Clear Sky Science · tr
Çok Yollu Bir Birleştirme ve Bilgi Zenginleştirme Çerçevesi ile Çin Resminde Çok Modlu Varlık Tanıma
Bilgisayarlara Çin Resimlerini Okutmak
Müze depoları artık yüksek çözünürlüklü görüntülerle zengin açıklamaların eşleştirildiği büyük dijital Çin resmi koleksiyonlarını barındırıyor; ancak bu bilgi çoğunlukla yapısal olmayan metinlerde ve etiketlenmemiş görüntülerde kilitli durumda. Bu çalışma, görüntü analizi, dil teknolojisi ve kültürel bilginin birleşiminin bilgisayarların Çin resimlerindeki önemli kişiler, mekânlar, dönemler ve sanat özelliklerini otomatik olarak tanımlamasına nasıl yardımcı olabileceğini gösteriyor; bu da bu mirası aramayı, incelemeyi ve korumayı kolaylaştırıyor.
Çin Resimlerinin Makineler İçin Neden Zor Olduğu
Çin resmi mürekkep üzerindeki bir çalışma olmanın ötesinde; peyzaj, figürler, şiir, hat ve mühürleri tarihsel bir bağlam içinde örer. Müze kayıtları bu zenginliği yansıtır: uzun açıklamalarda hanedanlar, atölyeler, fırça tekniği ve koleksiyonerler anılırken, görüntüler dağlar, köşkler, bitkiler ve kırmızı mühürler gösterir. Yine de anlatım çoğunlukla dolaylı ve şiirseldir. “Beyaz taş” gibi tek bir terim bağlama göre sahnedeki bir kayaya ya da ünlü bir ressamın adına işaret edebilir. Mevcut adlandırılmış varlık tanıma araçları—metindeki kişi, yer ve diğer varlıkları etiketleyen yazılımlar—genellikle genel haberler veya sosyal medya üzerinde eğitildi; bu nedenle bu özel sanat alanına özgü ayrıntıları kaçırır ve metinle görüntü arasındaki ilişkiyi kurmakta zorlanır.
Miras Sanata Özel Bir Veri Seti Oluşturmak
Bununla başa çıkmak için yazarlar önce Çin resmine odaklanan yeni bir kıyas veri seti olan CP‑MNER’i oluşturdu. Öncelikle Saray Müzesi’nin çevrimiçi koleksiyonundan ve ansiklopedi girdilerinden alınan 1.188 yüksek kaliteli görüntü‑metin çifti topladılar. Otomatik temizleme ve elle kontrollerin ardından her resmin açıklaması standartlaştırıldı ve dikkatle görüntüsüyle hizalandı. Uzmanlar daha sonra sanat tarihi kaygılarını yansıtan 16 ayrıntılı varlık türü belirledi: sadece KİŞİ, ZAMAN ve KONUM değil, aynı zamanda ESER başlıkları, MÜHÜR yazıtları, TEKNİK, MALZEME, ÜSLUP, BITKI, resimdeki ŞAHIS ve daha fazlası. İki aşamalı bir süreç—büyük bir dil modeliyle otomatik ön‑etiketleme ve ardından uzman düzeltmesi—kullanılarak 32.000’den fazla varlık etiketlendi. Her açıklama ortalama yaklaşık 280 Çin karakteri ve 27 varlık içeriyor; bu da CP‑MNER’i yoğun ve zorlu bir test zemini yapıyor.
Yeni Sistem Resimleri Nasıl Anlıyor
Bu veri setinin üzerine ekip, metin, görüntü ve dış bilgiyi harmanlayarak resimleri anlamayı öğreten MFKA adlı bir çerçeve önerdi. İlk olarak bir dil modeli açıklamayı işlerken, derin bir görsel ağ resmi bölgelere ayırır ve görsel özellikleri çıkarır. Ardından gerçekleşen çapraz‑modlu etkileşim adımı, her kelimenin görüntünün ilgili parçalarına “bakmasını” sağlar; bu, örneğin “beyaz taş” ifadesinin sahnedeki bir kaya mı yoksa bir kişiyi mi kastettiğine karar verirken yararlı olan, resimde ne olduğunun farkında olan metin temsilleri oluşturur.
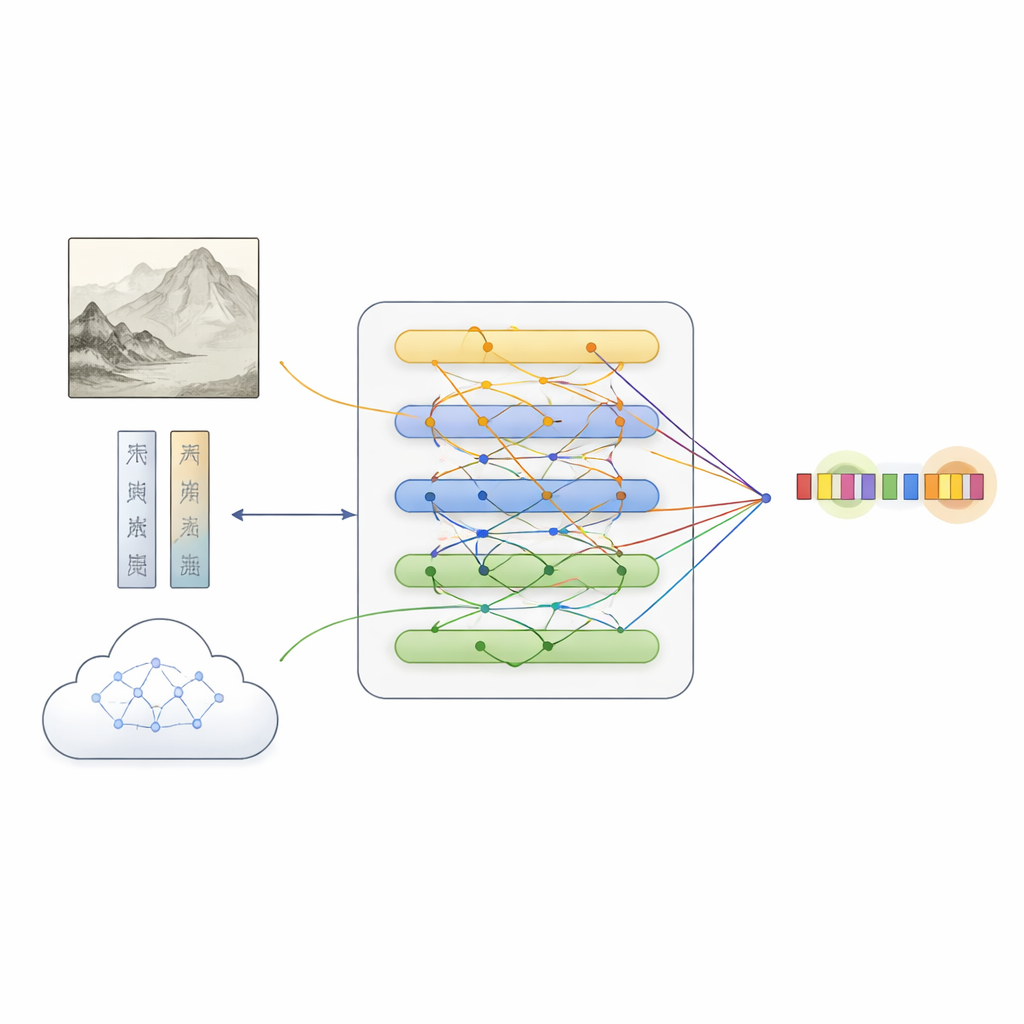
Boşlukları Doldurmak İçin Kültürel Bilgi Eklemek
MFKA, görselleri görebilen ve metni okuyabilen çok modlu bir büyük dil modelinden kültürel bilgi sağlamasını isteyerek bir adım daha ileri gider. İlk aşamada bu yardımcı model, hayvanlar, bitkiler, yapılar veya figürler gibi resmin ana görsel öğelerini özetler. İkinci aşamada bu özet ile açıklamayı kullanarak olası varlıkları ve türlerini listeler (örneğin belirli bir ifadenin bir resim başlığı, bir teknik veya bir mühür olduğunu). Bu yardımcı bilgi metne çevrilir, kodlanır ve dikkat mekanizmaları aracılığıyla orijinal açıklama ile birleştirilir. Uzmanlaşmış bir birleştirme modülü sonra üç yolu—düz metin, metnin farkında olan görsel özellikler ve metnin farkında olan bilgi—dengeleyerek her kaynaktan gelen tamamlayıcı ipuçlarını korurken varlıklarla en olası şekilde ilişkili tokenleri öne çıkarır.
Deneyler Ne Gösteriyor
CP‑MNER üzerinde test edildiğinde, MFKA metin‑sadece ve çok modlu çeşitli önde gelen sistemleri geride bırakarak en yüksek genel F1 skoruna (standart bir doğruluk ölçüsü) ulaştı. Görsel bağlamın veya kültürel ipuçlarının önemli olduğu kategorilerde—örneğin hayvanları nesnelerden ayırt etme veya Saray Müzesi gibi kuruluşları fiziksel yerlerden ya da binalardan ayırma—özellikle iyi performans gösterdi. Titiz yoklama çalışmaları çerçevenin her bölümünün—görüntü‑metin etkileşimi, bilgi zenginleştirme ve gelişmiş birleştirme şemasının—kazançlara katkıda bulunduğunu ve bunlar teker teker çıkarıldığında performansın yavaşça sıradan metin tabanlı modellere geri döndüğünü gösterdi. Önemli olarak, MFKA ilgisiz bir sosyal medya veri setinde de rekabetçi şekilde çalıştı; bu da tasarımının sanat dünyasının ötesinde esnek olduğunu düşündürüyor.
Kültürel Miras İçin Anlamı
Uzman olmayanlar için çıkarım şu: yazarlar bir bilgisayar sistemine Çin resimlerini bir küratörün yapacağı gibi, yazılı olanı, resmedileni ve sanat tarihi bilgisini birlikte değerlendirerek “okutmayı” başardı. CP‑MNER veri setleri gelecekteki çalışmalar için kamuya açık bir kıyas zemini sağlıyor ve MFKA görsel ipuçlarını makine‑tarafından üretilen kültürel bilgiyle birleştirmenin müze kayıtlarında daha önce gömülü olan ince ayrıntıları açığa çıkarabileceğini gösteriyor. Uzun vadede bu tür araçlar daha akıllı aramaları, zenginleştirilmiş çevrimiçi sergileri ve koleksiyonlar arasında sanatçılar, üsluplar, malzemeler ve motifleri birbirine bağlayan büyük bilgi grafiklerini destekleyerek hem araştırmacılara hem de kamuya Çin resmini yeni yollarla keşfetme olanağı sağlayabilir.
Atıf: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Anahtar kelimeler: Çin resmi, çok modlu yapay zeka, adlandırılmış varlık tanıma, kültürel miras, bilgi grafikleri