Clear Sky Science · pl
Wieloszczeblowe łączenie informacji z rozszerzeniem wiedzy dla multimodalnego NER w malarstwie chińskim
Nauczanie komputerów „czytania” malarstwa chińskiego
Magazyny muzealne przechowują dziś obszerne cyfrowe zbiory malarstwa chińskiego — obrazy w wysokiej rozdzielczości sparowane z bogatymi opisami — ale większość tych informacji jest uwięziona w niestrukturalnym tekście i nieotagowanych obrazach. W tym artykule pokazano, jak połączenie analizy obrazów, technologii językowych i wiedzy kulturowej może pomóc komputerom w automatycznym identyfikowaniu kluczowych osób, miejsc, okresów i cech artystycznych w malarstwie chińskim, ułatwiając wyszukiwanie, badania i ochronę tego dziedzictwa.
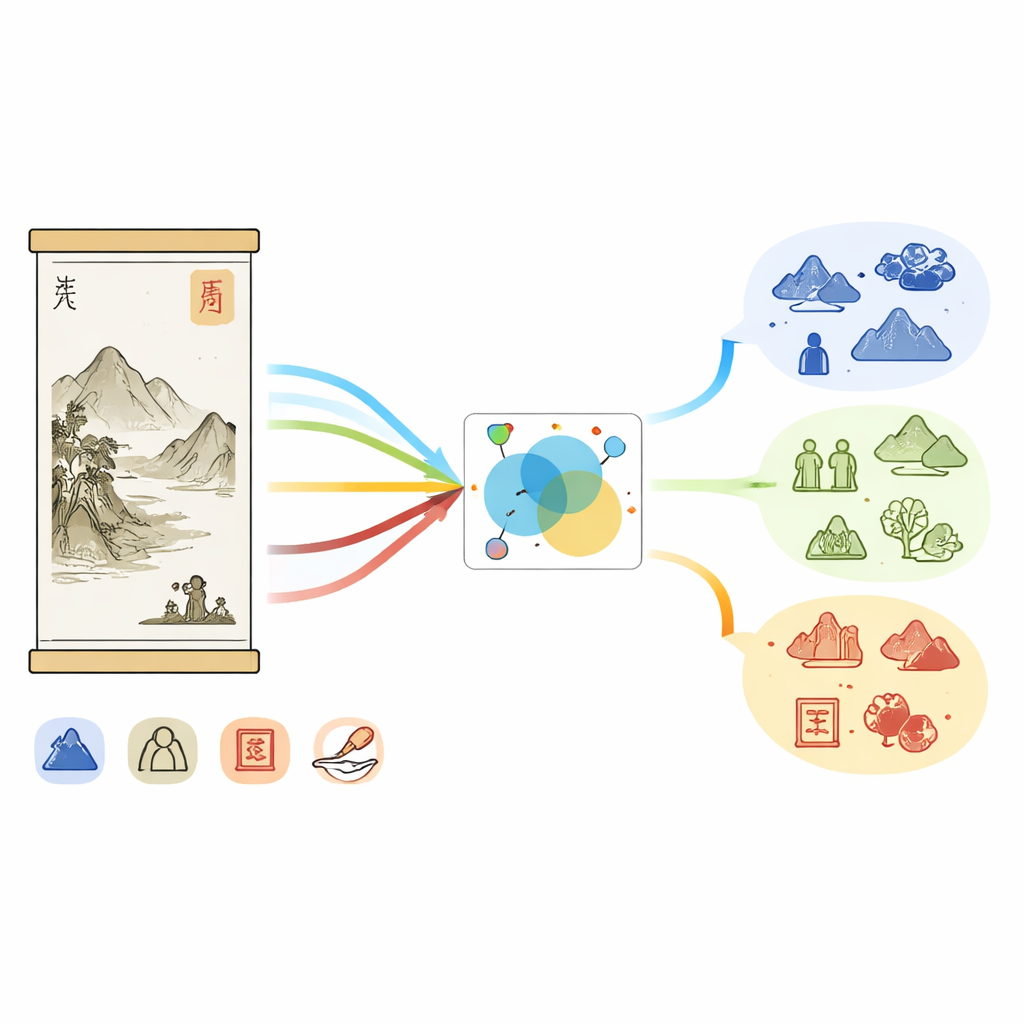
Dlaczego malarstwo chińskie jest trudne dla maszyn
Malarstwo chińskie to coś więcej niż tusz na jedwabiu; splata krajobraz, postacie, poezję, kaligrafię i pieczęci, wszystko przesiąknięte historią. Zapiski muzealne odzwierciedlają tę złożoność: długie opisy wymieniają dynastie, warsztaty, sposób pociągnięcia pędzla i kolekcjonerów, podczas gdy obrazy pokazują góry, pawilony, rośliny i czerwone pieczęci. Słownictwo jest często poetyckie i niejednoznaczne. Jeden termin, jak „biały kamień”, może odnosić się do skały w scenie lub do słynnego malarza — w zależności od kontekstu. Istniejące narzędzia do rozpoznawania nazwanych encji — oprogramowanie etykietujące imiona osób, miejsc i innych jednostek w tekście — były trenowane na ogólnych wiadomościach lub mediach społecznościowych, a nie w tej wyspecjalizowanej dziedzinie sztuki, dlatego pomijają wiele kulturowo specyficznych informacji i mają problem z łączeniem tekstu z tym, co widać na obrazie.
Budowa zestawu danych dostosowanego do dziedzictwa
Aby rozwiązać ten problem, autorzy najpierw stworzyli CP‑MNER, nowy benchmark skoncentrowany na malarstwie chińskim. Zebrali 1 188 wysokiej jakości par obraz–tekst, głównie z kolekcji online Pałacu Cesarskiego, uzupełnionych wpisami encyklopedycznymi. Po automatycznym oczyszczeniu i ręcznych kontrolach opis każdego obrazu został wystandaryzowany i starannie dopasowany do jego obrazu. Eksperci zaprojektowali szczegółowy zestaw 16 typów encji odzwierciedlających zagadnienia historii sztuki: nie tylko OSOBA, CZAS i MIEJSCE, lecz także TYTUŁ DZIEŁA, NAPISY NA PIECZĘCI, TECHNIKA, MATERIAŁ, STYL, ROŚLINA, POSTAĆ na obrazie i inne. Przy użyciu dwuetapowego procesu — automatycznej wstępnej adnotacji dużym modelem językowym, a następnie korekty eksperckiej — oznakowano ponad 32 000 encji. Każdy opis ma średnio około 280 chińskich znaków i 27 encji, co sprawia, że CP‑MNER jest gęstym i wymagającym polem testowym.
Jak nowy system rozumie obrazy
Na bazie tego zestawu zespół zaproponował MFKA, ramy uczące komputery rozumienia malarstwa poprzez fuzję trzech strumieni informacji: tekstu, obrazu i wiedzy zewnętrznej. Najpierw model językowy przetwarza opis, podczas gdy głęboka sieć wzrokowa dzieli obraz na regiony i wyciąga cechy wizualne. Krok interakcji międzymodalnej pozwala każdemu słowu „spojrzeć” na odpowiednie części obrazu, tworząc reprezentacje tekstu świadome tego, co znajduje się na malowidle — przydatne na przykład przy rozstrzyganiu, czy „biały kamień” odnosi się do skały, czy do osoby.
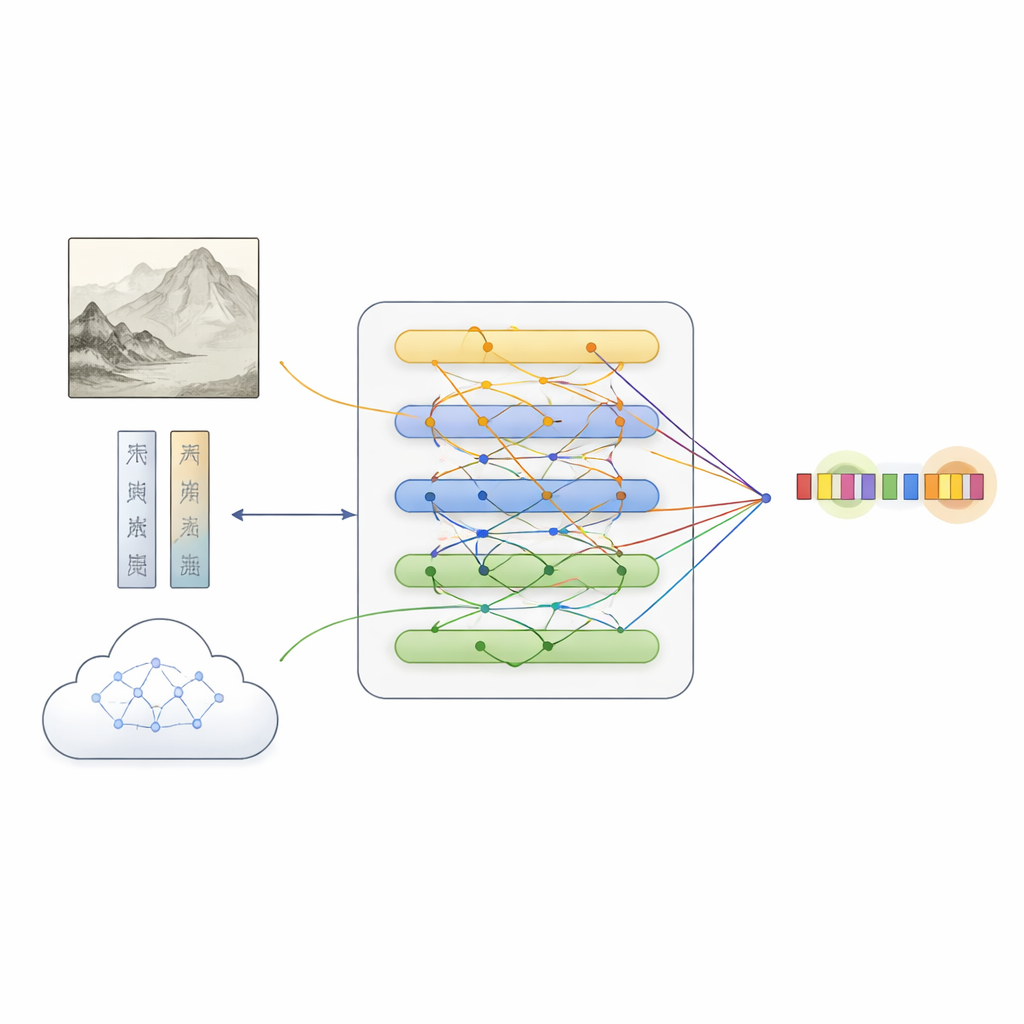
Dodawanie wiedzy kulturowej, by wypełnić luki
MFKA idzie dalej, prosząc multimodalny duży model językowy — taki, który potrafi „widzieć” obrazy i czytać tekst — o dostarczenie wiedzy kulturowej. W pierwszym etapie pomocniczy model streszcza kluczowe elementy wizualne obrazu, takie jak zwierzęta, rośliny, budowle czy postacie. W drugim etapie wykorzystuje to streszczenie wraz z opisem, aby wypisać prawdopodobne encje i ich typy (na przykład że pewne wyrażenie to tytuł obrazu, technika lub pieczęć). Ta dodatkowa wiedza jest zamieniana z powrotem na tekst, kodowana i scalana z oryginalnym opisem za pomocą mechanizmów uwagi. Specjalistyczny moduł fuzji następnie wyważa trzy ścieżki — czysty tekst, cechy obrazu uświadomione tekstowi oraz wiedzę uświadomioną tekstowi — uwypuklając tokeny, które najprawdopodobniej odpowiadają encjom, przy jednoczesnym zachowaniu komplementarnych wskazówek z każdego źródła.
Co pokazują eksperymenty
W testach na CP‑MNER MFKA przewyższył szeroką gamę czołowych systemów tylko‑tekstowych i multimodalnych, osiągając najwyższy łączny wynik F1 (standardowy miernik trafności). Szczególnie dobrze radził sobie w kategoriach, gdzie kontekst wizualny lub podpowiedzi kulturowe mają znaczenie, na przykład przy rozróżnieniu zwierząt od przedmiotów czy organizacji, takich jak Pałac Cesarski, od miejsc fizycznych lub budynków. Dokładne badania abla pokazują, że każda część ram — interakcja obraz‑tekst, rozszerzenie wiedzy i wyrafinowany schemat fuzji — przyczynia się do poprawy wyników, a ich stopniowe usuwanie cofało wydajność w stronę zwykłych modeli tekstowych. Co ważne, MFKA działał także konkurencyjnie na niezwiązanym zbiorze z mediów społecznościowych, co sugeruje, że jego projekt jest elastyczny poza światem sztuki.
Znaczenie dla dziedzictwa kulturowego
Dla osób niebędących specjalistami główny wniosek jest taki, że autorzy nauczyli system komputerowy „czytać” malarstwo chińskie znacznie bardziej jak ekspert‑kurator, równocześnie rozważając to, co napisane, co namalowane i co wiadomo z historii sztuki. Ich zestaw CP‑MNER stanowi publiczny benchmark dla przyszłych badań, a MFKA pokazuje, że łączenie wskazówek wizualnych z maszynowo wygenerowaną wiedzą kulturową może odsłonić drobne szczegóły wcześniej ukryte w zapisach muzealnych. W dłuższej perspektywie takie narzędzia mogłyby zasilać inteligentniejsze wyszukiwania, bogatsze wystawy online i rozbudowane grafy wiedzy łączące artystów, style, materiały i motywy w kolekcjach, pomagając zarówno badaczom, jak i publiczności odkrywać malarstwo chińskie na nowe sposoby.
Cytowanie: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Słowa kluczowe: malarstwo chińskie, sztuczna inteligencja multimodalna, rozpoznawanie nazwanych encji, dziedzictwo kulturowe, grafy wiedzy