Clear Sky Science · de
Ein Mehrpfad‑Fusionsrahmen mit Wissensaugmentierung für multimodales NER in chinesischer Malerei
Computern beibringen, chinesische Gemälde zu „lesen“
Magazin‑ und Museumsdepots beherbergen heute umfangreiche digitale Sammlungen chinesischer Malerei – hochauflösende Bilder, ergänzt durch ausführliche Beschreibungen. Ein Großteil dieser Information liegt jedoch in unstrukturiertem Text und unmarkierten Bildern verborgen. Diese Studie zeigt, wie die Kombination von Bildanalyse, Sprachtechnologie und kulturhistorischem Wissen Computern helfen kann, automatisch zentrale Personen, Orte, Zeiträume und gestalterische Merkmale in chinesischen Gemälden zu identifizieren, wodurch Suche, Forschung und Bewahrung dieses Erbes erleichtert werden.
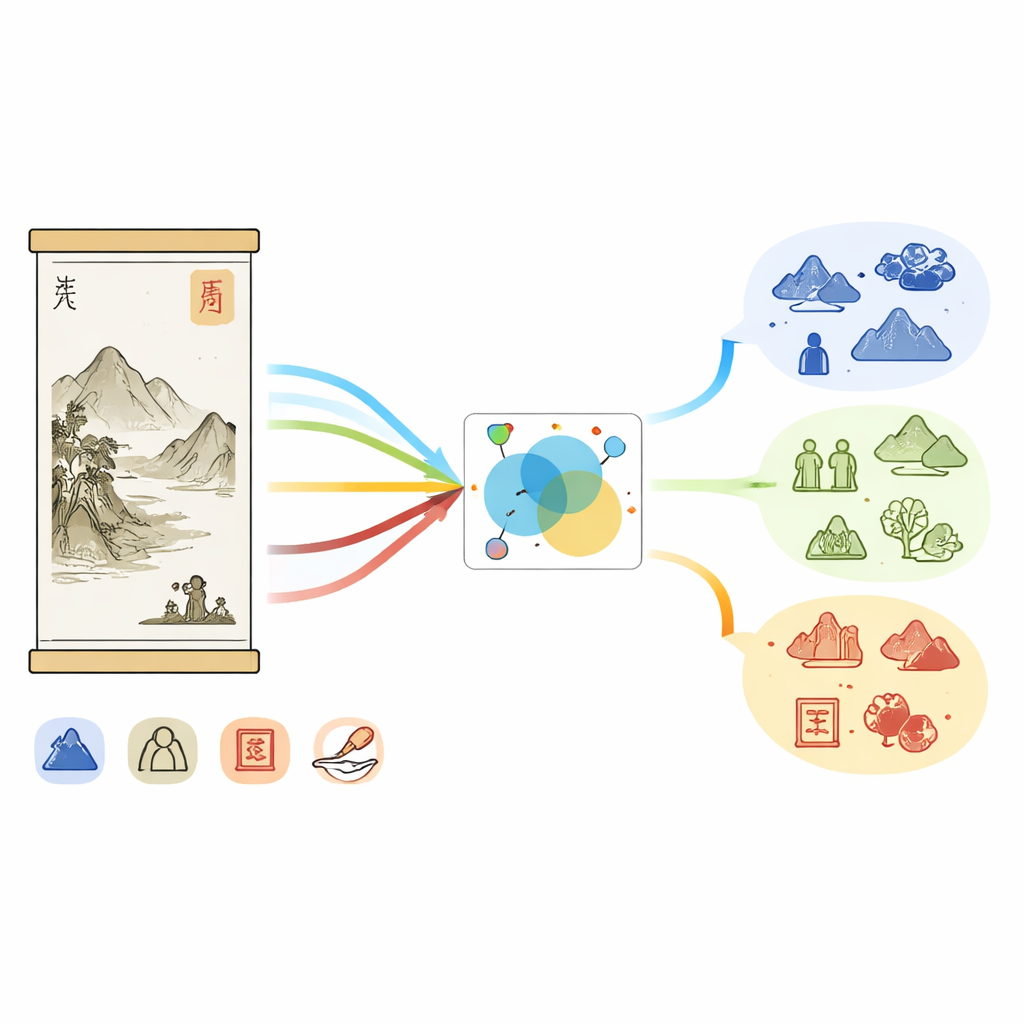
Warum chinesische Malerei für Maschinen schwierig ist
Chinesische Malerei ist mehr als Tusche auf Seide; sie verwebt Landschaft, Figuren, Poesie, Kalligraphie und Siegel, stets in historischen Kontexten. Museumsaufzeichnungen spiegeln diese Vielfalt wider: lange Beschreibungen nennen Dynastien, Ateliers, Pinseltechniken und Sammler, während die Bilder Berge, Pavillons, Pflanzen und rote Siegel zeigen. Die Sprache ist oft indirekt und poetisch. Ein Begriff wie „weißem Stein“ kann je nach Kontext entweder einen im Bild dargestellten Felsen oder den Namen eines berühmten Malers bezeichnen. Bestehende Werkzeuge zur Erkennung benannter Entitäten – Software, die Personen-, Orts‑ und Sachnamen im Text markiert – wurden auf allgemeinen Nachrichten oder sozialen Medien trainiert, nicht auf dieses spezialisierte Kunstfeld. Deshalb übersehen sie viele kulturspezifische Details und tun sich schwer, Text und Bildinhalte zu verknüpfen.
Ein Datensatz, zugeschnitten auf kulturerhaltende Kunst
Die Autorinnen und Autoren schufen dafür zunächst CP‑MNER, einen neuen Benchmark‑Datensatz mit Fokus auf chinesische Malerei. Sie sammelten 1.188 hochwertige Bild‑Text‑Paare, vorwiegend aus der Online‑Sammlung des Palastmuseums und ergänzt durch Enzyklopädieeinträge. Nach automatischer Bereinigung und manueller Prüfung wurden die Beschreibungen standardisiert und sorgfältig an die Bilder angeglichen. Expertinnen und Experten entwarfen anschließend ein detailliertes Set von 16 Entitätstypen, das kunsthistorische Belange abbildet: nicht nur PERSON, ZEIT und ORT, sondern auch WERKtiteln, SIEGELinschriften, TECHNIK, MATERIAL, STIL, PFLANZE, FIGUR im Bild und mehr. Mit einem zweistufigen Prozess – automatische Vorannotation durch ein großes Sprachmodell, gefolgt von Expertenkorrektur – kennzeichneten sie über 32.000 Entitäten. Jede Beschreibung umfasst im Durchschnitt etwa 280 chinesische Schriftzeichen und 27 Entitäten, womit CP‑MNER ein dichtes und anspruchsvolles Testfeld darstellt.
Wie das neue System Gemälde versteht
Auf diesem Datensatz baut das Team MFKA auf, einen Rahmen, der Computern beibringt, Gemälde zu verstehen, indem er drei Informationsströme fusioniert: Text, Bild und externes Wissen. Zuerst verarbeitet ein Sprachmodell die Beschreibung, während ein tiefes Visionsnetz das Gemälde in Regionen unterteilt und visuelle Merkmale extrahiert. Ein cross‑modaler Interaktionsschritt erlaubt es dann jedem Wort, relevante Bildbereiche „anzusehen“ und so textliche Repräsentationen zu erzeugen, die sich dessen bewusst sind, was im Gemälde vorkommt – nützlich etwa zur Unterscheidung, ob „weißer Stein“ einen Felsen oder eine Person meint.
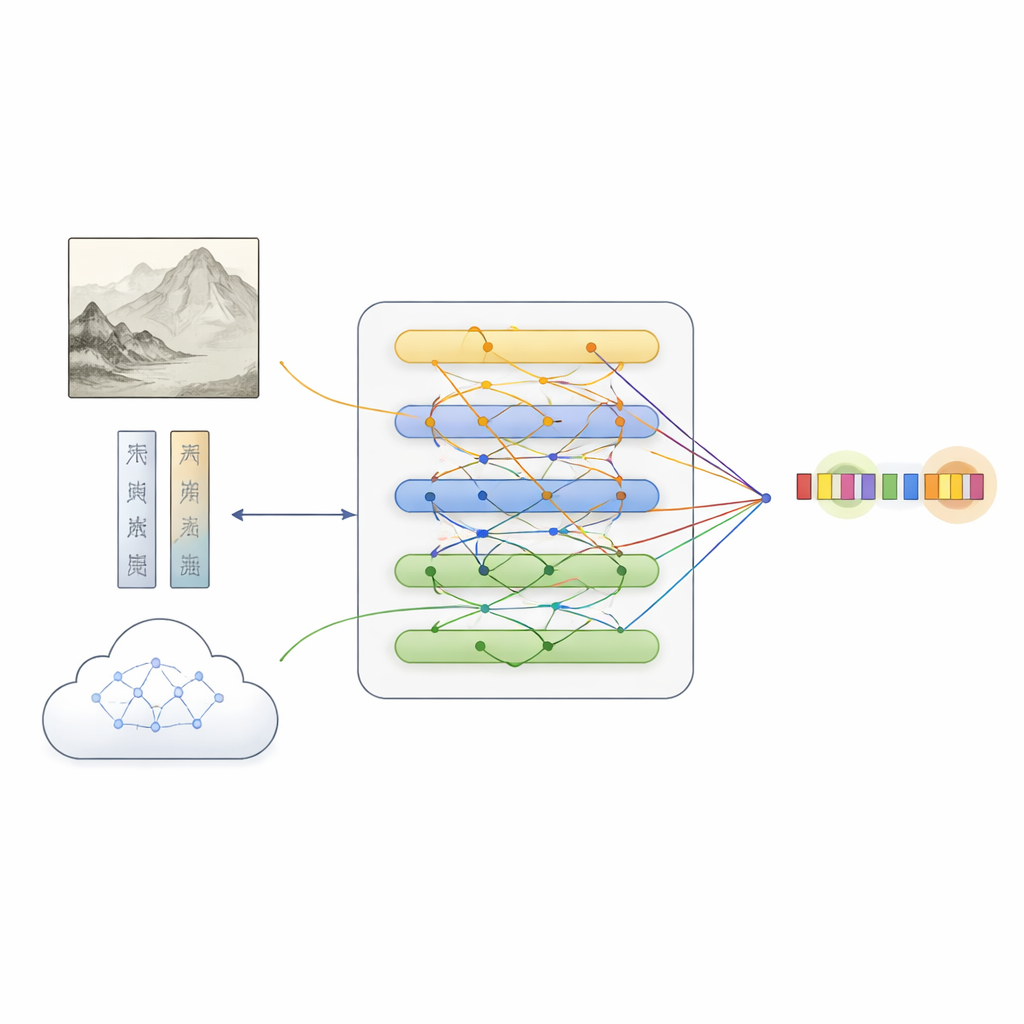
Kulturelles Wissen hinzufügen, um Lücken zu schließen
MFKA geht weiter, indem ein multimodales großes Sprachmodell – eines, das Bilder sehen und Texte lesen kann – kulturelles Wissen beisteuert. In einer ersten Phase fasst dieses Hilfsmodell die wichtigsten visuellen Elemente des Gemäldes zusammen, etwa Tiere, Pflanzen, Gebäude oder Figuren. In einer zweiten Phase nutzt es diese Zusammenfassung zusammen mit der Beschreibung, um wahrscheinliche Entitäten und ihre Typen aufzulisten (beispielsweise dass eine bestimmte Wendung ein Werktitel, eine Technik oder ein Siegel ist). Dieses zusätzliche Wissen wird wieder in Textform überführt, kodiert und mittels Aufmerksamkeitsmechanismen mit der ursprünglichen Beschreibung verschmolzen. Ein spezialisertes Fusionsmodul balanciert dann die drei Pfade – reiner Text, textbewusste Bildmerkmale und textbewusstes Wissen – und hebt Tokens hervor, die am ehesten Entitäten entsprechen, während es komplementäre Hinweise aus jeder Quelle bewahrt.
Was die Experimente zeigen
Auf CP‑MNER getestet, übertraf MFKA eine breite Palette führender rein textbasierter und multimodaler Systeme und erzielte die höchste Gesamten‑F1‑Punktzahl (ein gängiges Genauigkeitsmaß). Besonders gut schnitt es in Kategorien ab, in denen visueller Kontext oder kulturelle Hinweise entscheidend sind, etwa beim Unterscheiden von Tieren und Objekten oder bei der Abgrenzung von Organisationen wie dem Palastmuseum gegenüber physischen Orten oder Gebäuden. Sorgfältige Ablationsstudien zeigten, dass jeder Teil des Rahmens – Bild‑Text‑Interaktion, Wissensaugmentierung und das ausgefeilte Fusionsschema – zu den Verbesserungen beitrug und dass das schrittweise Entfernen dieser Komponenten die Leistung zurück in Richtung gewöhnlicher textbasierter Modelle drückte. Wichtig ist auch, dass MFKA auf einem thematisch unabhängigen Social‑Media‑Datensatz konkurrenzfähig arbeitete, was für die Flexibilität des Designs jenseits der Kunstwelt spricht.
Was das für das kulturelle Erbe bedeutet
Für Nicht‑Spezialisten lautet die Schlussfolgerung: Die Autorinnen und Autoren haben ein Computersystem entwickelt, das chinesische Gemälde deutlich mehr wie ein fachkundiger Kurator „liest“, indem es gemeinsam berücksichtigt, was geschrieben steht, was gemalt ist und was die Kunstgeschichte weiß. Ihr Datensatz CP‑MNER bietet eine öffentliche Benchmark‑Ressource für künftige Arbeiten, und MFKA zeigt, dass die Kombination visueller Hinweise mit maschinell erzeugtem kulturhistorischem Wissen feinere Details erschließen kann, die in Museumsunterlagen zuvor verborgen waren. Langfristig könnten solche Werkzeuge intelligentere Suche, reichere Online‑Ausstellungen und umfangreiche Wissensgraphen ermöglichen, die Künstler, Stile, Materialien und Motive über Sammlungen hinweg verknüpfen und so Forschenden wie der Öffentlichkeit neue Zugänge zur chinesischen Malerei eröffnen.
Zitation: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Schlüsselwörter: chinesische Malerei, multimodales KI, benannte Entitätserkennung, kulturelles Erbe, Wissensgraphen