Clear Sky Science · pt
Uma fusão multi-caminho com estrutura de aumento de conhecimento para NER multimodal em pintura chinesa
Ensinando computadores a “ler” pinturas chinesas
Os depósitos de museus agora guardam vastas coleções digitais de pinturas chinesas — imagens de alta resolução acompanhadas por descrições ricas — mas a maior parte dessa informação está presa em texto não estruturado e imagens sem anotação. Este estudo mostra como a combinação de análise de imagens, tecnologia de linguagem e conhecimento cultural pode ajudar computadores a identificar automaticamente pessoas, lugares, períodos e características artísticas importantes em pinturas chinesas, facilitando a busca, o estudo e a preservação desse patrimônio.
Por que pinturas chinesas são difíceis para máquinas
A pintura chinesa é mais do que tinta sobre seda; entrelaça paisagem, figuras, poesia, caligrafia e selos, tudo imbuído de história. Os registros de museu refletem essa riqueza: descrições longas mencionam dinastias, ateliês, pinceladas e colecionadores, enquanto as imagens exibem montanhas, pavilhões, plantas e selos vermelhos. Ainda assim, a redação costuma ser indireta e poética. Um termo isolado como “pedra branca” pode referir-se tanto a uma rocha na cena quanto ao nome de um pintor famoso, dependendo do contexto. Ferramentas existentes de reconhecimento de entidades nomeadas — softwares que rotulam nomes de pessoas, lugares e outras entidades no texto — foram treinadas em notícias ou redes sociais gerais, não neste domínio artístico especializado, por isso deixam escapar muitos detalhes culturais e têm dificuldade em conectar o texto ao que aparece na imagem.
Construindo um conjunto de dados voltado ao patrimônio artístico
Para enfrentar isso, os autores criaram primeiro o CP‑MNER, um novo conjunto de referência focado em pintura chinesa. Eles coletaram 1.188 pares imagem–texto de alta qualidade, principalmente da coleção online do Palácio Museu e complementados por entradas de enciclopédias. Após limpeza automática e checagens manuais, a descrição de cada pintura foi padronizada e cuidadosamente alinhada com sua imagem. Especialistas então definiram um conjunto detalhado de 16 tipos de entidade que refletem preocupações historiográficas da arte: não apenas PESSOA, TEMPO e LOCAL, mas também títulos de OBRA, inscrições de SELO, TÉCNICA, MATERIAL, ESTILO, PLANTA, FIGURA na imagem e outros. Usando um processo em duas etapas — pré-anotação automática com um grande modelo de linguagem seguida de correção por especialistas — eles rotularam mais de 32.000 entidades. Cada descrição tem em média cerca de 280 caracteres chineses e 27 entidades, tornando o CP‑MNER um campo de testes denso e desafiador.
Como o novo sistema entende pinturas
Sobre esse conjunto de dados, a equipe propôs o MFKA, uma estrutura que ensina computadores a entender pinturas ao fundir três fluxos de informação: texto, imagem e conhecimento externo. Primeiro, um modelo de linguagem processa a descrição, enquanto uma rede profunda de visão divide a pintura em regiões e extrai características visuais. Uma etapa de interação cross-modal permite então que cada palavra “olhe” para partes relevantes da imagem, criando representações textuais conscientes do que aparece na pintura — útil, por exemplo, ao decidir se “pedra branca” se refere a uma rocha ou a uma pessoa.
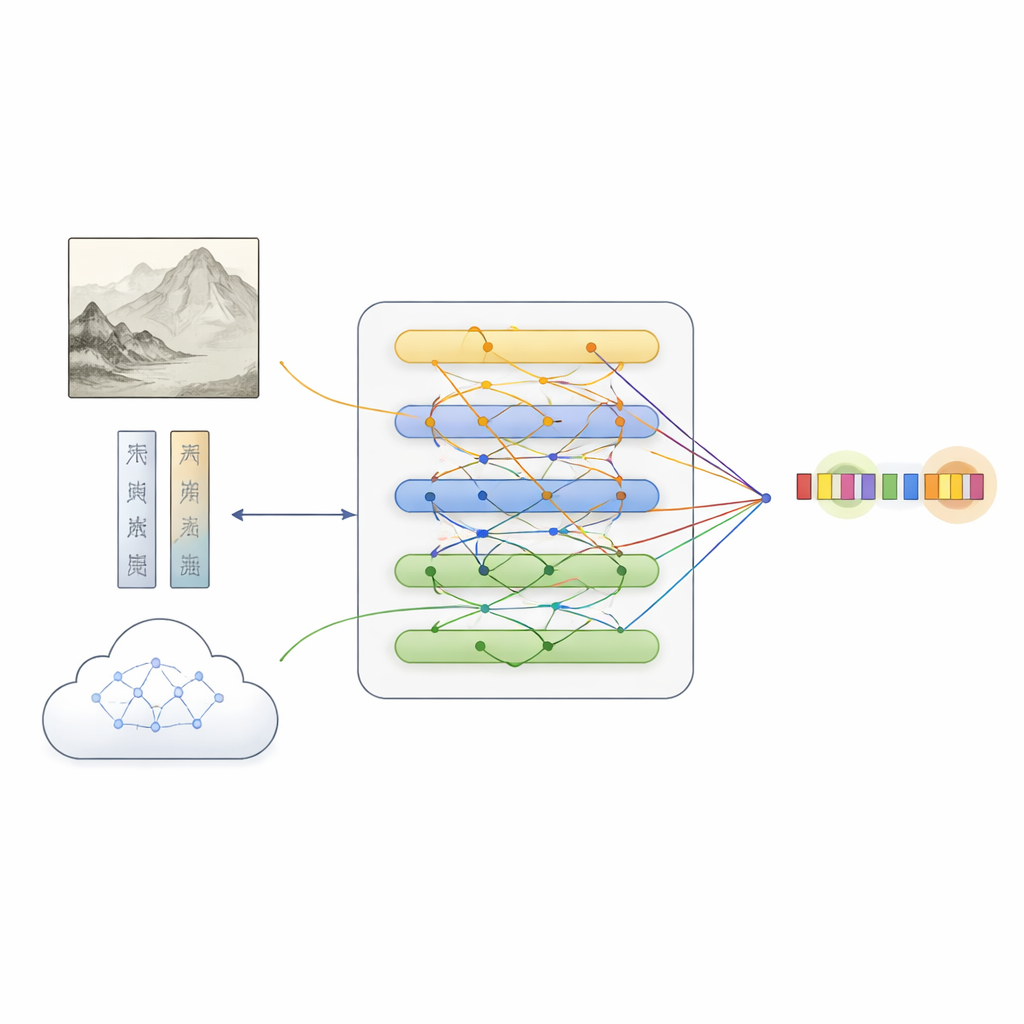
Acrescentando conhecimento cultural para preencher lacunas
O MFKA vai além ao pedir a um grande modelo de linguagem multimodal — capaz de ver imagens e ler texto — que forneça conhecimento cultural. Numa primeira fase, esse modelo auxiliar resume os principais elementos visuais da pintura, como animais, plantas, edifícios ou figuras. Numa segunda fase, ele usa esse resumo mais a descrição para listar entidades prováveis e seus tipos (por exemplo, que certa expressão é um título de pintura, uma técnica ou um selo). Esse conhecimento auxiliar é transformado em texto, codificado e mesclado com a descrição original por meio de mecanismos de atenção. Um módulo de fusão especializado então equilibra os três caminhos — texto puro, características de imagem conscientes do texto e conhecimento consciente do texto — destacando tokens que provavelmente correspondem a entidades enquanto preserva pistas complementares de cada fonte.
O que os experimentos mostram
Quando testado no CP‑MNER, o MFKA superou uma ampla gama de sistemas líderes apenas em texto e multimodais, alcançando a maior pontuação F1 geral (uma medida padrão de acurácia). Foi especialmente eficaz em categorias onde o contexto visual ou pistas culturais importam, como distinguir animais de objetos, ou organizações como o Palácio Museu de lugares ou edifícios físicos. Estudos de ablação cuidadosos mostraram que cada parte da estrutura — interação imagem–texto, aumento por conhecimento e o esquema de fusão sofisticado — contribuiu para os ganhos, e que removê‑las gradualmente fez o desempenho regredir para modelos ordinários baseados apenas em texto. Importante, o MFKA também teve desempenho competitivo em um conjunto de dados não relacionado de redes sociais, sugerindo que seu desenho é flexível além do mundo da arte.
O que isso significa para o patrimônio cultural
Para não especialistas, a conclusão é que os autores ensinaram um sistema computacional a “ler” pinturas chinesas de forma muito mais parecida com um curador especialista, ao considerar em conjunto o que está escrito, o que está pintado e o que se sabe pela história da arte. Seu conjunto de dados CP‑MNER fornece um benchmark público para trabalhos futuros, e o MFKA demonstra que combinar pistas visuais com conhecimento cultural gerado por máquina pode desenterrar detalhes finos que antes estavam enterrados nos registros de museus. A longo prazo, tais ferramentas poderiam alimentar buscas mais inteligentes, exposições online mais ricas e grandes grafos de conhecimento que conectem artistas, estilos, materiais e motivos através de coleções, ajudando tanto pesquisadores quanto o público a explorar a pintura chinesa de novas maneiras.
Citação: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Palavras-chave: Pintura chinesa, IA multimodal, reconhecimento de entidades nomeadas, patrimônio cultural, grafos de conhecimento