Clear Sky Science · it
Un framework di fusione multi-percorso con arricchimento di conoscenza per NER multimodale nella pittura cinese
Insegnare ai computer a «leggere» le pitture cinesi
I depositi dei musei conservano oggi vaste collezioni digitali di pitture cinesi—immagini ad alta risoluzione abbinate a descrizioni ricche—ma la maggior parte di queste informazioni è nascosta in testi non strutturati e immagini non etichettate. Questo studio mostra come la combinazione di analisi delle immagini, tecnologie linguistiche e conoscenze culturali possa aiutare i computer a identificare automaticamente persone, luoghi, periodi e caratteristiche artistiche chiave nelle pitture cinesi, rendendo più semplice cercare, studiare e preservare questo patrimonio.
Perché le pitture cinesi sono difficili per le macchine
La pittura cinese è più che inchiostro su seta; intreccia paesaggio, figure, poesia, calligrafia e sigilli, il tutto immerso nella storia. I documenti dei musei rispecchiano questa ricchezza: lunghe descrizioni menzionano dinastie, botteghe, pennellate e collezionisti, mentre le immagini mostrano montagne, padiglioni, piante e sigilli rossi. Tuttavia il linguaggio è spesso indiretto e poetico. Un singolo termine come “pietra bianca” potrebbe riferirsi a una roccia nella scena oppure al nome di un pittore famoso, a seconda del contesto. Gli strumenti esistenti per il riconoscimento delle entità nominate—software che etichetta nomi di persone, luoghi e altre entità nel testo—sono stati addestrati su notizie generali o social media, non su questo dominio artistico specializzato; così perdono molti dettagli culturalmente specifici e faticano a collegare il testo con quanto appare nell’immagine.
Costruire un dataset su misura per l’arte del patrimonio
Per affrontare il problema, gli autori hanno innanzitutto creato CP‑MNER, un nuovo dataset di riferimento focalizzato sulla pittura cinese. Hanno raccolto 1.188 coppie immagine–testo di alta qualità, principalmente dalla collezione online del Museo del Palazzo e integrate con voci enciclopediche. Dopo pulizia automatica e controlli manuali, la descrizione di ogni dipinto è stata standardizzata e accuratamente allineata con la sua immagine. Esperti hanno quindi progettato un insieme dettagliato di 16 tipi di entità che riflettono preoccupazioni storico‑artistiche: non solo PERSONA, TEMPO e LUOGO, ma anche titoli di OPERE, iscrizioni di SIGILLI, TECNICA, MATERIALE, STILE, PIANTA, FIGURA nella scena e altro. Utilizzando un processo in due fasi—pre‑annotazione automatica con un grande modello linguistico seguita da correzione esperta—hanno etichettato più di 32.000 entità. Ogni descrizione conta in media circa 280 caratteri cinesi e 27 entità, rendendo CP‑MNER un banco di prova denso e impegnativo.
Come il nuovo sistema comprende le pitture
Sopra questo dataset, il team ha proposto MFKA, un framework che insegna ai computer a comprendere le pitture fondendo tre flussi informativi: testo, immagine e conoscenza esterna. Innanzitutto un modello linguistico elabora la descrizione, mentre una rete visiva profonda divide il dipinto in regioni ed estrae caratteristiche visive. Un passaggio di interazione cross‑modale permette poi a ciascuna parola di “guardare” le parti rilevanti dell’immagine, creando rappresentazioni testuali consapevoli di ciò che appare nel dipinto—utile, ad esempio, per decidere se “pietra bianca” si riferisca a una roccia o a una persona.
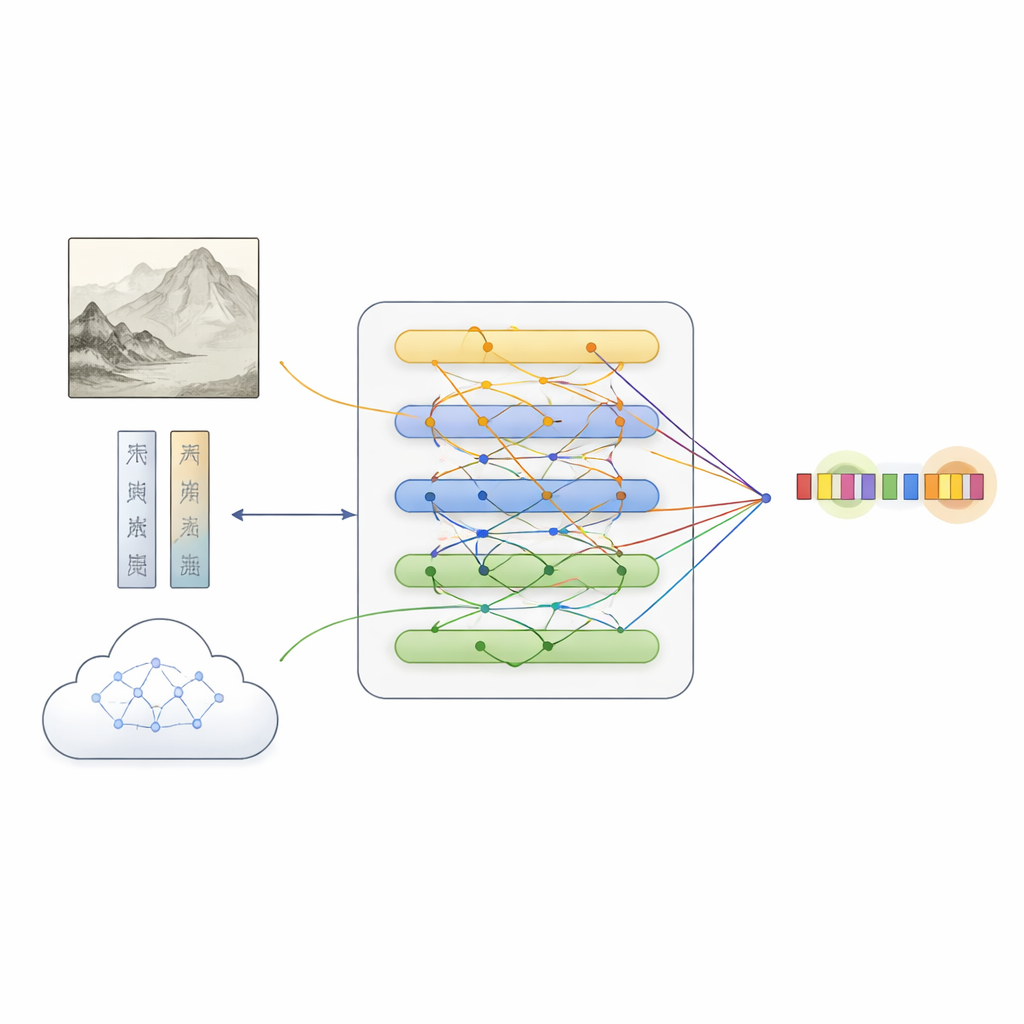
Aggiungere conoscenza culturale per colmare le lacune
MFKA va oltre chiedendo a un grande modello linguistico multimodale—capace di vedere immagini e leggere testo—di fornire conoscenze culturali. In una prima fase, questo modello ausiliario riassume gli elementi visuali chiave del dipinto, come animali, piante, edifici o figure. In una seconda fase, usa quel riassunto insieme alla descrizione per elencare le entità probabili e i loro tipi (per esempio, che una certa frase è il titolo di un’opera, una tecnica o un sigillo). Questa conoscenza ausiliaria viene trasformata di nuovo in testo, codificata e fusa con la descrizione originale tramite meccanismi di attenzione. Un modulo di fusione specializzato quindi bilancia i tre percorsi—testo puro, caratteristiche visive con consapevolezza del testo e conoscenza con consapevolezza del testo—mettendo in risalto i token che più probabilmente corrispondono a entità pur preservando indizi complementari da ciascuna fonte.
Cosa mostrano gli esperimenti
Testato su CP‑MNER, MFKA ha superato un’ampia gamma di sistemi all’avanguardia solo testuali e multimodali, ottenendo il punteggio F1 complessivo più alto (una misura standard di accuratezza). Ha performato particolarmente bene in categorie dove il contesto visivo o gli indizi culturali contano, come distinguere animali da oggetti, o organizzazioni come il Museo del Palazzo da luoghi fisici o edifici. Studi di ablazione accurati hanno mostrato che ciascuna parte del framework—interazione immagine–testo, arricchimento di conoscenza e lo schema di fusione sofisticato—ha contribuito ai miglioramenti, e che rimuoverle gradualmente riporta le prestazioni verso modelli ordinari basati solo sul testo. Importante, MFKA ha funzionato in modo competitivo anche su un dataset di social media non correlato, suggerendo che il suo design è flessibile oltre il mondo dell’arte.
Cosa significa per il patrimonio culturale
Per i non specialisti, la conclusione è che gli autori hanno insegnato a un sistema informatico a “leggere” le pitture cinesi molto più come farebbe un curatore esperto, considerando congiuntamente ciò che è scritto, ciò che è dipinto e ciò che è noto dalla storia dell’arte. Il loro dataset CP‑MNER fornisce un benchmark pubblico per lavori futuri, e MFKA dimostra che combinare indizi visivi con conoscenza culturale generata dalla macchina può sbloccare dettagli fini che prima erano sepolti nei documenti museali. A lungo termine, tali strumenti potrebbero alimentare ricerche più intelligenti, mostre online più ricche e grandi grafi di conoscenza che collegano artisti, stili, materiali e motivi attraverso le collezioni, aiutando sia gli studiosi sia il pubblico a esplorare la pittura cinese in modi nuovi.
Citazione: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Parole chiave: Pittura cinese, IA multimodale, riconoscimento delle entità nominate, patrimonio culturale, grafi di conoscenza