Clear Sky Science · he
מודלים היברידיים נוירונליים־קוגניטיביים חושפים כיצד זיכרון מעצב את למידת התגמול האנושית
למה חוויות עבר חשובות לבחירות היומיומיות
בכל פעם שאתם מחליטים באיזה מסלול לנהוג, איזה חטיף לקנות או על איזה אתר להקליק, אתם לומדים בשקט מתגמולים ותסכולים קודמים. פסיכולוגים תיארו זמן רב את הלמידה הזו באמצעות נוסחאות פשוטות שממוצעות תוצאות עבר לתוך ניקוד יחיד עבור כל אופציה. המחקר הזה שואל האם תיאורים מצומצמים כאלה מספיקים כדי להסביר כיצד אנשים אמיתיים לומדים מתגמולים, ומשתמש ברשתות עצביות מודרניות כדי לחשוף תמונה עשירה יותר של האופן שבו הזיכרון מעצב את הבחירות שלנו.
מאפסים פשוטים לזיכרונות עשירים יותר
מודלים קלאסיים של למידת תגמול, הידועים כמודלי חיזוק, מניחים שכל אופציה שסומכת עליכם מסומנת עם ערך רץ בודד שמתעדכן במעט אחרי כל תוצאה. בחרו חטיף, קיבלתם 70 נקודות והערך הפנימי של החטיף מטפס; קיבלתם 10 נקודות והערך יורד. מודלים אלה השפיעו רבות וקישרו בין התנהגות לפעילות מוחית במגוון מינים. יחד עם זאת, ממצאים מפוזרים מרמזים שהם עלולים להיות פשוטים מדי. אנשים יכולים להקנות משקל מיוחד לאירועים מסוימים בעבר, להראות רגישות לטווח הכולל של התגמולים שראו, ולהציג אותות מוחיים שאינם תואמים בצורה נקייה לערך רץ יחיד.
משחק סיכוי מקוון גדול
כדי לבחון סוגיות אלו, החוקרים ביקשו יותר מ־800 מתנדבים מקוונים לשחק משחק מחשב מאות פעמים. בכל ניסיון בחרו השחקנים אחת מארבע אפשרויות צבעוניות וראו מיד כמה נקודות הרוויחו. מבלי שידעו, ההחזרים האמיתיים נשחקו בהדרגה לאורך הזמן, כך שהאפשרות הטובה בתחילת המשחק עשויה להיות בינונית לאחר מכן. במשך יותר מ־שש מאות אלף ניסיונות, בני האדם בדרך כלל למדו להעדיף את הבחירות המתגמלות יותר, אך דפוסי המעבר, רצפי ההצלחות והחקירה שלהם הכילו מבנה רב־פרטים הרבה יותר ממה שמודלים פשוטים יכלו ללכוד. 
שילוב מודלים שקופים עם רשתות עצביות
הקבוצה השוותה כמה דרכים לתאר את ההתנהגות הזו. בקצה אחד עמד מודל מסורתי מכויל בקפידה שהשתמש בכמה ערכים כדי לעקוב אחר ערכי אופציות ונוטה פשוטה לחזור על פעולה או להחליף. בקצה השני עמדה רשת עצבית חוזרת גמישה, סוג של מוח מלאכותי היכול לאחסן מידע עשיר על העבר במצבו הפנימי אך בדרך כלל קשה לפענוח. כצפוי, הרשת תחזתה את בחירות האנשים טוב יותר מהמבחן הקלאסי. הצעד המכריע היה לבנות מודלים היברידיים ששמרו על המבנה השקוף של הגישה הקלאסית, אך החליפו רכיבים בודדים ברשתות עצביות קטנות שיכלו, בעקרון, ללמוד כל כלל שמתאים לנתונים.
גילוי מצבי זיכרון נסתרים
ההיברידים הראשונים אפשרו עדכון גמיש יותר של ערכי אופציות ורגישות להקשר של אופציות שלא נבחרו, אך תוספות אלה עדיין לא השוו לרשת המלאה. הפריצה המכרעת הגיעה עם מודל שנקרא Memory-ANN. כאן המערכת שמרה משתני זיכרון נפרדים שאחסנו סיכום עשיר של תגמולים ופעולות עבר, נפרדים מהמשתנים הפשוטים שניהלו ישירות את הבחירה. משתני הזיכרון האלה הוטמעו באמצעות רשתות חוזרות קומפקטיות בתוך המודל. כאשר כויל המודל על הנתונים, Memory-ANN השיג עוצמת חיזוי שוות ערך לזו של הרשת האטומה ועדיין נשאר מובן. ניתוח הראה שהזיכרון שלו עקב הן אחרי היסטוריית תגמולים קצרה והן ארוכת טווח בריבוי סקאלות זמן, והתאים עד כמה תגמולים חדשים משפיעים על בחירות עתידיות. 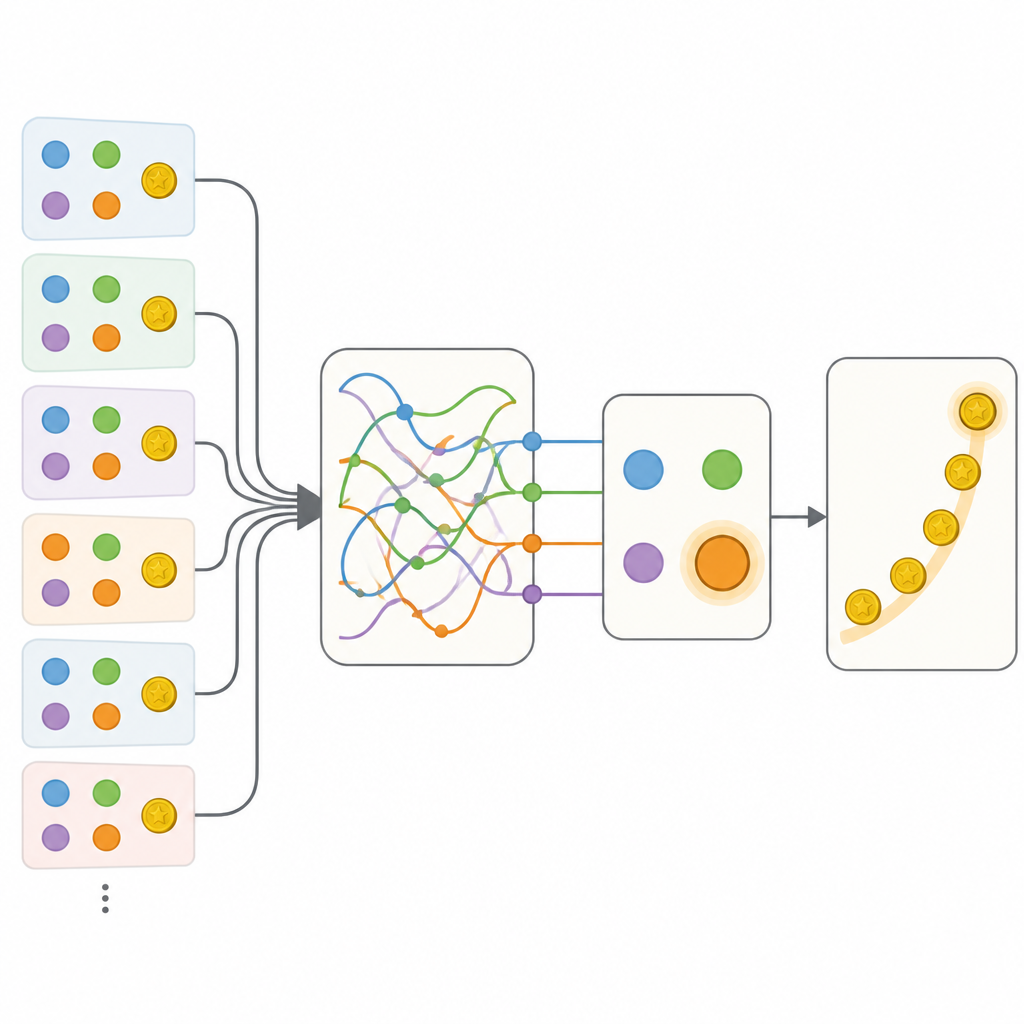
מה משמעות הממצאים לגבי האופן שבו אנו לומדים מתגמולים
הממצאים מרמזים שלמידת תגמול אנושית לא ניתנת לתיאור מלא כסתם ככיוונון איטי של ניקוד יחיד לכל אופציה. במקום זאת, נראה שמוחנו שומר רישומים פנימיים עשירים יותר של מה קרה ומתי, ומשתמש ברשומות אלה כדי לכוונן עד כמה אנו מגיבים לניצחונות והפסדים חדשים. העבודה מראה ששילוב תיאוריות קוגניטיביות קלאסיות עם רשתות עצביות יכול לחשוף מבנה חבוי זה, ולהציע מודלים שמתאימים למאגרי נתונים גדולים ובו־זמנית מאירים את התהליכים המנטליים שמנחים החלטות יומיומיות.
ציטוט: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
מילות מפתח: למידת תגמול, קבלת החלטות אנושית, זיכרון, מודלים של חיזוק, רשתות עצביות חוזרות