Clear Sky Science · fr
Des modèles hybrides neuraux–cognitifs révèlent comment la mémoire façonne l’apprentissage par récompense chez l’humain
Pourquoi les expériences passées comptent pour les choix quotidiens
Chaque fois que vous choisissez quel itinéraire emprunter, quel snack acheter ou quel site web cliquer, vous apprenez discrètement à partir des récompenses et déceptions passées. Les psychologues décrivent depuis longtemps cet apprentissage à l’aide de formules simples qui intègrent les résultats passés en un score unique pour chaque option. Cette étude examine si de tels récits épurés suffisent à expliquer la manière dont les vraies personnes apprennent des récompenses, et utilise des réseaux neuronaux modernes pour mettre au jour une image plus riche de la façon dont la mémoire influence nos choix.
Des scores simples à des mémoires plus riches
Les modèles classiques d’apprentissage par récompense, appelés modèles d’apprentissage par renforcement, supposent que chaque option que vous pouvez choisir est associée à une valeur unique et évolutive, mise à jour un peu après chaque résultat. Choisissez un snack, obtenez 70 points, et la valeur interne de ce snack monte progressivement ; obtenez 10 points, et elle baisse. Ces modèles ont eu une grande influence, reliant le comportement et l’activité cérébrale chez de nombreuses espèces. Pourtant, des résultats épars suggèrent qu’ils peuvent être trop simples. Les personnes peuvent accorder un poids particulier à des événements passés précis, sembler sensibles à l’éventail global des récompenses qu’elles ont observées, et montrer des signaux cérébraux qui ne correspondent pas nettement à une seule valeur cumulée.
Un grand jeu de hasard en ligne
Pour explorer ces questions, les chercheurs ont demandé à plus de 800 volontaires en ligne de jouer à un jeu informatique des centaines de fois. À chaque essai, les joueurs choisissaient l’une des quatre options colorées et voyaient immédiatement combien de points ils avaient gagnés. À leur insu, les gains véritables dérivaient lentement au fil du temps, de sorte que l’option la meilleure au début d’un jeu pouvait devenir médiocre plus tard. Sur plus de six cent mille essais, les personnes ont généralement appris à privilégier les choix les plus rémunérateurs, mais leurs schémas détaillés de changement de choix, d’enchaînements et d’exploration contenaient beaucoup plus de structure que ne pouvaient en rendre compte les modèles simples. 
Allier modèles lisibles et réseaux neuronaux
L’équipe a comparé plusieurs manières de décrire ce comportement. À une extrémité se trouvait un modèle traditionnel soigneusement ajusté, utilisant une poignée de nombres pour suivre les valeurs des options et une simple tendance à répéter ou changer d’action. À l’autre extrémité se trouvait un réseau neuronal récurrent flexible, une sorte de cerveau artificiel capable de stocker des informations riches sur le passé dans son état interne mais généralement difficile à interpréter. Comme prévu, le réseau neuronal prédisait bien mieux les choix des personnes que le modèle classique. L’étape clé a ensuite consisté à construire des modèles hybrides qui conservaient la structure transparente de l’approche classique, mais remplaçaient des éléments individuels par de petits réseaux neuronaux pouvant, en principe, apprendre toute règle cohérente avec les données.
Découvrir des états de mémoire cachés
Les premiers hybrides permettaient une mise à jour plus flexible des valeurs d’option et une sensibilité au contexte des options non choisies, mais ces ajouts restaient insuffisants par rapport au réseau neuronal complet. Le progrès décisif est venu avec un modèle appelé Memory-ANN. Ici, le système conservait des variables de mémoire distinctes qui stockaient un résumé riche des récompenses et des actions passées, séparées des variables plus simples qui guidaient directement le choix. Ces variables de mémoire étaient implémentées par de petits réseaux récurrents intégrés au modèle. Une fois ajusté sur les données, Memory-ANN égalait le pouvoir prédictif du réseau opaque tout en restant interprétable. L’analyse a montré que sa mémoire suivait à la fois l’historique des récompenses récentes et à long terme à plusieurs échelles temporelles, et ajustait la force avec laquelle de nouvelles récompenses influençaient les choix futurs. 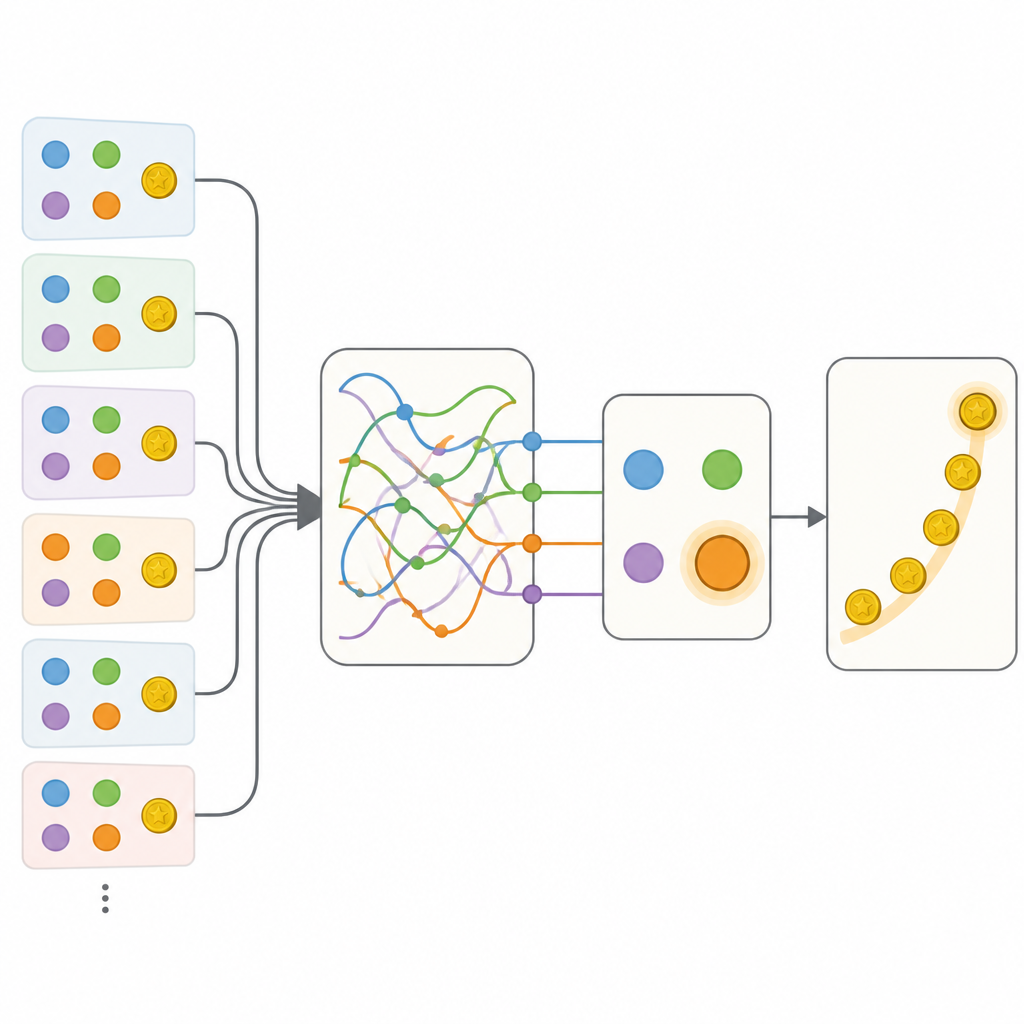
Ce que cela signifie pour notre apprentissage à partir des récompenses
Les résultats suggèrent que l’apprentissage par récompense humain ne peut pas être entièrement décrit comme l’ajustement lent d’un seul score par option. Au contraire, notre cerveau semble maintenir des enregistrements internes plus riches de ce qui s’est passé quand, et utilise ces traces pour moduler l’intensité de notre réaction aux nouvelles victoires et pertes. Ce travail montre que la combinaison des théories cognitives classiques avec des réseaux neuronaux peut révéler cette structure cachée, offrant des modèles qui s’ajustent à de grands jeux de données tout en éclairant les processus mentaux qui guident les décisions quotidiennes.
Citation: Eckstein, M.K., Summerfield, C., Daw, N.D. et al. Hybrid neural–cognitive models reveal how memory shapes human reward learning. Nat Hum Behav 10, 972–987 (2026). https://doi.org/10.1038/s41562-025-02324-0
Mots-clés: apprentissage par récompense, décision humaine, mémoire, modèles d’apprentissage par renforcement, réseaux neuronaux récurrents