Clear Sky Science · ja
中国画のマルチモーダルNERのための知識強化を伴うマルチ経路融合フレームワーク
コンピュータに中国画の読み方を教える
博物館の収蔵庫には現在、高解像度画像と詳細な説明文が組み合わされた大量の中国画のデジタルコレクションが保存されていますが、その多くは非構造化テキストやラベル付けされていない画像のまま眠っています。本研究は、画像解析、言語技術、文化的知識を組み合わせることで、コンピュータが中国画の主要な人物、地名、時代、芸術的特徴を自動的に特定できるようにし、検索、研究、保存を容易にする方法を示します。
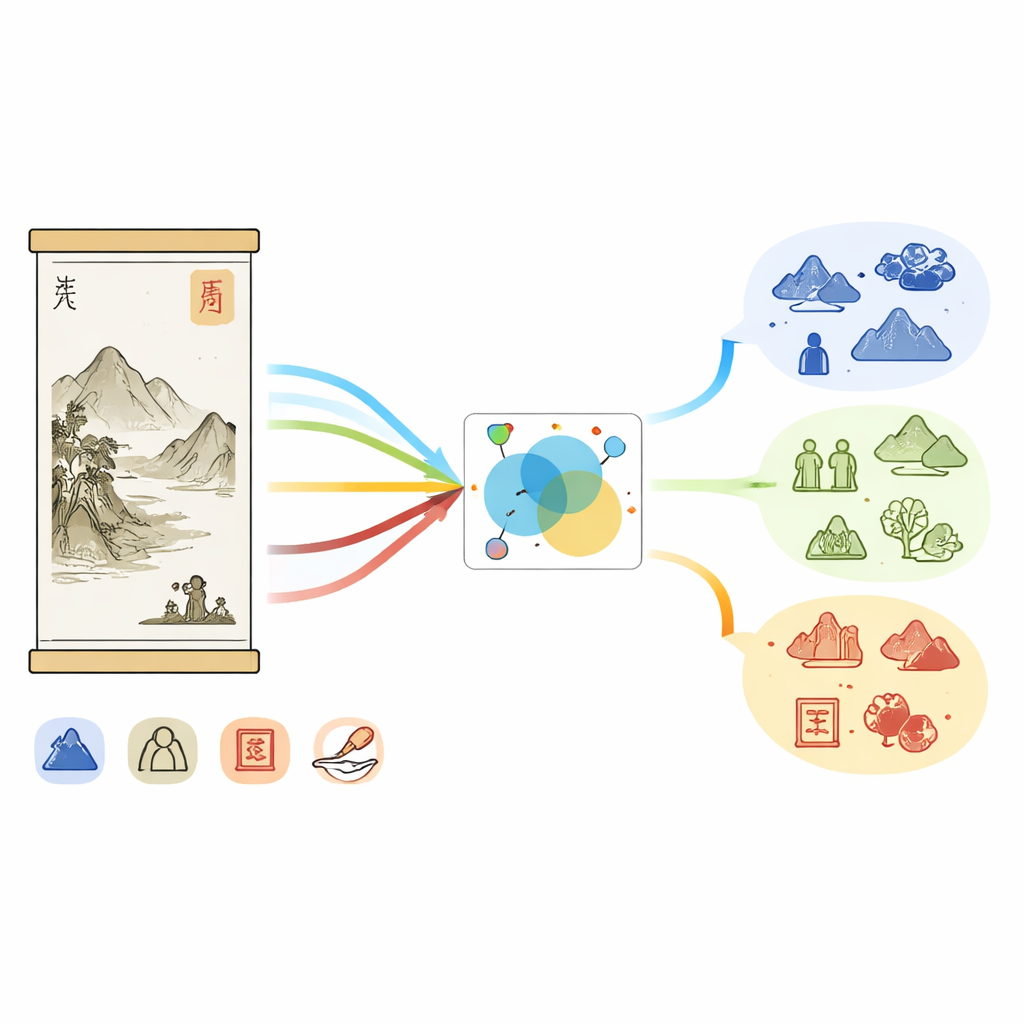
なぜ中国画は機械にとって難しいのか
中国画は単なる絹や紙への墨表現にとどまらず、風景、人物、詩、書、印章が歴史的文脈と織り合わさっています。博物館の記録もその豊かさを反映しており、長い解説には王朝、画室、筆致、収蔵者などが記され、画像には山、水亭、植物、朱印などが写ります。しかし表現はしばしば婉曲で詩的です。「白石」のような語は文脈によって場面の岩を指すことも、著名な画家の号を指すこともあります。既存の固有表現抽出ツールはニュースやソーシャルメディア向けに訓練されており、このような専門的な美術領域には対応していないため、文化固有の詳細を見落とし、テキストと画像の対応づけに苦労します。
文化遺産向けに設計したデータセットの構築
これに対処するため、著者らはまず中国画に特化した新しいベンチマークデータセットCP‑MNERを作成しました。主に故宮博物院のオンラインコレクションと百科事典的な記述を補って、1,188件の高品質な画像–テキスト対を収集しました。自動クリーニングと手動チェックを経て、各作品の解説は標準化され画像と慎重に整合されました。専門家はさらに、人物(PERSON)、年代(TIME)、場所(LOCATION)だけでなく、作品名(ARTWORK)、印章の刻字(SEAL)、技法(TECHNIQUE)、素材(MATERIAL)、様式(STYLE)、植物(PLANT)、画中の人物(FIGURE)など、美術史的関心を反映した16種類の詳細なエンティティタイプを設計しました。自動事前注釈(大規模言語モデルによる)と専門家の修正という二段階のプロセスを用いて、3万2千件以上のエンティティにラベルを付けました。各解説は平均で約280字、27個のエンティティを含み、CP‑MNERは密で挑戦的なテストベッドとなっています。
新システムが絵画を理解する仕組み
このデータセットの上に、研究チームはMFKAというフレームワークを提案しました。これはテキスト、画像、外部知識という三つの情報経路を融合してコンピュータに絵画を理解させるものです。まず言語モデルが解説文を処理し、深層ビジョンネットワークが絵画を領域に分割して視覚特徴を抽出します。クロスモーダルな相互作用の段階では、各単語が画像の関連部分を「参照」できるようになり、絵画に現れる内容を意識したテキスト表現が得られます。これは例えば「白石」が岩を指すのか人物名を指すのかを判断する際に有用です。
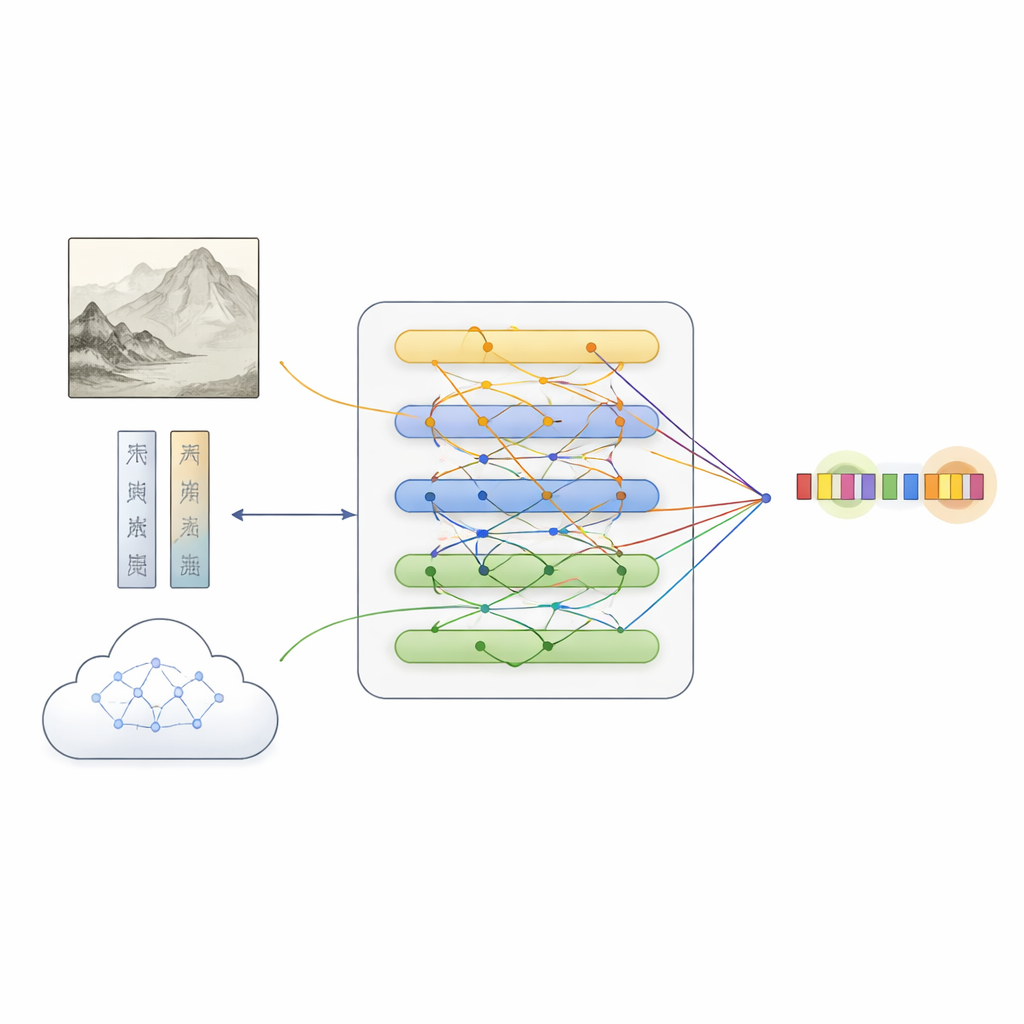
欠けた手がかりを埋める文化的知識の付加
MFKAはさらに、画像を見てテキストを読むことのできるマルチモーダル大規模言語モデルに文化的知識を補ってもらいます。第一段階では、この補助モデルが動物、植物、建物、人物など絵画の主要な視覚要素を要約します。第二段階では、その要約と解説文を用いて、ある語句が作品名、技法、印章などどのタイプのエンティティである可能性が高いかを列挙します。この補助的知識はテキストに戻されエンコードされ、アテンション機構を通じて元の解説に統合されます。専用の融合モジュールは三つの経路(生テキスト、テキストを意識した画像特徴、テキストを意識した知識)を調整し、各ソースの補完的手がかりを保ちながらエンティティに対応するトークンを強調します。
実験が示すこと
CP‑MNERで評価した結果、MFKAは幅広い最先端のテキスト専用およびマルチモーダルシステムを上回り、全体のF1スコア(標準的な精度指標)で最高を記録しました。特に視覚的文脈や文化的ヒントが重要なカテゴリ、たとえば動物と物体の区別や、故宮博物院のような組織と物理的な場所や建築物の識別で優れた成績を示しました。詳細なアブレーション研究により、画像–テキスト相互作用、知識付加、洗練された融合方式の各要素が寄与していることが示され、これらを順に取り除くと性能が従来のテキストベースモデルに近づくことがわかりました。重要な点として、MFKAは無関係なソーシャルメディアのデータセットでも競争力のある結果を出しており、その設計は美術の領域を超えて柔軟であることを示唆しています。
文化遺産にとっての意義
非専門家にとって重要な結論は、著者らが解説文と図像、そして美術史の知識を同時に考慮することで、専門のキュレーターのように中国画を「読む」コンピュータシステムを構築したことです。CP‑MNERデータセットは今後の研究のための公開ベンチマークを提供し、MFKAは視覚的手がかりと機械生成の文化知識を組み合わせることで、これまで博物館記録の中に埋もれていた細かな情報を引き出せることを示しました。長期的には、このようなツールがより賢い検索、充実したオンライン展示、そして収蔵品を横断して作家、様式、素材、モチーフを結びつける大規模な知識グラフの構築を促し、研究者と一般の双方が中国画を新たな方法で探索する助けになる可能性があります。
引用: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
キーワード: 中国画, マルチモーダルAI, 固有表現抽出, 文化遺産, 知識グラフ