Clear Sky Science · ru
Многопутевое слияние с расширением знаний для мультимодального NER в китайской живописи
Обучая компьютеры «читать» китайские картины
Хранилища музеев сегодня содержат огромные цифровые коллекции китайской живописи — изображения высокого разрешения в паре с подробными описаниями — но большая часть этой информации заперта в неструктурированном тексте и неразмеченных изображениях. В этом исследовании показано, как сочетание анализа изображений, языковых технологий и культурных знаний помогает компьютерам автоматически выявлять ключевых людей, места, эпохи и художественные особенности в китайских картинах, облегчая поиск, исследование и сохранение этого наследия.
Почему китайские картины трудны для машин
Китайская живопись — это не просто тушь на шелке; она объединяет пейзаж, фигуры, поэзию, каллиграфию и печати, все пропитано историей. Музейные записи отражают это богатство: длинные описания упоминают династии, мастерские, манеру письма и коллекционеров, а на изображениях видны горы, павильоны, растения и красные печати. При этом формулировки часто косвенные и поэтичные. Один термин, например «белый камень», в зависимости от контекста может означать либо камень в сцене, либо имя известного художника. Существующие инструменты распознавания именованных сущностей — программы, которые маркируют имена людей, мест и другие сущности в тексте — обучались на новостях или соцсетях, а не на специализированной художественной лексике, поэтому они пропускают многие культурно‑специфические детали и с трудом соотносят текст с тем, что видно на изображении.
Создание датасета, ориентированного на наследие
Чтобы решить эту задачу, авторы сначала создали CP‑MNER, новый эталонный датасет, сфокусированный на китайской живописи. Они собрали 1 188 качественных пар «изображение–текст», в основном из онлайн‑коллекции Запретного города и дополнительно из энциклопедий. После автоматической очистки и ручных проверок описания картин были стандартизованы и аккуратно выровнены с изображением. Эксперты затем разработали подробный набор из 16 типов сущностей, отражающих художественно‑исторические интересы: помимо PERSON, TIME и LOCATION — названия произведений (ARTWORK), надписи на печатях (SEAL), ТЕХНИКА, МАТЕРИАЛ, СТИЛЬ, РАСТЕНИЕ, ФИГУРА на картине и другие. С помощью двухэтапного процесса — автоматическая предразметка большой языковой моделью с последующей экспертной корректировкой — было размечено более 32 000 сущностей. Каждое описание в среднем содержит около 280 китайских символов и 27 сущностей, что делает CP‑MNER плотным и сложным полем для тестирования.
Как новая система «понимает» картины
На основе этого датасета команда предложила MFKA — framework, который учит компьютеры понимать картины путем слияния трех информационных потоков: текст, изображение и внешние знания. Сначала языковая модель обрабатывает описание, а глубокая визуальная сеть делит картину на регионы и извлекает визуальные признаки. Шаг кросс‑модального взаимодействия затем позволяет каждому слову «смотреть» на релевантные части изображения, создавая текстовые представления, учитывающие то, что изображено — полезно, например, при определении, означает ли «белый камень» камень или это имя человека.
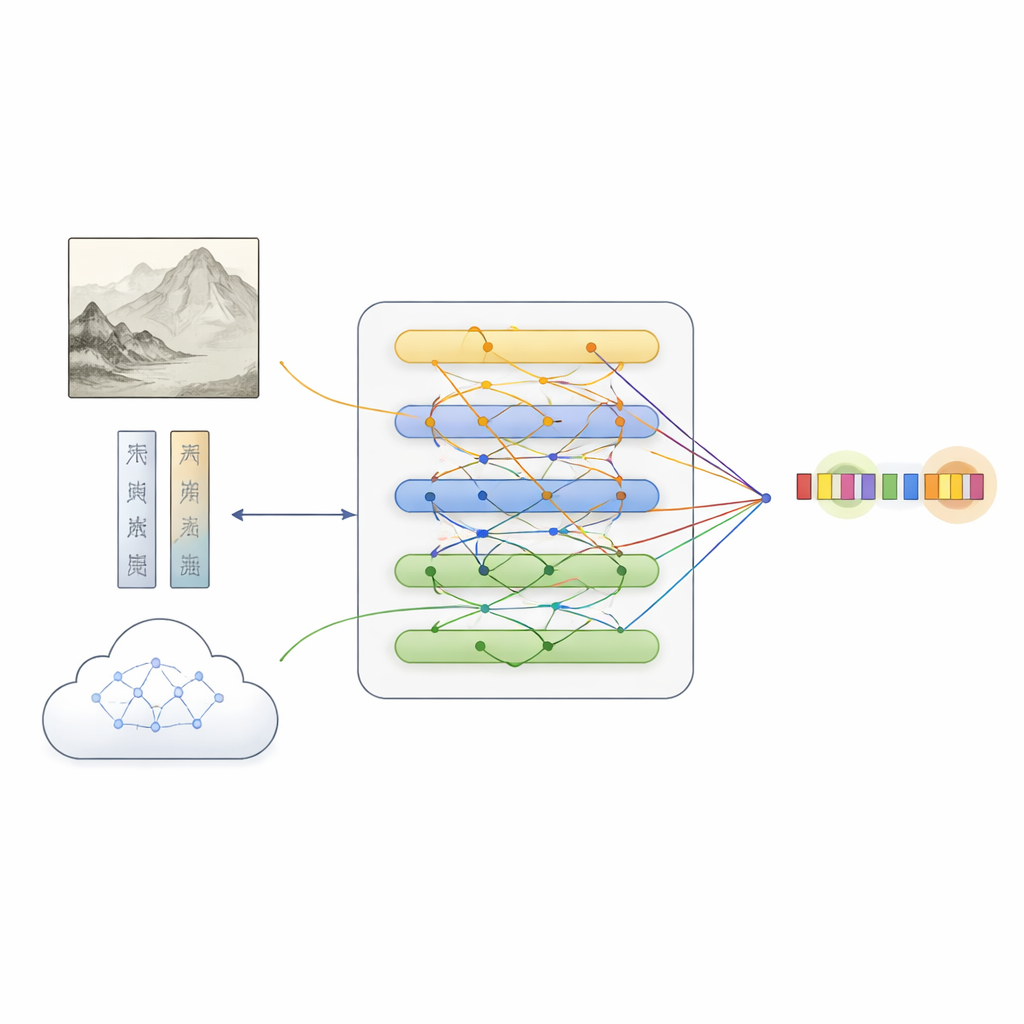
Добавление культурных знаний для восполнения пробелов
MFKA идет дальше, привлекая мультимодальную большую языковую модель — ту, что может «видеть» изображения и читать текст — чтобы она дополнила культурные знания. На первом этапе эта вспомогательная модель суммирует ключевые визуальные элементы картины, например животных, растения, здания или фигуры. На втором этапе, опираясь на это резюме и на описание, она перечисляет вероятные сущности и их типы (например, что некоторая фраза — название произведения, техника или печать). Эта вспомогательная информация преобразуется обратно в текст, кодируется и объединяется с исходным описанием посредством механизмов внимания. Специализированный модуль слияния затем балансирует три пути — чистый текст, визуальные признаки с учетом текста и текстово‑учитываемые знания — выделяя токены, которые наиболее вероятно соответствуют сущностям, одновременно сохраняя дополнительные подсказки из каждого источника.
Что показали эксперименты
При тестировании на CP‑MNER MFKA превзошла широкий круг передовых текстовых и мультимодальных систем, достигнув наилучшего общего F1‑балла (стандартная мера точности). Особенно хорошо модель показала себя в категориях, где важен визуальный контекст или культурные подсказки, например при различении животных и предметов или при отделении организаций вроде Запретного города от физических мест или зданий. Тщательные абляции показали, что каждая часть фреймворка — взаимодействие изображения и текста, расширение знаний и сложная схема слияния — вносит вклад в прирост, и что их поэтапное удаление постепенно выводит производительность к уровню обычных текстовых моделей. Важно, что MFKA также показала конкурентоспособные результаты на несвязанном датасете из социальных сетей, что указывает на гибкость её архитектуры за пределами художественной сферы.
Что это значит для сохранения культурного наследия
Для неспециалистов вывод таков: авторы научили компьютерную систему «читать» китайские картины гораздо более похоже на эксперта‑куратора, совместно учитывая написанное, изображенное и известное из истории искусства. Их датасет CP‑MNER предоставляет публичный эталон для будущих работ, а MFKA демонстрирует, что комбинирование визуальных подсказок с автоматически сгенерированными культурными знаниями может раскрыть тонкие детали, ранее скрытые в музейных записях. В перспективе такие инструменты могут обеспечить более умный поиск, более богатые онлайн‑выставки и крупные графы знаний, связывающие художников, стили, материалы и мотивы между коллекциями, помогая как ученым, так и широкой публике по‑новому исследовать китайскую живопись.
Цитирование: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Ключевые слова: китайская живопись, мультимодальный ИИ, распознавание именованных сущностей, культурное наследие, графы знаний