedną z czterech kolorowych opcji i od razu widzieli, ile punktów zdobyli. Nie wiedzieli, że prawdziwe wypłaty powoli się przesuwały w czasie, tak że najlepsza opcja na początku gry mogła później stać się przeciętna. Na przestrzeni ponad sześciuset tysięcy prób ludzie zazwyczaj uczyli się faworyzować bardziej nagradzające opcje, ale ich szczegółowe wzorce przełączania się, serii i eksploracji zawierały znacznie więcej struktury, niż mogły uchwycić proste modele. 
Łączenie czytelnych dla człowieka modeli z sieciami neuronowymi
Zespół porównał kilka sposobów opisu tego zachowania. Na jednym końcu znajdował się starannie dopracowany tradycyjny model, który używał garstki liczb do śledzenia wartości opcji oraz prostej tendencji do powtarzania lub zmiany działań. Na drugim końcu była elastyczna rekurencyjna sieć neuronowa — rodzaj sztucznego mózgu, który może przechowywać bogate informacje o przeszłości w swoim stanie wewnętrznym, ale zwykle trudno go interpretować. Jak można było się spodziewać, sieć neuronowa przewidywała wybory ludzi znacznie lepiej niż klasyczny model. Kluczowym krokiem było więc zbudowanie modeli hybrydowych, które zachowały przejrzystą strukturę klasycznego podejścia, ale zastąpiły poszczególne elementy małymi sieciami neuronowymi, które mogły, przynajmniej w teorii, nauczyć się dowolnej reguły dopasowanej do danych.
Odkrywanie ukrytych stanów pamięci
Pierwsze hybrydy pozwalały na bardziej elastyczną aktualizację wartości opcji oraz na wrażliwość na kontekst niewybranych opcji, ale te dodatki wciąż nie dorównywały pełnej sieci neuronowej. Przełom nastąpił wraz z modelem nazwanym Memory-ANN. W tym podejściu system utrzymywał odrębne zmienne pamięci, które przechowywały bogate streszczenie przeszłych nagród i działań, oddzielone od prostszych zmiennych bezpośrednio sterujących wyborem. Zmienne pamięci zaimplementowano jako kompaktowe sieci rekurencyjne wewnątrz modelu. Po dopasowaniu do danych Memory-ANN dorównywał mocy predykcyjnej nieprzezroczystej sieci neuronowej, pozostając jednocześnie interpretowalnym. Analiza wykazała, że jego pamięć śledziła zarówno niedawną, jak i długoterminową historię nagród na wielu skalach czasowych oraz dostosowywała, jak silnie nowe nagrody wpływają na przyszłe wybory. 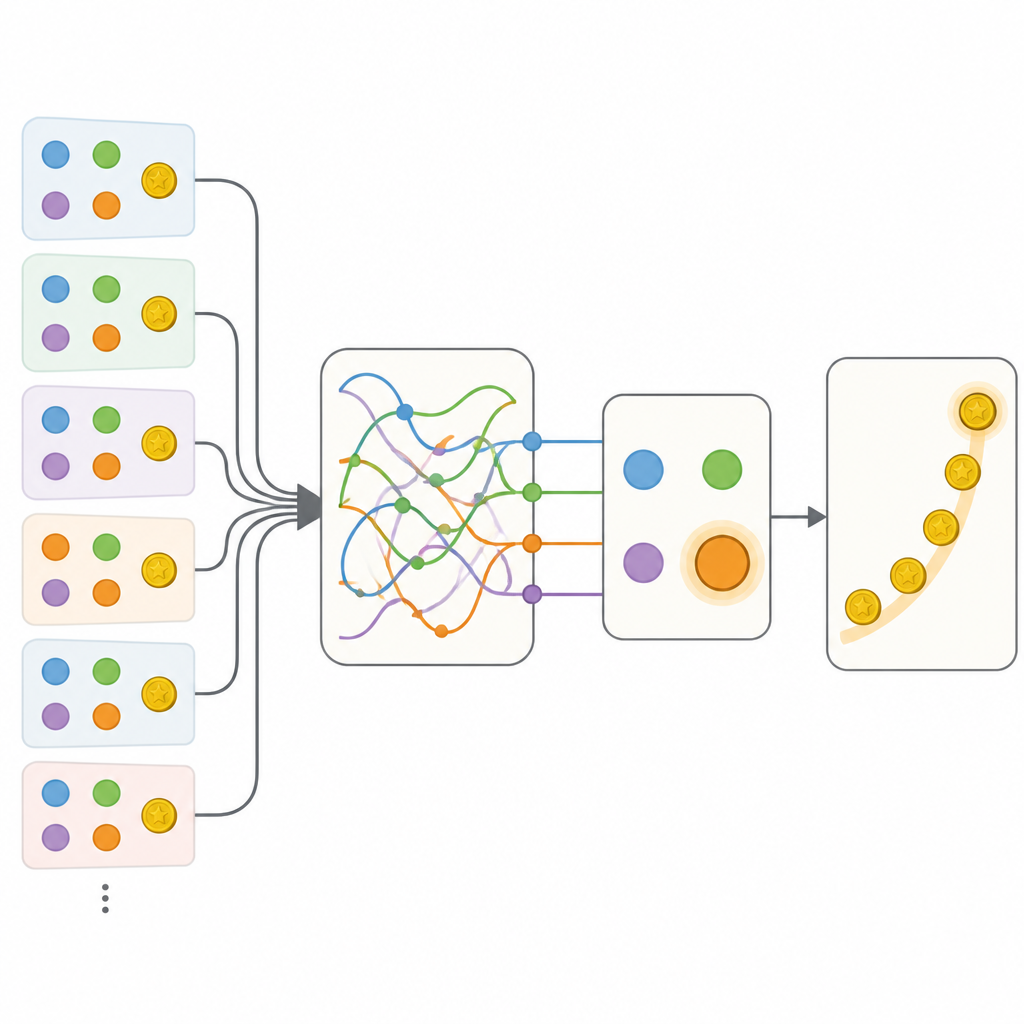
Co to oznacza dla naszego uczenia się na podstawie nagród
Wyniki sugerują, że ludzkiego uczenia się na podstawie nagród nie da się w pełni opisać jako powolnej regulacji pojedynczej oceny dla każdej opcji. Zamiast tego nasze mózgi wydają się utrzymywać bogatsze wewnętrzne zapisy tego, co wydarzyło się kiedy, i korzystać z tych zapisów, by dostrajać, jak silnie reagujemy na nowe zwycięstwa i porażki. Badanie pokazuje, że łączenie klasycznych teorii poznawczych z sieciami neuronowymi może ujawnić tę ukrytą strukturę, oferując modele, które zarówno dopasowują się do dużych zbiorów danych, jak i rzucają światło na procesy umysłowe kierujące codziennymi decyzjami.
Cytowanie: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Słowa kluczowe: uczenie się przez nagrody, ludzkie podejmowanie decyzji, pamięć, modele uczenia ze wzmocnieniem, recurrent neural networks