Clear Sky Science · ar
إطار دمج متعدد المسارات مع تعزيز معرفي للتعرّف عن الكيانات متعددة الأنماط في اللوحات الصينية
تعليم الحواسيب قراءة اللوحات الصينية
تحوي مخازن المتاحف اليوم مجموعات رقمية ضخمة من اللوحات الصينية—صور عالية الدقة مصحوبة بوصف تفصيلي—لكن معظم هذه المعلومات محتبسة في نصوص غير منظمة وصور غير معنونة. تُظهر هذه الدراسة كيف يمكن لدمج تحليل الصور وتقنيات اللغة والمعرفة الثقافية أن يساعد الحواسيب على تحديد الأشخاص والأماكن والفترات والسمات الفنية الرئيسة في اللوحات الصينية تلقائياً، مما يسهل البحث والدراسة والحفظ لهذا التراث.
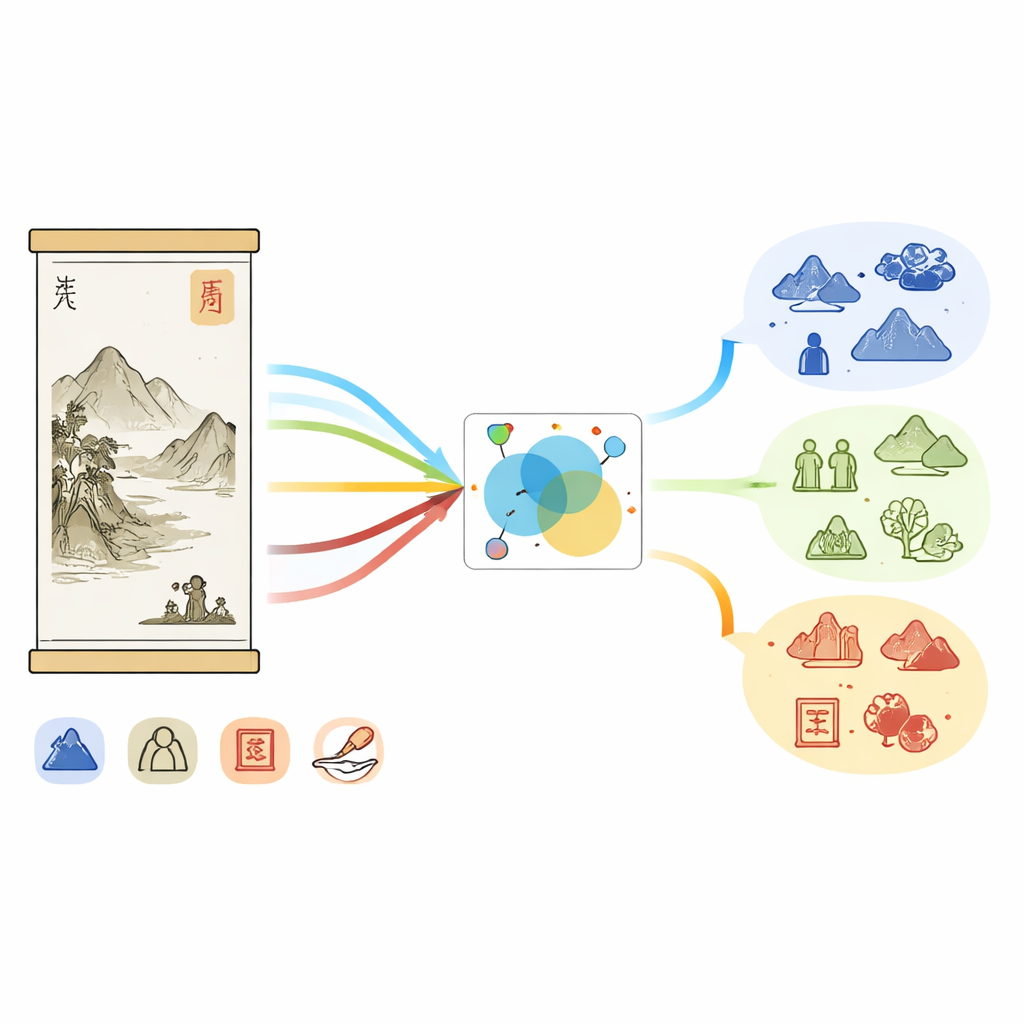
لماذا اللوحات الصينية صعبة على الآلات
اللوحة الصينية أكثر من حبر على حرير؛ إنها تجمع بين المناظر الطبيعية، والشخصيات، والشعر، والخط، والأختام، وكلها محمّلة بالتاريخ. تعكس سجلات المتاحف هذا الثراء: تذكر الأوصاف الطويلة السلالات والاستوديوهات وضربات الفرشاة وهويات الجامعين، بينما تعرض الصور جبالاً وأجنحة ونباتات وأختاماً حمراء. ومع ذلك، يكون الأسلوب في كثير من الأحيان غير مباشر وشاعري. فقد تشير عبارة واحدة مثل «الحجر الأبيض» إما إلى صخرة في المشهد أو إلى اسم رسام مشهور، بحسب السياق. الأدوات الحالية للتعرّف على الكيانات المسماة—البرمجيات التي تضع تسميات لأسماء الأشخاص والأماكن والكيانات الأخرى في النص—تدرّبت على أخبار عامة أو وسائل التواصل الاجتماعي، وليس على هذا المجال الفني المتخصص، لذلك تفشل في التقاط العديد من التفاصيل الثقافية الخاصة وتواجه صعوبة في ربط النص بما يظهر في الصورة.
بناء مجموعة بيانات مخصّصة لفن التراث
لمعالجة ذلك، أنشأ المؤلفون أولاً CP‑MNER، مجموعة معيارية جديدة تركز على اللوحة الصينية. جمعوا 1,188 زوجاً من الصور والنصوص عالية الجودة، معظمها من مجموعة المتحف الإمبراطوري على الإنترنت ومكمل بمداخل موسوعية. بعد تنظيف تلقائي وفحوص يدوية، تم توحيد وصف كل لوحة ومحاذاته بعناية مع صورتها. ثم صمّم الخبراء مجموعة مفصّلة من 16 نوعاً من الكيانات تعكس اهتمامات تاريخ الفن: ليس فقط PERSON وTIME وLOCATION، بل أيضاً عناوين الأعمال الفنية، ونقوش الأختام، والتقنية، والمادة، والطراز، والنبات، والشخصيات في الصورة، وغير ذلك. باستخدام عملية من خطوتين—توضيح تلقائي أولي بنموذج لغوي كبير يليه تصحيح خبير—وضعوا تسميات لأكثر من 32,000 كيان. يبلغ متوسط كل وصف نحو 280 حرفاً صينياً و27 كياناً، مما يجعل CP‑MNER قاعدة اختبار كثيفة وتحدّية.
كيف يفهم النظام الجديد اللوحات
بناءً على هذه المجموعة، اقترح الفريق MFKA، إطار عمل يعلّم الحواسيب فهم اللوحات عن طريق دمج ثلاثة مصادر للمعلومات: النص، والصورة، والمعرفة الخارجية. أولاً، يعالج نموذج لغوي الوصف، بينما يقسم نموذج رؤية عميق اللوحة إلى مناطق ويستخرج ميزات بصرية. ثم تسمح خطوة التفاعل عابر الوسائط لكل كلمة بـ«النظر إلى» أجزاء الصورة ذات الصلة، مما يخلق تمثيلات نصية واعية لما يظهر في اللوحة—وهو أمر مفيد، على سبيل المثال، عند تقرير ما إذا كانت عبارة «الحجر الأبيض» تشير إلى صخرة أو إلى شخص.
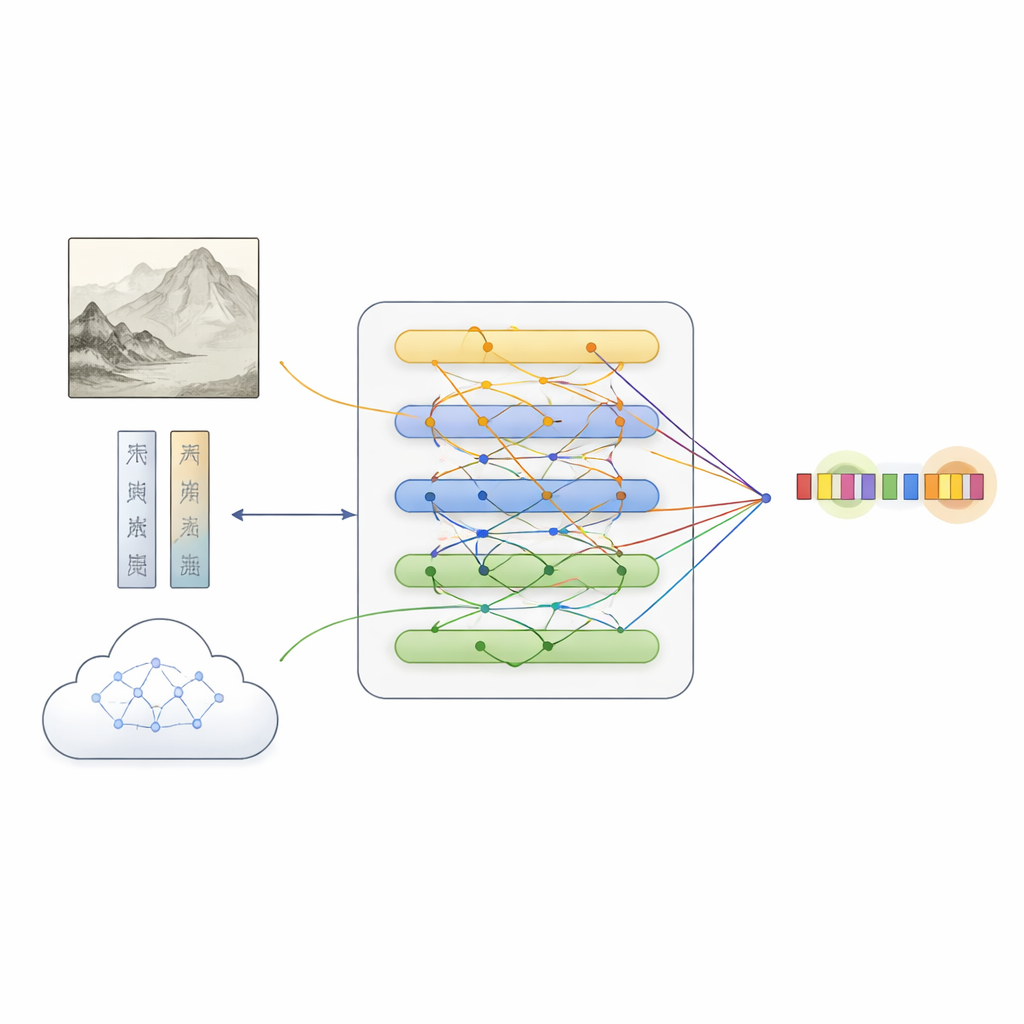
إضافة المعرفة الثقافية لسد الثغرات
يتقدم MFKA خطوةً أخرى بطلبه من نموذج لغوي كبير متعدد الأنماط—قادر على رؤية الصور وقراءة النص—تزويد النظام بالمعرفة الثقافية. في المرحلة الأولى، يلخّص هذا النموذج المساعد العناصر المرئية الأساسية في اللوحة، مثل الحيوانات والنباتات والمباني أو الشخصيات. في المرحلة الثانية، يستخدم ذلك الملخص مع الوصف لسرد الكيانات المحتملة وأنواعها (مثل أن عبارة معينة هي عنوان لوحة، أو تقنية، أو ختم). تُحوّل هذه المعرفة المساعدة إلى نص مرة أخرى، يُشفّر وتتم دمجه مع الوصف الأصلي عبر آليات الانتباه. ثم يوازن وحدة دمج مخصّصة بين المسارات الثلاثة—النص العادي، وميزات الصورة المدركة للنص، والمعرفة المدركة للنص—مضيئةً على الرموز التي من المرجح أن تمثل كيانات مع الحفاظ على الأدلة التكميلية من كل مصدر.
ماذا أظهرت التجارب
عند اختباره على CP‑MNER، تفوّق MFKA على مجموعة واسعة من النظم الرائدة المعتمدة على النص وحده وتلك متعددة الوسائط، محققاً أعلى درجة F1 إجمالية (مقياس دقة شائع). أدى أداءه بشكل خاص جيد في الفئات التي تهمها السياقات البصرية أو التلميحات الثقافية، مثل التمييز بين الحيوانات والأشياء، أو المؤسسات مثل المتحف الإمبراطوري مقابل الأماكن المادية أو المباني. أظهرت دراسات الإقصاء الدقيقة أن كل جزء من الإطار—التفاعل بين الصورة والنص، وتعزيز المعرفة، ونظام الدمج المتقدّم—ساهَم في المكاسب، وأن إزالتها دفعةً فدفعة أعادت الأداء تدريجياً نحو نماذج معتمدة على النص فقط. والأهم من ذلك، عمل MFKA أيضاً بمستوى تنافسي على مجموعة بيانات منفصلة من وسائل التواصل الاجتماعي، مما يشير إلى أن تصميمه مرن خارج عالم الفن.
ماذا يعني هذا للتراث الثقافي
بالنسبة لغير المختصين، الخلاصة أن المؤلفين علّموا نظاماً حاسوبياً «قراءة» اللوحات الصينية بطريقة أشبه بما يفعله أمين المعارض الخبير، عبر مراعاة ما كُتب وما رُسم وما هو معروف من تاريخ الفن بشكل مشترك. توفر مجموعة البيانات CP‑MNER معياراً عاماً للعمل المستقبلي، ويظهر MFKA أن الجمع بين الدلائل البصرية والمعرفة الثقافية المولّدة آلياً يمكن أن يكشف تفاصيل دقيقة كانت مدفونة سابقاً في سجلات المتاحف. على المدى الطويل، يمكن لمثل هذه الأدوات أن تغذي بحثاً أذكى، ومعارض إلكترونية أغنى، ورسومًا بيانية معرفية كبيرة تربط الفنانين والأنماط والمواد والزخارف عبر المجموعات، مما يساعد الباحثين والجمهور على حد سواء في استكشاف اللوحة الصينية بطرق جديدة.
الاستشهاد: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
الكلمات المفتاحية: اللوحة الصينية, الذكاء الاصطناعي متعدد الأنماط, التعرّف على الكيانات المسماة, التراث الثقافي, رسوم بيانية معرفية