Clear Sky Science · fr
Un cadre de fusion multi‑chemins avec augmentation de connaissances pour la RNE multimodale des peintures chinoises
Apprendre aux ordinateurs à « lire » les peintures chinoises
Les réserves des musées contiennent aujourd’hui d’immenses collections numériques de peintures chinoises — des images haute résolution accompagnées de descriptions riches — mais la plupart de ces informations restent enfermées dans des textes non structurés et des images non annotées. Cette étude montre comment la combinaison de l’analyse d’images, des technologies linguistiques et des connaissances culturelles peut aider les ordinateurs à identifier automatiquement les personnes, lieux, périodes et caractéristiques artistiques clés dans les peintures chinoises, facilitant ainsi la recherche, l’étude et la préservation de ce patrimoine.
Pourquoi les peintures chinoises sont difficiles pour les machines
La peinture chinoise est plus que de l’encre sur la soie ; elle tisse paysage, personnages, poésie, calligraphie et sceaux, tous baignés d’histoire. Les notices muséales reflètent cette richesse : de longues descriptions mentionnent dynasties, ateliers, gestes de pinceau et collectionneurs, tandis que les images montrent montagnes, pavillons, végétation et sceaux rouges. Pourtant le langage y est souvent indirect et poétique. Un seul terme comme « pierre blanche » peut désigner soit un rocher dans la scène, soit le nom d’un peintre célèbre, selon le contexte. Les outils existants de reconnaissance d’entités nommées — des logiciels qui étiquettent les noms de personnes, lieux et autres entités dans le texte — ont été entraînés sur des actualités ou des réseaux sociaux généraux, pas sur ce domaine artistique spécialisé, si bien qu’ils passent à côté de nombreux détails culturellement spécifiques et peinent à relier le texte à ce qui apparaît sur l’image.
Construire un jeu de données adapté au patrimoine artistique
Pour y remédier, les auteurs ont d’abord créé CP‑MNER, un nouveau jeu de référence centré sur la peinture chinoise. Ils ont collecté 1 188 paires image–texte de haute qualité, principalement à partir de la collection en ligne du Palais impérial et complétées par des entrées d’encyclopédies. Après un nettoyage automatique et des vérifications manuelles, la description de chaque peinture a été standardisée et soigneusement alignée sur son image. Des experts ont ensuite conçu un ensemble détaillé de 16 types d’entités reflétant des préoccupations art‑historiques : non seulement PERSONNE, TEMPS et LIEU, mais aussi titres d’ŒUVRE, inscriptions de SCEAU, TECHNIQUE, MATÉRIAU, STYLE, PLANTE, FIGURE représentée, et plus encore. À l’aide d’un processus en deux temps — pré‑annotation automatique par un grand modèle de langage suivie de corrections expertes — ils ont annoté plus de 32 000 entités. Chaque description compte en moyenne environ 280 caractères chinois et 27 entités, faisant de CP‑MNER un banc d’essai dense et exigeant.
Comment le nouveau système comprend les peintures
Sur la base de ce jeu de données, l’équipe a proposé MFKA, un cadre qui apprend aux ordinateurs à comprendre les peintures en fusionnant trois flux d’information : le texte, l’image et les connaissances externes. D’abord, un modèle de langage traite la description, tandis qu’un réseau visuel profond divise la peinture en régions et extrait des caractéristiques visuelles. Une étape d’interaction intermodale permet alors à chaque mot de « regarder » les parties pertinentes de l’image, créant des représentations textuelles conscientes de ce qui apparaît dans la peinture — utile, par exemple, pour décider si « pierre blanche » renvoie à un rocher ou à une personne.
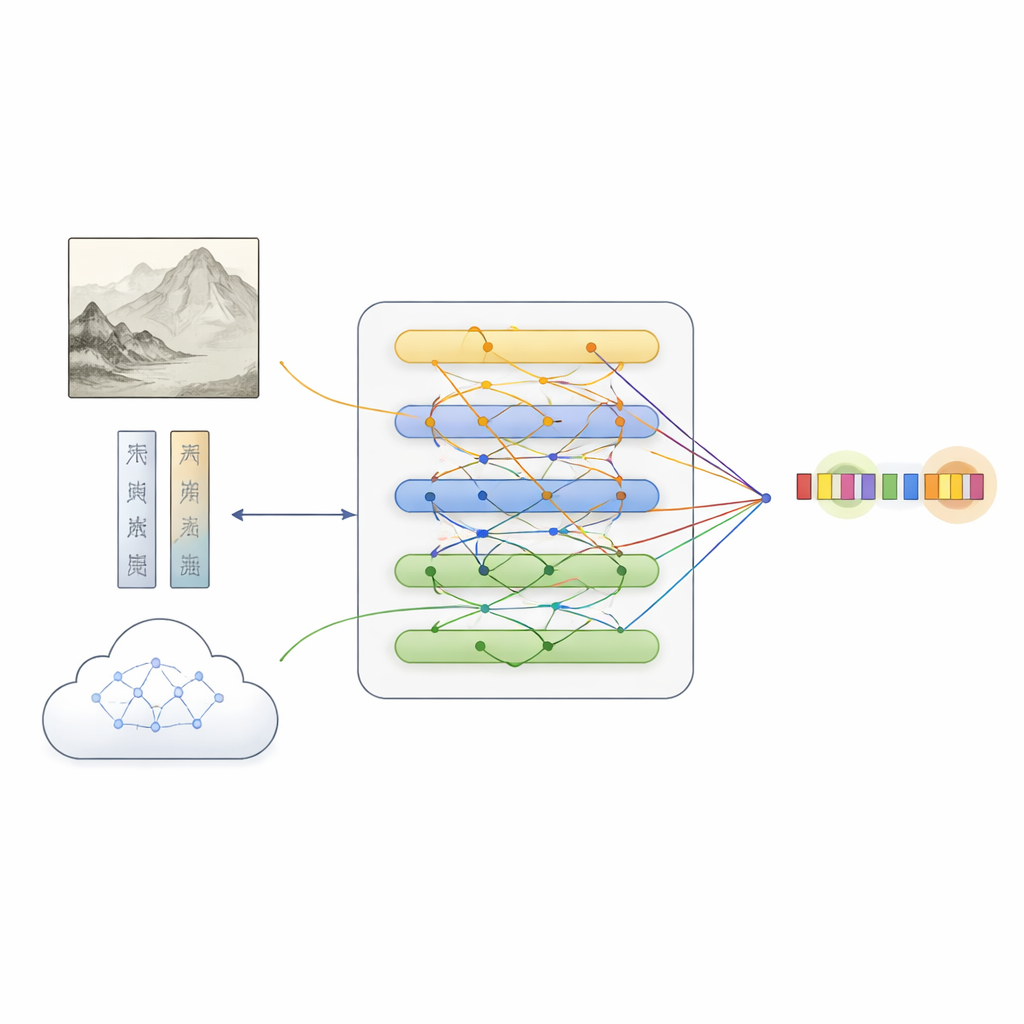
Ajouter des connaissances culturelles pour combler les lacunes
MFKA va plus loin en sollicitant un grand modèle de langage multimodal — capable de voir des images et de lire du texte — pour fournir des connaissances culturelles. Dans une première phase, ce modèle aide résume les éléments visuels clés de la peinture, tels que animaux, plantes, bâtiments ou personnages. Dans une seconde phase, il utilise ce résumé ainsi que la description pour dresser la liste des entités probables et de leurs types (par exemple, qu’une certaine expression est le titre d’une peinture, une technique ou un sceau). Ces connaissances auxiliaires sont reconverties en texte, encodées et fusionnées avec la description originale via des mécanismes d’attention. Un module de fusion spécialisé équilibre ensuite les trois voies — texte brut, caractéristiques visuelles informées par le texte et connaissances informées par le texte — en mettant en évidence les tokens les plus susceptibles de correspondre à des entités tout en préservant les indices complémentaires de chaque source.
Ce que montrent les expériences
Testé sur CP‑MNER, MFKA a surpassé un large éventail de systèmes de pointe, mono‑textuels et multimodaux, obtenant le meilleur score F1 global (une mesure standard de l’exactitude). Il a particulièrement bien performé sur les catégories où le contexte visuel ou les indices culturels sont déterminants, comme distinguer animaux et objets, ou différencier des organisations comme le Palais impérial de lieux ou de bâtiments physiques. Des études d’ablation soignées ont montré que chaque composante du cadre — interaction image–texte, augmentation par les connaissances et schéma de fusion sophistiqué — contribuait aux gains, et que leur suppression faisait progressivement retomber les performances vers des modèles basés uniquement sur le texte. Fait important, MFKA s’est aussi montré compétitif sur un jeu de données de réseaux sociaux sans lien avec l’art, suggérant que son architecture est flexible au‑delà du domaine artistique.
Ce que cela signifie pour le patrimoine culturel
Pour les non‑spécialistes, la conclusion est que les auteurs ont appris à un système informatique à « lire » les peintures chinoises de manière beaucoup plus proche de celle d’un conservateur expert, en considérant conjointement ce qui est écrit, ce qui est peint et ce que l’histoire de l’art permet de savoir. Leur jeu de données CP‑MNER fournit une référence publique pour les travaux futurs, et MFKA montre que la combinaison d’indices visuels et de connaissances culturelles générées par machine peut révéler des détails fins auparavant enfouis dans les notices muséales. À terme, de tels outils pourraient alimenter des recherches plus intelligentes, des expositions en ligne plus riches et de vastes graphes de connaissances reliant artistes, styles, matériaux et motifs à travers les collections, aidant chercheurs et grand public à explorer la peinture chinoise sous de nouveaux angles.
Citation: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Mots-clés: peinture chinoise, IA multimodale, reconnaissance d'entités nommées, patrimoine culturel, graphes de connaissances