Clear Sky Science · es
Un marco de fusión multipath con aumento de conocimiento para NER multimodal en la pintura china
Enseñar a los ordenadores a leer pinturas chinas
Los almacenes de los museos ahora contienen vastas colecciones digitales de pintura china: imágenes de alta resolución acompañadas por descripciones detalladas, pero gran parte de esta información está encerrada en textos no estructurados e imágenes sin etiquetar. Este estudio muestra cómo la combinación de análisis de imagen, tecnología del lenguaje y conocimiento cultural puede ayudar a los ordenadores a identificar automáticamente personas, lugares, periodos y rasgos artísticos clave en la pintura china, facilitando la búsqueda, el estudio y la preservación de este patrimonio.
Por qué las pinturas chinas son difíciles para las máquinas
La pintura china es más que tinta sobre seda; entrelaza paisaje, figuras, poesía, caligrafía y sellos, todo impregnado de historia. Los registros de los museos reflejan esta riqueza: largas descripciones mencionan dinastías, talleres, pinceladas y coleccionistas, mientras que las imágenes muestran montañas, pabellones, plantas y sellos rojos. Sin embargo, la redacción suele ser indirecta y poética. Un término como «piedra blanca» puede referirse a una roca en la escena o al nombre de un pintor célebre, según el contexto. Las herramientas existentes para el reconocimiento de entidades nombradas —software que etiqueta nombres de personas, lugares y otras entidades en el texto— se entrenaron con noticias o redes sociales generales, no en este dominio artístico especializado, por lo que pasan por alto muchos detalles culturales específicos y tienen dificultades para vincular el texto con lo que aparece en la imagen.
Construir un conjunto de datos adaptado al arte patrimonial
Para abordar esto, los autores crearon primero CP‑MNER, un nuevo conjunto de referencia centrado en la pintura china. Recolectaron 1.188 pares imagen‑texto de alta calidad, principalmente de la colección en línea del Palacio Imperial y complementados con entradas de enciclopedias. Tras una limpieza automática y verificaciones manuales, la descripción de cada pintura se estandarizó y se alineó cuidadosamente con su imagen. Expertos diseñaron entonces un conjunto detallado de 16 tipos de entidad que reflejan preocupaciones historiográficas del arte: no solo PERSONA, TIEMPO y LUGAR, sino también títulos de OBRA, inscripciones de SELLO, TÉCNICA, MATERIAL, ESTILO, PLANTA, FIGURA en la imagen y más. Mediante un proceso en dos pasos —preanotación automática con un gran modelo de lenguaje seguida de corrección experta— etiquetaron más de 32.000 entidades. Cada descripción promedia alrededor de 280 caracteres chinos y 27 entidades, lo que convierte a CP‑MNER en un banco de prueba denso y desafiante.
Cómo el nuevo sistema comprende las pinturas
Sobre este conjunto de datos, el equipo propuso MFKA, un marco que enseña a los ordenadores a entender las pinturas fusionando tres corrientes de información: texto, imagen y conocimiento externo. Primero, un modelo de lenguaje procesa la descripción, mientras que una red profunda de visión divide la pintura en regiones y extrae características visuales. Un paso de interacción cruzada multimodal permite entonces que cada palabra «mire» las partes relevantes de la imagen, creando representaciones textuales conscientes de lo que aparece en la pintura —útil, por ejemplo, para decidir si «piedra blanca» se refiere a una roca o a una persona.
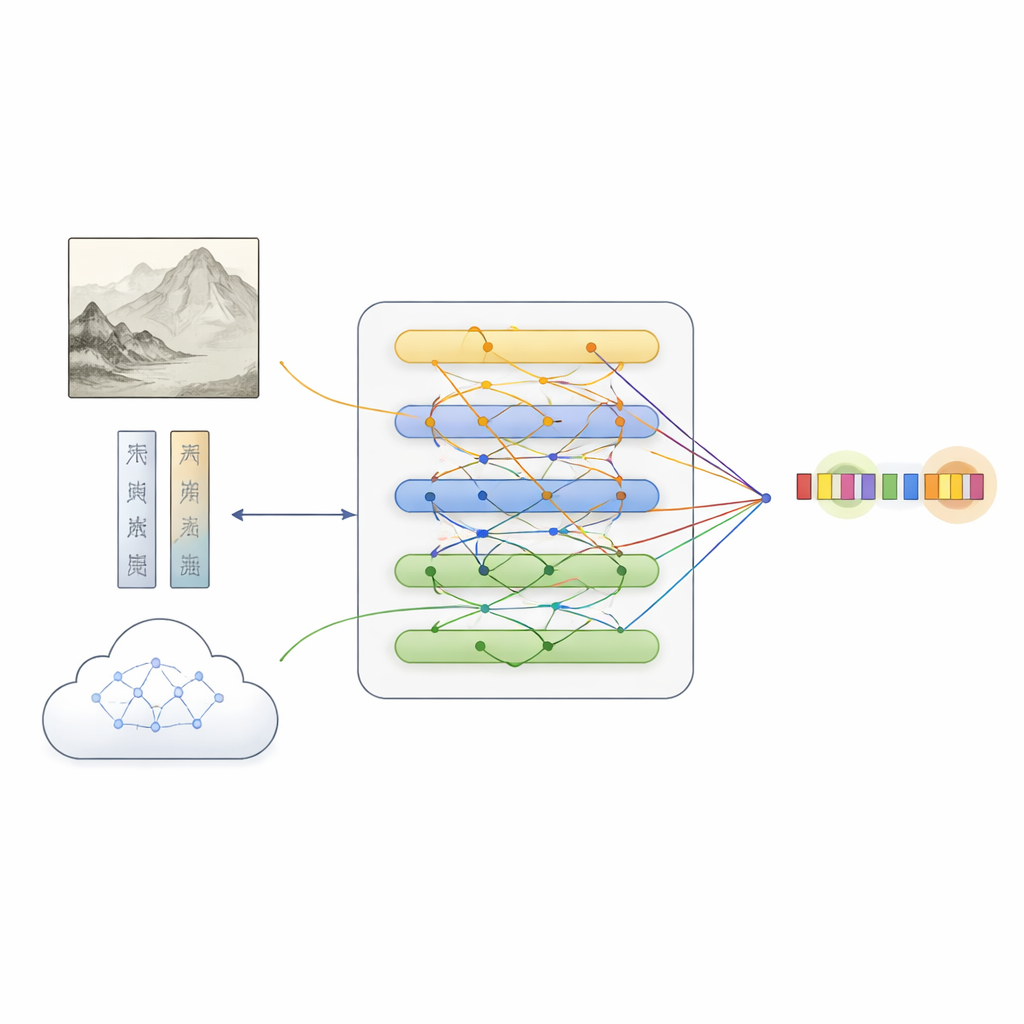
Agregar conocimiento cultural para cubrir las lagunas
MFKA va más allá pidiendo a un modelo multimodal grande —capaz de ver imágenes y leer texto— que aporte conocimiento cultural. En una primera etapa, este modelo auxiliar resume los elementos visuales clave de la pintura, como animales, plantas, edificios o figuras. En una segunda etapa, utiliza ese resumen más la descripción para listar las entidades probables y sus tipos (por ejemplo, que cierta expresión es el título de una pintura, una técnica o un sello). Este conocimiento auxiliar se convierte de nuevo en texto, se codifica y se fusiona con la descripción original mediante mecanismos de atención. Un módulo de fusión especializado equilibra luego las tres vías —texto puro, características de imagen conscientes del texto y conocimiento consciente del texto— destacando los tokens que con mayor probabilidad corresponden a entidades mientras preserva pistas complementarias de cada fuente.
Qué muestran los experimentos
Al evaluarse en CP‑MNER, MFKA superó a una amplia variedad de sistemas líderes solo de texto y multimodales, logrando la puntuación F1 global más alta (una medida estándar de precisión). Funcionó especialmente bien en categorías donde el contexto visual o las claves culturales importan, como distinguir animales de objetos, o instituciones como el Palacio Imperial frente a lugares o edificios físicos. Estudios de ablación cuidadosos mostraron que cada parte del marco —interacción imagen‑texto, aumento de conocimiento y el esquema sofisticado de fusión— contribuyó a las mejoras, y que su eliminación gradual devolvía el rendimiento hacia modelos ordinarios basados en texto. Es importante que MFKA también funcionara de forma competitiva en un conjunto de datos no relacionado procedente de redes sociales, lo que sugiere que su diseño es flexible más allá del ámbito artístico.
Qué significa esto para el patrimonio cultural
Para el público no especializado, la conclusión es que los autores han enseñado a un sistema informático a «leer» pinturas chinas de forma mucho más parecida a un conservador experto, considerando conjuntamente lo escrito, lo pintado y lo conocido por la historia del arte. Su conjunto de datos CP‑MNER proporciona un punto de referencia público para trabajos futuros, y MFKA demuestra que combinar señales visuales con conocimiento cultural generado por máquina puede desbloquear detalles de alta precisión que antes estaban enterrados en los registros de los museos. A largo plazo, estas herramientas podrían impulsar búsquedas más inteligentes, exposiciones en línea más ricas y grandes grafos de conocimiento que conecten artistas, estilos, materiales y motivos a través de colecciones, ayudando tanto a investigadores como al público a explorar la pintura china de nuevas maneras.
Cita: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Palabras clave: Pintura china, IA multimodal, reconocimiento de entidades nombradas, patrimonio cultural, grafos de conocimiento