Clear Sky Science · pt
Modelos híbridos neurais–cognitivos revelam como a memória molda o aprendizado por recompensa humano
Por que experiências passadas importam para escolhas do dia a dia
Cada vez que você decide qual caminho dirigir, qual lanche comprar ou em qual site clicar, você está silenciosamente aprendendo com recompensas e frustrações passadas. Psicólogos há muito descrevem esse aprendizado com fórmulas simples que fazem a média dos resultados anteriores em um único escore para cada opção. Este estudo pergunta se esses relatos simplificados são suficientes para explicar como pessoas reais realmente aprendem com recompensas, e usa redes neurais modernas para descobrir uma imagem mais rica de como a memória molda nossas escolhas.
De escores simples a memórias mais ricas
Modelos clássicos de aprendizado por recompensa, conhecidos como modelos de aprendizado por reforço, assumem que cada opção que você pode escolher é marcada com um único valor em andamento que é atualizado um pouco após cada resultado. Escolha um lanche, ganhe 70 pontos, e o valor interno para esse lanche sobe; ganhe 10 pontos, e ele cai. Esses modelos foram muito influentes, conectando comportamento e atividade cerebral em muitas espécies. Ainda assim, achados dispersos sugerem que podem ser simplistas demais. Pessoas podem dar peso especial a eventos passados específicos, parecem sensíveis à amplitude geral das recompensas que viram e exibem sinais cerebrais que não se alinham de forma clara com um único valor em andamento.
Um grande jogo de azar online
Para investigar essas questões, os pesquisadores pediram a mais de 800 voluntários online que jogassem um jogo de computador centenas de vezes. Em cada tentativa, os jogadores escolhiam uma das quatro opções coloridas e viam imediatamente quantos pontos haviam ganho. Sem que soubessem, os pagamentos reais mudavam lentamente ao longo do tempo, de modo que a melhor opção no início de um jogo poderia ser mediana mais tarde. Em mais de seiscentas mil tentativas, as pessoas geralmente aprenderam a favorecer as escolhas mais recompensadoras, mas seus padrões detalhados de troca, sequências e exploração continham bem mais estrutura do que modelos simples conseguiam captar. 
Misturando modelos legíveis por humanos com redes neurais
A equipe comparou várias maneiras de descrever esse comportamento. Em um extremo estava um modelo tradicional cuidadosamente ajustado que usava um punhado de números para rastrear valores das opções e uma tendência simples de repetir ou alternar ações. No outro extremo estava uma rede neural recorrente flexível, um tipo de cérebro artificial que pode armazenar informações ricas sobre o passado em seu estado interno, mas que costuma ser difícil de interpretar. Como esperado, a rede neural previu as escolhas das pessoas muito melhor do que o modelo clássico. A etapa chave foi então construir modelos híbridos que mantivessem a estrutura transparente da abordagem clássica, mas substituíssem peças individuais por pequenas redes neurais que poderiam, em princípio, aprender qualquer regra compatível com os dados.
Descobrindo estados de memória ocultos
Os primeiros híbridos permitiram atualização mais flexível dos valores das opções e sensibilidade ao contexto das opções não escolhidas, mas essas adições ainda ficaram aquém da rede neural completa. O avanço decisivo veio com um modelo chamado Memory-ANN. Aqui, o sistema manteve variáveis de memória distintas que armazenavam um resumo rico das recompensas e ações passadas, separado das variáveis mais simples que direcionavam diretamente a escolha. Essas variáveis de memória foram implementadas com redes recorrentes compactas dentro do modelo. Quando ajustado aos dados, o Memory-ANN igualou o poder preditivo da rede neural opaca ao mesmo tempo em que permanecia interpretável. A análise mostrou que sua memória acompanhava tanto a história recente quanto a de longo prazo das recompensas em múltiplas escalas temporais, e ajustava quão fortemente novas recompensas influenciavam escolhas futuras. 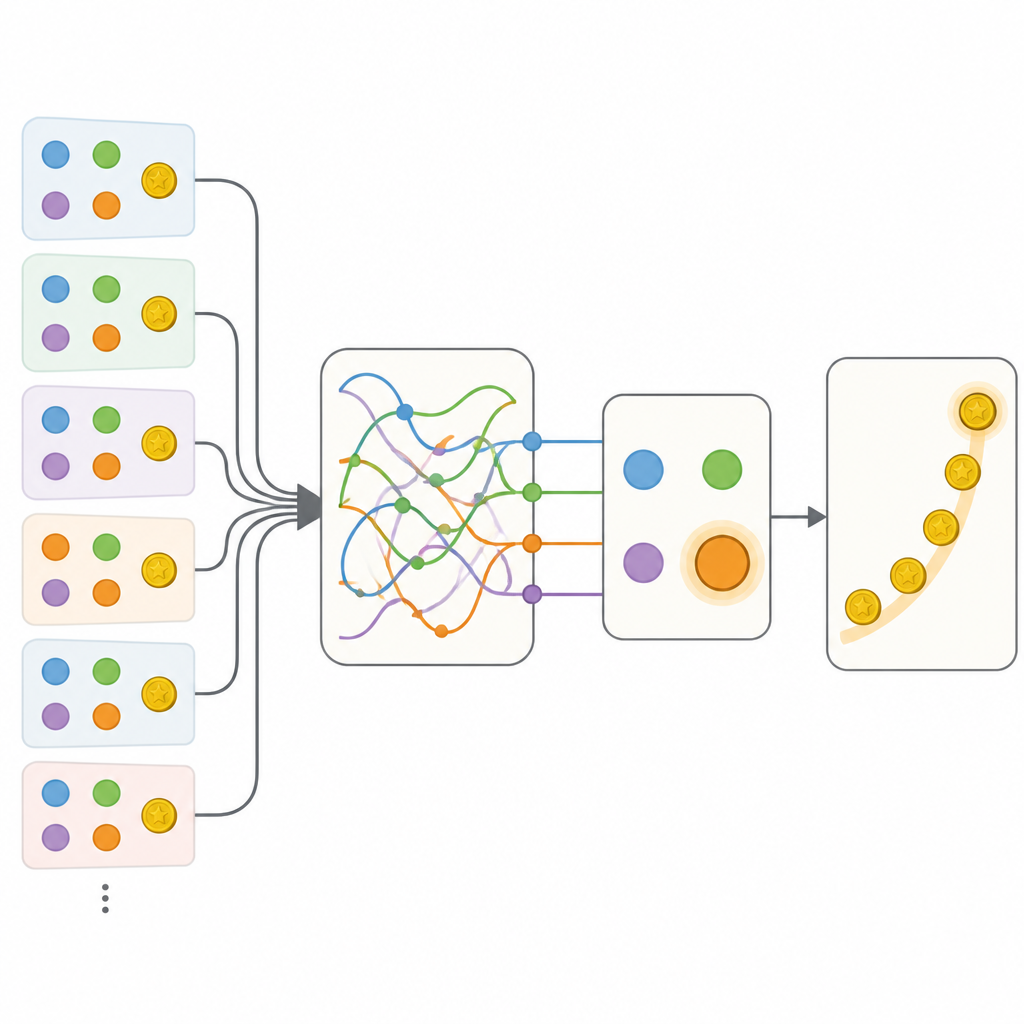
O que isso significa para como aprendemos com recompensas
Os achados sugerem que o aprendizado por recompensa humano não pode ser totalmente descrito como o ajuste lento de um único escore para cada opção. Em vez disso, nossos cérebros parecem manter registros internos mais ricos do que aconteceu quando, e usam esses registros para ajustar com que intensidade reagimos a novas vitórias e perdas. O trabalho mostra que combinar teorias cognitivas clássicas com redes neurais pode revelar essa estrutura oculta, oferecendo modelos que tanto se ajustam a grandes conjuntos de dados quanto lançam luz sobre os processos mentais que guiam decisões do dia a dia.
Citação: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Palavras-chave: aprendizado por recompensa, tomada de decisão humana, memória, modelos de aprendizado por reforço, redes neurais recorrentes