Clear Sky Science · en
A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting
Teaching Computers to Read Chinese Paintings
Museum storerooms now hold vast digital collections of Chinese paintings—high‑resolution images paired with rich descriptions—but most of this information is locked away in unstructured text and unlabeled pictures. This study shows how combining image analysis, language technology, and cultural knowledge can help computers automatically identify key people, places, periods, and artistic features in Chinese paintings, making it easier to search, study, and preserve this heritage.
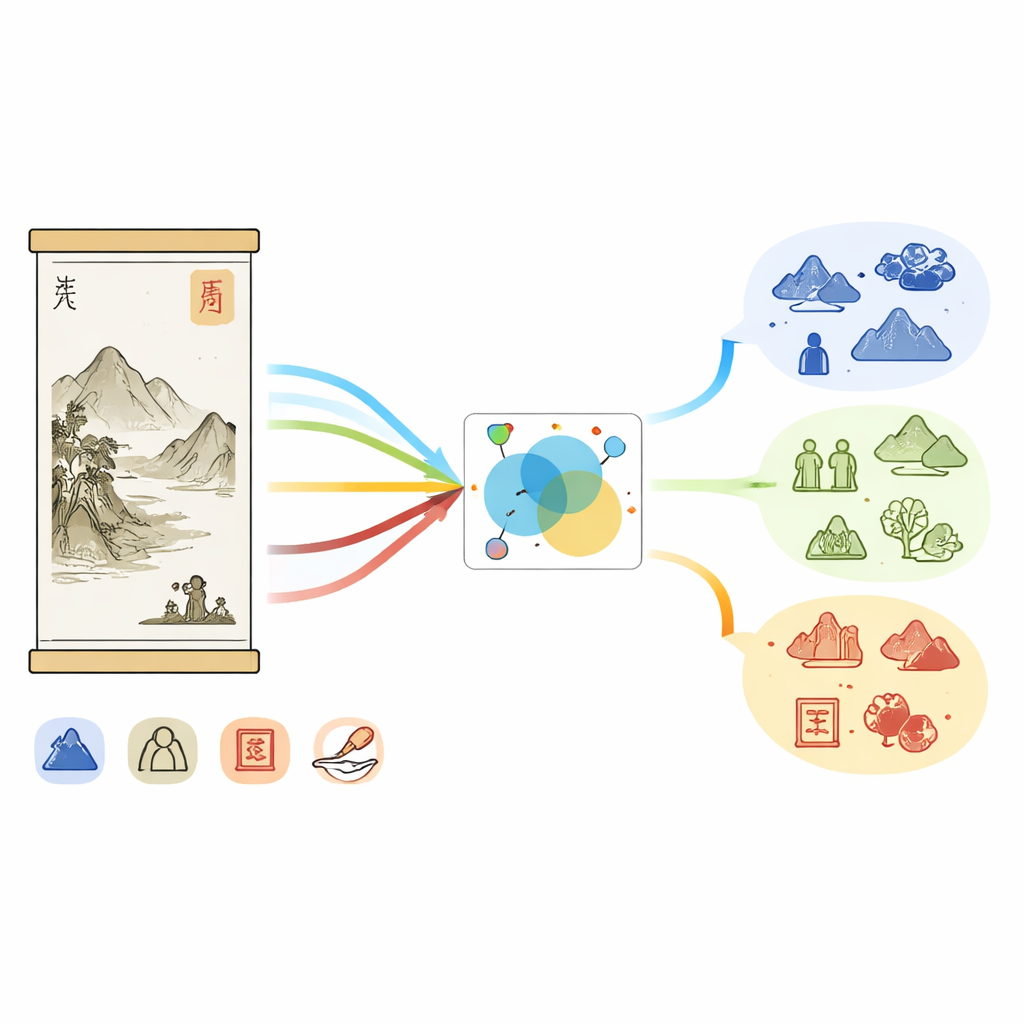
Why Chinese Paintings Are Hard for Machines
Chinese painting is more than ink on silk; it weaves together landscape, figures, poetry, calligraphy, and seals, all steeped in history. Museum records mirror this richness: long descriptions mention dynasties, studios, brushwork, and collectors, while the images display mountains, pavilions, plants, and red seals. Yet the wording is often indirect and poetic. A single term like “white stone” might refer either to a rock in the scene or to a famous painter’s name, depending on context. Existing tools for named entity recognition—software that labels names of people, places, and other entities in text—were trained on general news or social media, not on this specialized art domain, so they miss many culturally specific details and struggle to link text with what appears in the image.
Building a Dataset Tailored to Heritage Art
To tackle this, the authors first created CP‑MNER, a new benchmark dataset focused on Chinese painting. They collected 1,188 high‑quality image–text pairs, mainly from the Palace Museum’s online collection and supplemented by encyclopedia entries. After automatic cleaning and manual checks, each painting’s description was standardized and carefully aligned with its image. Experts then designed a detailed set of 16 entity types that reflect art‑historical concerns: not only PERSON, TIME, and LOCATION, but also ARTWORK titles, SEAL inscriptions, TECHNIQUE, MATERIAL, STYLE, PLANT, FIGURE in the picture, and more. Using a two‑step process—automatic pre‑annotation with a large language model followed by expert correction—they labeled more than 32,000 entities. Each description averages about 280 Chinese characters and 27 entities, making CP‑MNER a dense and challenging testbed.
How the New System Understands Paintings
On top of this dataset, the team proposed MFKA, a framework that teaches computers to understand paintings by fusing three information streams: text, image, and external knowledge. First, a language model processes the description, while a deep vision network divides the painting into regions and extracts visual features. A cross‑modal interaction step then lets each word “look at” relevant parts of the image, creating text representations that are aware of what appears in the painting—useful, for example, when deciding whether “white stone” refers to a rock or to a person.
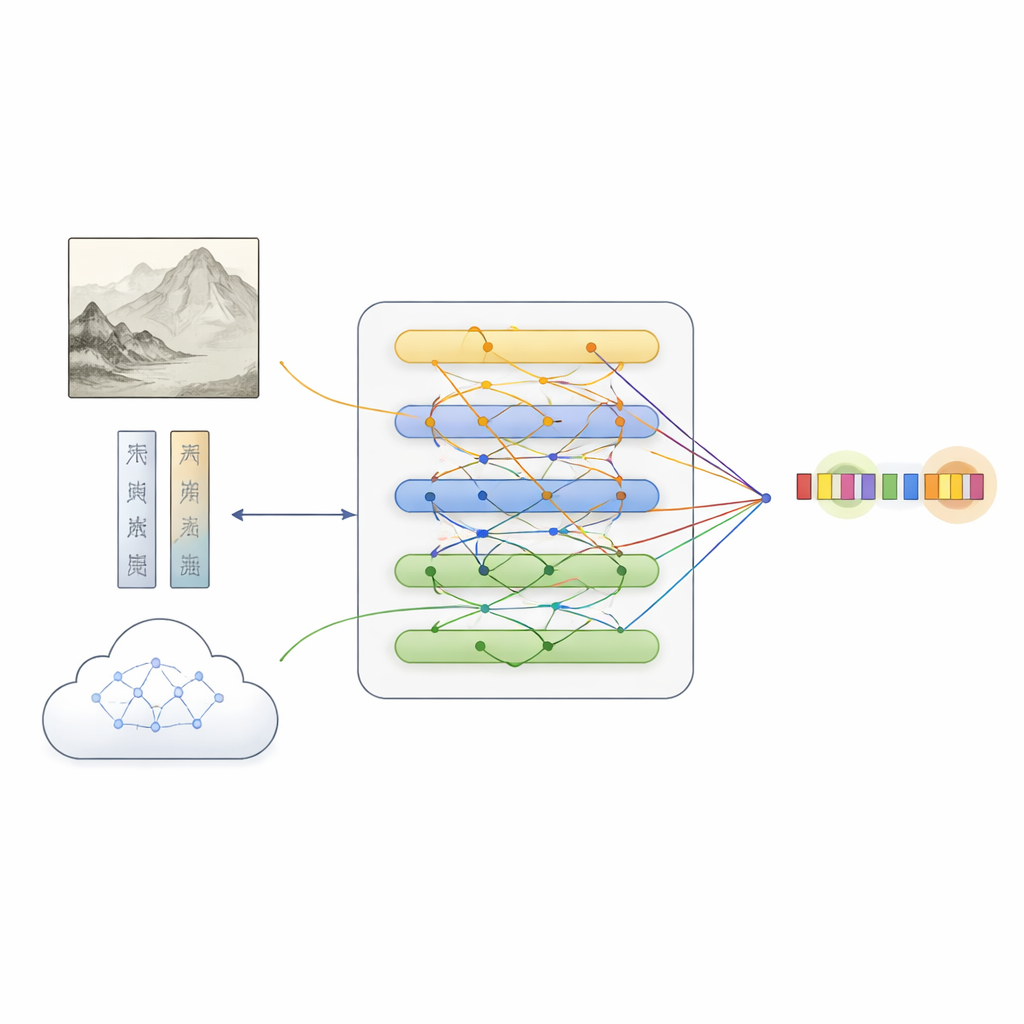
Adding Cultural Knowledge to Fill in the Gaps
MFKA goes further by asking a multimodal large language model—one that can see images and read text—to supply cultural knowledge. In a first stage, this helper model summarizes the key visual elements of the painting, such as animals, plants, buildings, or figures. In a second stage, it uses that summary plus the description to list likely entities and their types (for instance, that a certain phrase is a painting title, a technique, or a seal). This auxiliary knowledge is turned back into text, encoded, and merged with the original description through attention mechanisms. A specialized fusion module then balances the three paths—plain text, text‑aware image features, and text‑aware knowledge—highlighting tokens that most likely correspond to entities while preserving complementary clues from each source.
What the Experiments Show
When tested on CP‑MNER, MFKA outperformed a wide range of leading text‑only and multimodal systems, achieving the highest overall F1 score (a standard accuracy measure). It did especially well on categories where visual context or cultural hints matter, such as distinguishing animals from objects, or organizations like the Palace Museum from physical places or buildings. Careful ablation studies showed that each part of the framework—image–text interaction, knowledge augmentation, and the sophisticated fusion scheme—contributed to the gains, and that removing them gradually pushed performance back toward ordinary text‑based models. Importantly, MFKA also worked competitively on an unrelated social‑media dataset, suggesting its design is flexible beyond the art world.
What This Means for Cultural Heritage
For non‑specialists, the takeaway is that the authors have taught a computer system to “read” Chinese paintings much more like an expert curator would, by jointly considering what is written, what is painted, and what is known from art history. Their CP‑MNER dataset provides a public benchmark for future work, and MFKA shows that combining visual cues with machine‑generated cultural knowledge can unlock fine‑grained details that were previously buried in museum records. In the long run, such tools could power smarter search, richer online exhibitions, and large knowledge graphs that connect artists, styles, materials, and motifs across collections, helping both scholars and the public explore Chinese painting in new ways.
Citation: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Keywords: Chinese painting, multimodal AI, named entity recognition, cultural heritage, knowledge graphs