Clear Sky Science · sv
Hybridneuro-kognitiva modeller avslöjar hur minnet formar människans belöningsinlärning
Varför tidigare erfarenheter spelar roll för vardagliga val
Varje gång du bestämmer vilken väg du ska köra, vilket mellanmål du ska köpa eller vilken webbplats du ska klicka på, lär du dig tyst från tidigare belöningar och besvikelser. Psykologer har länge beskrivit denna inlärning med enkla formler som sammanfattar tidigare utfall till en enda poäng för varje alternativ. Denna studie undersöker om sådana förenklade förklaringar räcker för att förklara hur verkliga människor faktiskt lär sig av belöningar, och använder moderna neurala nätverk för att avslöja en rikare bild av hur minnet formar våra val.
Från enkla poäng till rikare minnen
Klassiska modeller för belöningsinlärning, kända som förstärkningsinlärningsmodeller, antar att varje valbart alternativ är märkt med ett enda löpande värde som uppdateras lite efter varje utfall. Väljer du ett mellanmål och får 70 poäng, kryper det interna värdet för det mellanmålet uppåt; får du 10 poäng, sjunker det. Dessa modeller har varit mycket inflytelserika och kopplar beteende till hjärnaktivitet hos många arter. Ändå antyder spridda fynd att de kan vara för enkla. Människor kan ge särskild vikt åt specifika tidigare händelser, verkar känsliga för den övergripande spannet av belöningar de sett, och uppvisar hjärnsignaler som inte linjerar väl med ett enda löpande värde.
Ett stort online-spel av slump
För att undersöka dessa frågor bad forskarna mer än 800 onlinefrivilliga att spela ett datorspel flera hundra gånger. I varje omgång valde spelarna ett av fyra färgade alternativ och såg omedelbart hur många poäng de vunnit. Utan deras vetskap förändrades de verkliga utbetalningarna långsamt över tid, så att det bästa alternativet i början av spelet kanske var mediokert senare. Över mer än sexhundra tusen prövningar lärde sig människor i allmänhet att favorisera de mer belönande valen, men deras detaljerade mönster av växlingar, sviter och utforskande innehöll mycket mer struktur än vad enkla modeller kunde fånga. 
Att blanda lättförståeliga modeller med neurala nätverk
Teamet jämförde flera sätt att beskriva detta beteende. I ena änden fanns en noggrant finjusterad traditionell modell som använde ett fåtal tal för att spåra alternativvärden och en enkel tendens att upprepa eller byta handlingar. I andra änden fanns ett flexibelt rekurrent neuralt nätverk, en sorts artificiell hjärna som kan lagra rik information om det förflutna i sitt interna tillstånd men som vanligtvis är svår att tolka. Som förväntat förutsade det neurala nätverket människors val mycket bättre än den klassiska modellen. Nyckelsteget var sedan att bygga hybrida modeller som behöll den transparenta strukturen hos den klassiska metoden, men ersatte enskilda delar med små neurala nätverk som i princip kunde lära sig vilken regel som helst som passade data.
Upptäckten av dolda minnesstater
De första hybriderna tillät mer flexibel uppdatering av alternativvärden och känslighet för kontexten hos icke-valda alternativ, men dessa tillägg räckte fortfarande inte upp till det fulla neurala nätverket. Det avgörande framsteget kom med en modell kallad Memory-ANN. Här höll systemet skilda minnesvariabler som lagrade en rik sammanfattning av tidigare belöningar och handlingar, separerade från de enklare variabler som direkt styrde valet. Dessa minnesvariabler implementerades med kompakta rekurrenta nätverk inom modellen. När modellen anpassades till data matchade Memory-ANN den opaka neurala nätverkets prediktiva kraft samtidigt som den förblev tolkbar. Analys visade att dess minne följde både senaste och långsiktiga belöningshistorik på flera tidsskalor och justerade hur starkt nya belöningar påverkade framtida val. 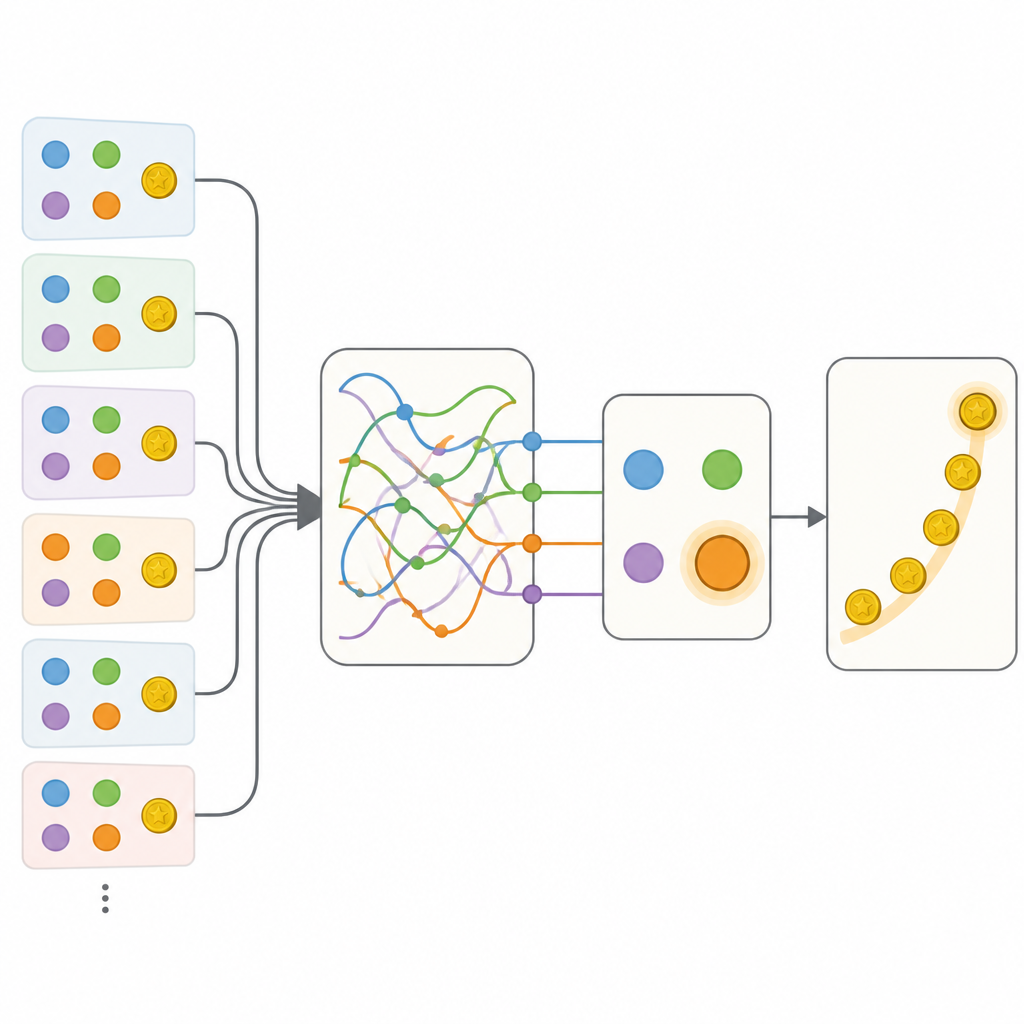
Vad detta innebär för hur vi lär oss av belöningar
Resultaten antyder att människors belöningsinlärning inte fullt ut kan beskrivas som en långsamt justerande enskild poäng för varje alternativ. I stället verkar våra hjärnor behålla rikare interna register över vad som hände när, och använda dessa register för att finjustera hur starkt vi reagerar på nya vinster och förluster. Arbetet visar att kombinationen av klassiska kognitiva teorier och neurala nätverk kan avslöja denna dolda struktur och erbjuda modeller som både passar stora datamängder och ger insikt i de mentala processer som styr vardagliga beslut.
Citering: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Nyckelord: belöningsinlärning, mänskligt beslutsfattande, minne, förstärkningsinlärningsmodeller, rekurrenta neurala nätverk