Clear Sky Science · zh
一种带知识增强的多路径融合框架用于中国画的多模态命名实体识别
教计算机“读懂”中国画
博物馆的库房中如今保存着大量中国画的数字收藏——高分辨率图像配以详实说明——但大部分信息仍封存在非结构化文本和未标注的图片中。本研究展示了如何将图像分析、语言技术与文化知识结合起来,帮助计算机自动识别中国画中的关键人物、地点、时代与艺术特征,从而便于检索、研究与保护这一文化遗产。
为何中国画对机器而言更难
中国画不仅是绢本上的墨色;它将山水、人物、诗词、书法与印章交织在一起,浸透着历史语境。博物馆记录也反映了这种丰富性:冗长的说明中会提到朝代、画室、笔法和藏家,而图像则呈现山峦、亭台、植物与朱印。然而措辞常常含蓄而诗意。像“白石”这样一个词,视上下文可能指画面中的一块石头,也可能是某位著名画家的名字。现有的命名实体识别工具主要在新闻或社交媒体语料上训练,而非这一专业的艺术领域,因此它们容易漏掉许多文化特有的信息,也难以将文本与图像中出现的内容关联起来。
构建面向文物艺术的数据集
为了解决这一问题,作者首先构建了 CP‑MNER,这是一个聚焦中国画的新基准数据集。他们收集了1,188对高质量图文对,主要来自故宫博物院在线藏品,并辅以百科条目。经过自动清洗与人工校验后,每幅画的描述被规范化并与图像精细对齐。专家设计了一套包含16类实体的详细标注体系,反映艺术史的关切:不仅有 PERSON、TIME 与 LOCATION,还包括作品题目(ARTWORK)、印章题款(SEAL)、技法(TECHNIQUE)、材质(MATERIAL)、风格(STYLE)、植物(PLANT)、画中人物(FIGURE)等。通过两步流程——先用大型语言模型自动预标注,再由专家修正——他们标注了超过32,000个实体。每条说明平均约280个汉字和27个实体,使 CP‑MNER 成为一个密集且具有挑战性的测试平台。
新系统如何理解画作
基于该数据集,团队提出了 MFKA 框架,旨在通过融合三类信息流:文本、图像与外部知识,教计算机理解画作。首先,语言模型处理文本说明,同时深度视觉网络将画面分割为若干区域并提取视觉特征。随后通过跨模态交互步骤,使每个词能够“观察”图像中相关区域,从而生成对画面感知敏感的文本表示——例如在判断“白石”是指岩石还是人物时,这一机制非常有用。
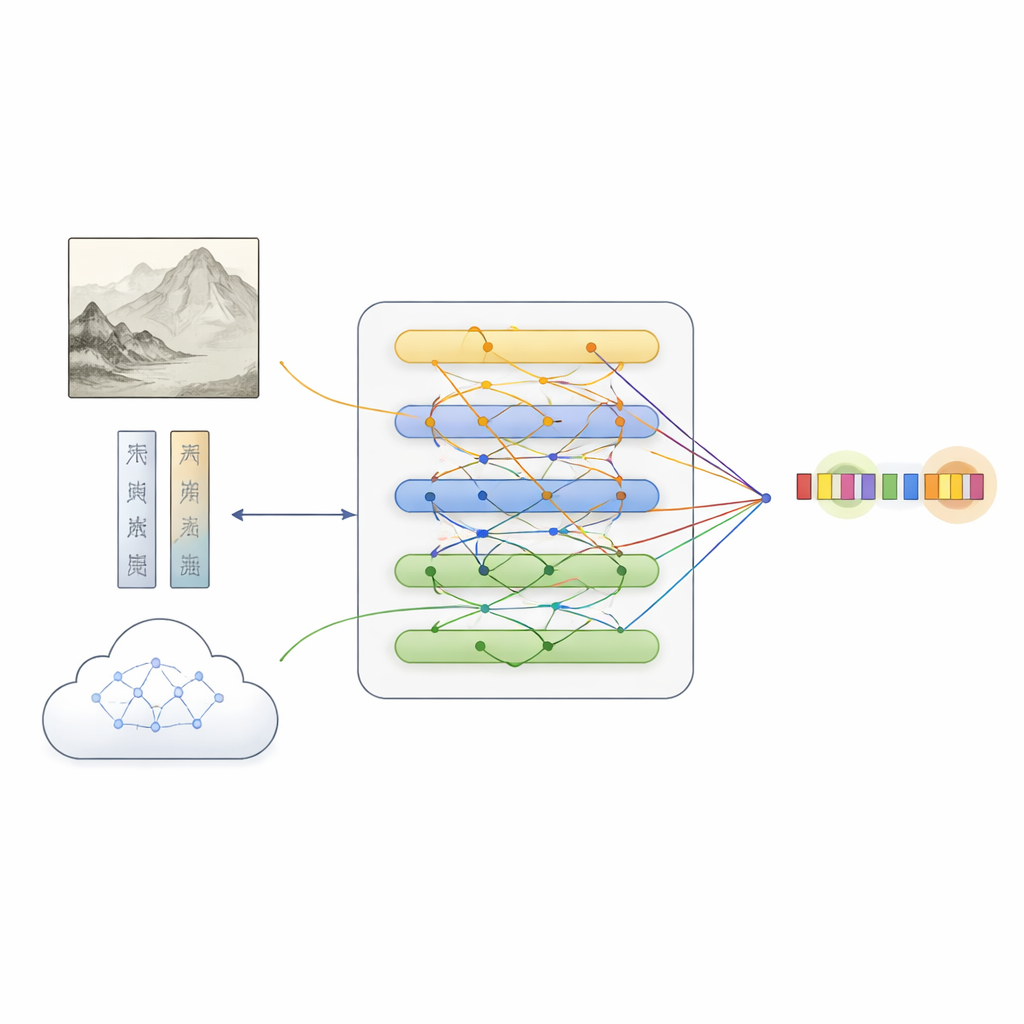
引入文化知识以填补空白
MFKA 更进一步,借助能够“看图读文”的多模态大型语言模型来提供文化知识。在第一阶段,这个辅助模型总结画面的关键视觉要素,如动物、植物、建筑或人物。第二阶段,它利用该摘要和文本说明列出可能出现的实体及其类型(例如某短语可能是画名、技法或印款)。这些辅助知识被转回文本形式,编码后通过注意力机制与原始说明融合。一个专门的融合模块随后在三条路径——纯文本、具有文本感知的图像特征和具有文本感知的知识——之间进行权衡,突出最有可能对应实体的词元,同时保留各来源的互补线索。
实验结果说明了什么
在 CP‑MNER 上的测试显示,MFKA 超过了多种领先的纯文本和多模态系统,获得了最高的总体 F1 得分(一项标准的准确率衡量)。它在那些依赖视觉上下文或文化提示的类别上表现特别优异,例如将动物与物体区分,或将像故宫博物院这样的组织识别为机构而非物理地点或建筑。详尽的消融实验表明,框架的每一部分——图文交互、知识增强与精细融合方案——均对性能提升有贡献,逐步去除这些组件会使性能回落到普通文本模型的水准。值得注意的是,MFKA 在一份无关的社交媒体数据集上也表现具有竞争力,表明其设计在艺术领域之外具有一定的泛化性。
对文化遗产的意义
对非专业读者而言,结论是作者已使计算机系统更像专家馆员一样“阅读”中国画:综合考虑书写内容、图像呈现与艺术史知识。他们公开的 CP‑MNER 数据集为未来研究提供了基准,MFKA 则表明将视觉线索与机器生成的文化知识结合,能解锁以前埋在博物馆记录中的细粒度信息。长远来看,这类工具可支持更智能的检索、更丰富的在线展览,以及连接艺术家、风格、材质与题材的庞大知识图谱,帮助学者与公众以新的方式探索中国画。
引用: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
关键词: 中国画, 多模态人工智能, 命名实体识别, 文化遗产, 知识图谱