Clear Sky Science · sv
En flervägsfusionsram med kunskapsaugmentering för multimodal NER i kinesisk målarkonst
Lära datorer att läsa kinesiska målningar
Museiförråd rymmer nu omfattande digitala samlingar av kinesiska målningar—högupplösta bilder parvis med rika beskrivningar—men större delen av denna information är låst i ostrukturerad text och oetiketterade bilder. Denna studie visar hur imageanalys, språkteknologi och kulturhistorisk kunskap kan kombineras för att hjälpa datorer att automatiskt identifiera viktiga personer, platser, perioder och konstnärliga drag i kinesiska målningar, vilket underlättar sökning, studier och bevarande av detta arv.
Varför kinesiska målningar är svåra för maskiner
Kinesisk målarkonst är mer än bläck på siden; den väver ihop landskap, figurer, poesi, kalligrafi och sigill, allt genomsyrat av historia. Museiregister speglar denna rikedom: långa beskrivningar nämner dynastier, ateljéer, penselföring och samlare, medan bilderna visar berg, paviljonger, växter och röda sigill. Samtidigt är språket ofta indirekt och poetiskt. Ett enda uttryck som “vit sten” kan syfta antingen på en klippa i scenen eller på namnet på en berömd målare, beroende på kontext. Befintliga verktyg för namnidentifiering—program som märker ut namn på personer, platser och andra enheter i text—är tränade på allmänna nyheter eller sociala medier, inte på detta specialiserade konstområde, så de missar många kulturspecifika detaljer och har svårt att länka text med vad som syns i bilden.
Skapa en dataset anpassad till kulturarvskonst
För att tackla detta skapade författarna först CP‑MNER, en ny benchmarksdataset fokuserad på kinesisk målarkonst. De samlade 1 188 högkvalitativa bild‑textpar, främst från Palatsmuseets onlinekollektion och kompletterade med uppslagsverksinlägg. Efter automatisk rensning och manuella kontroller standardiserades varje målningbeskrivning och anpassades noggrant till bilden. Experter designade därefter en detaljerad uppsättning av 16 entitetstyper som speglar konsthistoriska intressen: inte bara PERSON, TID och PLATS, utan även VERKstitlar, SIGILLinskrifter, TEKNIK, MATERIAL, STIL, VÄXT, FIGUR i bilden med mera. Genom en tvåstegsprocess—automatisk förannotering med en stor språkmodell följt av expertkorrigering—märkte de över 32 000 entiteter. Varje beskrivning är i genomsnitt cirka 280 kinesiska tecken och 27 entiteter, vilket gör CP‑MNER till ett tätt och utmanande testfält.
Hur det nya systemet förstår målningar
Ovanpå denna dataset föreslog teamet MFKA, en ram som lär datorer att förstå målningar genom att fusio nera tre informationsströmmar: text, bild och extern kunskap. Först bearbetar en språkmodell beskrivningen, medan ett djupt visionsnätverk delar upp målningen i regioner och extraherar visuella funktioner. Ett tvärmodalt interaktionssteg låter sedan varje ord “titta på” relevanta delar av bilden och skapar textrepresentationer som är medvetna om vad som syns i målningen—nyttigt, till exempel när man ska avgöra om “vit sten” avser en sten eller en person.
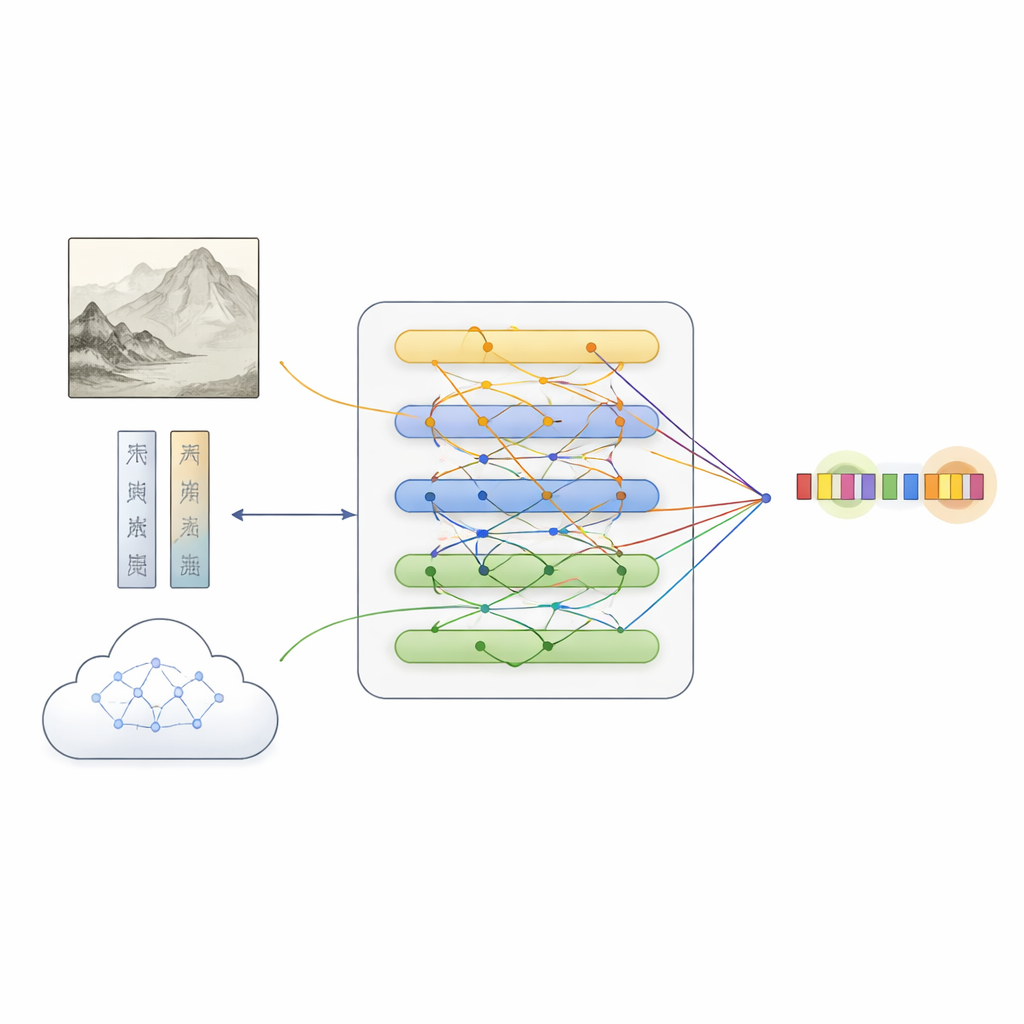
Lägga till kulturhistorisk kunskap för att fylla luckor
MFKA går längre genom att be en multimodal stor språkmodell—en som kan se bilder och läsa text—att tillföra kulturkunskap. I ett första steg sammanfattar denna hjälparmodell de viktigaste visuella elementen i målningen, såsom djur, växter, byggnader eller figurer. I ett andra steg använder den den sammanfattningen plus beskrivningen för att lista troliga enheter och deras typer (till exempel att en viss fras är en verkstitel, en teknik eller ett sigill). Denna kompletterande kunskap omvandlas tillbaka till text, kodas och slås ihop med originalbeskrivningen via attentionsmekanismer. En specialiserad fusionsmodul balanserar sedan de tre vägarna—ren text, textmedvetna bildfunktioner och textmedveten kunskap—genom att framhäva token som mest sannolikt motsvarar entiteter samtidigt som kompletterande ledtrådar från varje källa bevaras.
Vad experimenten visar
När MFKA testades på CP‑MNER överträffade den en rad ledande endast‑text och multimodala system och uppnådde den högsta totala F1‑poängen (en standardmätning för noggrannhet). Den presterade särskilt bra i kategorier där visuell kontext eller kulturhistoriska antydningar spelar roll, såsom att skilja djur från föremål, eller organisationer som Palatsmuseet från fysiska platser eller byggnader. Noggranna ablationsstudier visade att varje del av ramen—bild–textinteraktion, kunskapsaugmentering och den sofistikerade fusionsschemat—bidrog till förbättringarna, och att borttagning av dem gradvis pressade prestandan tillbaka mot vanliga textbaserade modeller. Viktigt är att MFKA också fungerade konkurrenskraftigt på en orelaterad sociala‑medier‑dataset, vilket tyder på att dess design är flexibel bortom konstvärlden.
Vad detta betyder för kulturarvet
För lekmän är slutsatsen att författarna har lärt ett datorsystem att “läsa” kinesiska målningar mycket mer som en expertkurator skulle göra, genom att gemensamt beakta vad som är skrivet, vad som är målat och vad som är känt från konsthistorien. Deras CP‑MNER‑dataset erbjuder en offentlig benchmark för framtida arbete, och MFKA visar att kombinationen av visuella ledtrådar med maskingenererad kulturkunskap kan låsa upp finfördelade detaljer som tidigare var begravda i museiregister. På längre sikt skulle sådana verktyg kunna driva smartare sökningar, rikare onlineutställningar och stora kunskapsgrafer som kopplar samman konstnärer, stilar, material och motiv över samlingar, vilket hjälper både forskare och allmänheten att utforska kinesisk målarkonst på nya sätt.
Citering: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Nyckelord: Kinesisk målarkonst, multimodal AI, namnidentifiering, kulturarv, kunskapsgrafer