Clear Sky Science · de
Hybride neuronale–kognitive Modelle zeigen, wie Gedächtnis das menschliche Belohnungslernen formt
Warum frühere Erfahrungen für Alltagsentscheidungen wichtig sind
Jedes Mal, wenn Sie entscheiden, welche Strecke Sie fahren, welchen Snack Sie kaufen oder auf welche Website Sie klicken, lernen Sie leise aus früheren Belohnungen und Enttäuschungen. Psychologen haben dieses Lernen lange mit einfachen Formeln beschrieben, die vergangene Ergebnisse zu einem einzigen Wert für jede Option zusammenfassen. Diese Studie fragt, ob solche reduzierten Beschreibungen ausreichen, um zu erklären, wie reale Menschen tatsächlich aus Belohnungen lernen, und nutzt moderne neuronale Netze, um ein reichhaltigeres Bild davon zu zeichnen, wie Gedächtnis unsere Entscheidungen prägt.
Von einfachen Werten zu reichhaltigeren Erinnerungen
Klassische Modelle des Belohnungslernens, bekannt als Verstärkungslernmodelle, gehen davon aus, dass jede verfügbare Option mit einem einzelnen laufenden Wert versehen ist, der nach jedem Ergebnis ein wenig aktualisiert wird. Wählen Sie einen Snack, erhalten 70 Punkte, und der interne Wert für diesen Snack steigt leicht; erhalten Sie 10 Punkte, sinkt er. Diese Modelle waren sehr einflussreich und verbanden Verhalten und Hirnaktivität in vielen Spezies. Dennoch deuten verstreute Befunde darauf hin, dass sie zu einfach sein könnten. Menschen können bestimmten vergangenen Ereignissen besonderes Gewicht geben, scheinen empfindlich auf die gesamte Spanne der gesehenen Belohnungen zu reagieren und zeigen Hirnsignale, die sich nicht sauber mit einem einzelnen laufenden Wert decken.
Ein großes Online-Glücksspiel
Um diese Fragen zu untersuchen, baten die Forschenden mehr als 800 Online-Freiwillige, ein Computerspiel hunderte Male zu spielen. In jedem Durchgang wählten die Spieler eine von vier farbigen Optionen und sahen sofort, wie viele Punkte sie gewonnen hatten. Ohne ihr Wissen drifteten die tatsächlichen Auszahlungen im Laufe der Zeit langsam, sodass die zu Beginn beste Option später nur noch mittelmäßig sein konnte. Über mehr als sechshunderttausend Durchgänge hinweg lernten die Menschen im Allgemeinen, die lohnenderen Optionen zu bevorzugen, doch ihre detaillierten Muster von Wechseln, Serien und Exploration zeigten weit mehr Struktur, als einfache Modelle erfassen konnten. 
Menschlich verständliche Modelle mit neuronalen Netzen verschmelzen
Das Team verglich mehrere Weisen, dieses Verhalten zu beschreiben. An einem Extrem stand ein sorgfältig abgestimmtes traditionelles Modell, das mit wenigen Zahlen Optionswerte und eine einfache Tendenz zum Wiederholen oder Wechseln von Aktionen verfolgte. Am anderen Extrem stand ein flexibles rekurrentes neuronales Netz, eine Art künstliches Gehirn, das reichhaltige Informationen über die Vergangenheit in seinem internen Zustand speichern kann, aber üblicherweise schwer zu interpretieren ist. Wie erwartet sagte das neuronale Netz die Entscheidungen der Menschen deutlich besser voraus als das klassische Modell. Der entscheidende Schritt war dann, hybride Modelle zu bauen, die die transparente Struktur des klassischen Ansatzes bewahrten, aber einzelne Teile durch kleine neuronale Netze ersetzten, die prinzipiell jede Regel erlernen konnten, die zu den Daten passte.
Verborgene Gedächtniszustände entdecken
Die ersten Hybride erlaubten flexiblere Aktualisierungen der Optionswerte und Sensitivität gegenüber dem Kontext nicht gewählter Optionen, doch diese Erweiterungen reichten nicht an das vollständige neuronale Netz heran. Der entscheidende Fortschritt kam mit einem Modell namens Memory-ANN. Hier behielt das System getrennte Gedächtnisvariablen bei, die eine reichhaltige Zusammenfassung vergangener Belohnungen und Handlungen speicherten, getrennt von den einfacheren Variablen, die direkt die Wahl steuerten. Diese Gedächtnisvariablen wurden im Modell mit kompakten rekurrenten Netzen implementiert. Beim Anpassen an die Daten erreichte Memory-ANN die Vorhersagekraft des undurchsichtigen neuronalen Netzes, blieb dabei aber interpretierbar. Die Analyse zeigte, dass sein Gedächtnis sowohl die kürzlichen als auch die langfristigen Belohnungsverläufe auf mehreren Zeitskalen verfolgte und anpasste, wie stark neue Belohnungen künftige Entscheidungen beeinflussten. 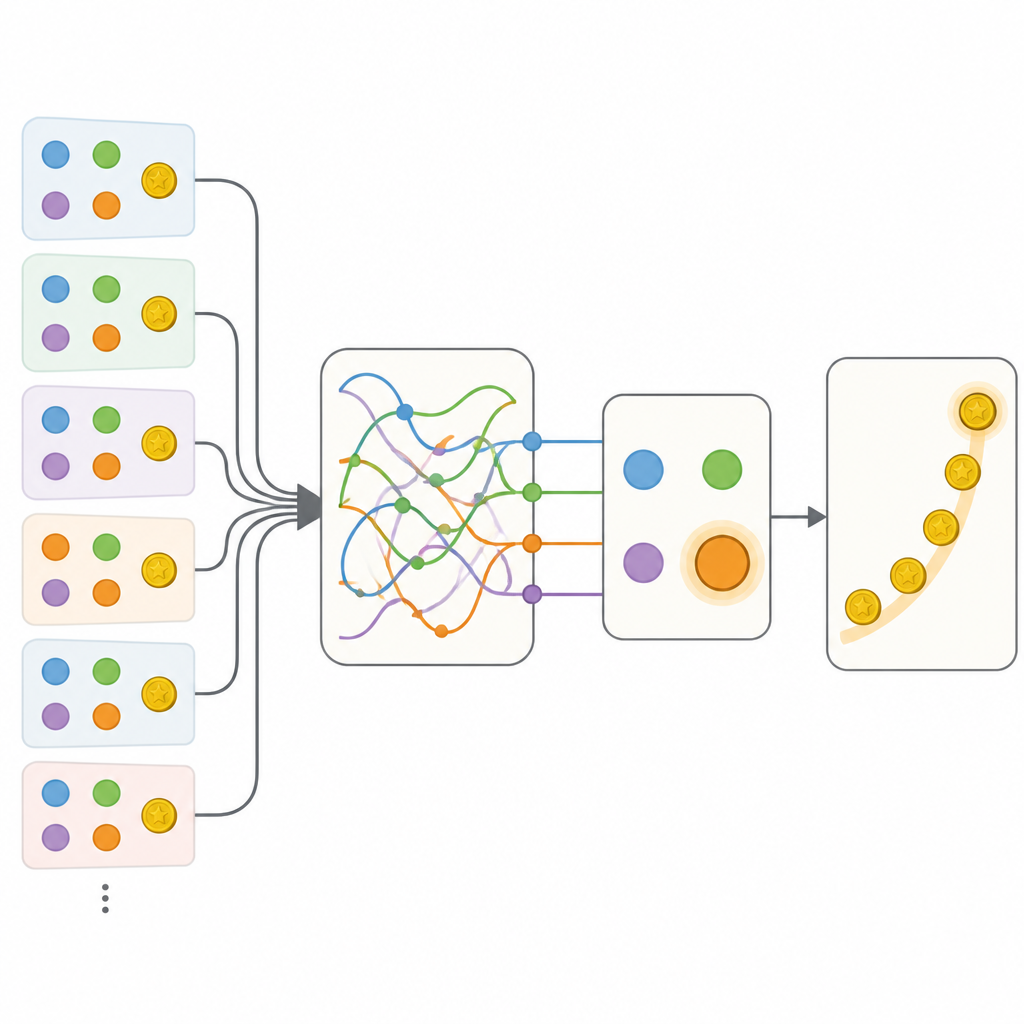
Was das für unser Belohnungslernen bedeutet
Die Ergebnisse legen nahe, dass sich menschliches Belohnungslernen nicht vollständig dadurch beschreiben lässt, einen einzelnen Wert für jede Option langsam anzupassen. Stattdessen scheinen unsere Gehirne reichere innere Aufzeichnungen darüber zu führen, was wann geschah, und diese Aufzeichnungen zu nutzen, um zu justieren, wie stark wir auf neue Gewinne und Verluste reagieren. Die Studie zeigt, dass die Kombination klassischer kognitiver Theorien mit neuronalen Netzen diese verborgene Struktur offenlegen kann und Modelle liefert, die sowohl große Datensätze gut erklären als auch Einblick in die mentalen Prozesse geben, die Alltagsentscheidungen steuern.
Zitation: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Schlüsselwörter: Belohnungslernen, menschliche Entscheidungsfindung, Gedächtnis, Verstärkungslernmodelle, rekurrente neuronale Netze