Clear Sky Science · nl
Een multipad-fusie met kennisverrijkt kader voor multimodale NER in Chinese schilderkunst
Computers leren lezen van Chinese schilderijen
Collecties in museumdepots bevatten nu enorme digitale verzamelingen Chinese schilderijen — hoge resolutie afbeeldingen gekoppeld aan rijke beschrijvingen — maar het merendeel van deze informatie zit vast in ongestructureerde tekst en ongetagde beelden. Deze studie laat zien hoe het combineren van beeldanalyse, taaltechnologie en culturele kennis computers kan helpen automatisch belangrijke personen, plaatsen, periodes en artistieke kenmerken in Chinese schilderijen te identificeren, waardoor zoeken, bestuderen en behoud van dit erfgoed eenvoudiger wordt.
Waarom Chinese schilderijen moeilijk zijn voor machines
Chinese schilderkunst is meer dan inkt op zijde; ze verweeft landschap, figuren, poëzie, kalligrafie en zegels, allemaal doordrenkt met geschiedenis. Museumgegevens weerspiegelen deze rijkdom: lange beschrijvingen noemen dynastieën, ateliers, penseelstreken en verzamelaars, terwijl de afbeeldingen bergen, paviljoens, planten en rode zegels tonen. Toch is de bewoording vaak indirect en poëtisch. Een enkel begrip als “witte steen” kan afhankelijk van de context verwijzen naar een rots in de scène of naar de naam van een beroemde schilder. Bestaande hulpmiddelen voor named entity recognition — software die namen van personen, plaatsen en andere entiteiten in tekst labelt — zijn getraind op algemene nieuws- of sociale-media-teksten, niet op dit gespecialiseerde kunstdomein, waardoor ze veel cultureel specifieke details missen en moeite hebben om tekst aan beeldinhoud te koppelen.
Een dataset op maat van erfgoedkunst opbouwen
Om dit aan te pakken, maakten de auteurs eerst CP‑MNER, een nieuwe benchmarkdataset gericht op Chinese schilderkunst. Ze verzamelden 1.188 hoogwaardige beeld‑tekst paren, voornamelijk uit de online collectie van het Paleismuseum en aangevuld met encyclopedieartikelen. Na automatische schoonmaak en handmatige controles werden de beschrijvingen gestandaardiseerd en zorgvuldig op het beeld afgestemd. Experts ontwierpen vervolgens een gedetailleerde set van 16 entiteitstypen die kunsthistorische aandachtspunten weerspiegelen: niet alleen PERSON, TIME en LOCATION, maar ook TITELS VAN WERKEN, ZEGELinscripties, TECHNIEK, MATERIAAL, STIJL, PLANT, FIGUUR in het beeld, en meer. Met een twee‑staps proces — automatische voorannotatie met een grote taalmodel gevolgd door correctie door experts — labelden ze meer dan 32.000 entiteiten. Elke beschrijving bevat gemiddeld ongeveer 280 Chinese tekens en 27 entiteiten, waardoor CP‑MNER een compacte en uitdagende testomgeving is.
Hoe het nieuwe systeem schilderijen begrijpt
Bovenop deze dataset stelde het team MFKA voor, een kader dat computers leert schilderijen te begrijpen door drie informatieroutes te fuseren: tekst, beeld en externe kennis. Eerst verwerkt een taalmodel de beschrijving, terwijl een diep visueel netwerk het schilderij in regio’s verdeelt en visuele kenmerken extraheert. Een kruis‑modale interactiestap laat elk woord vervolgens “kijken naar” relevante delen van de afbeelding, waardoor tekstrepresentaties ontstaan die zich bewust zijn van wat er in het schilderij verschijnt — nuttig bijvoorbeeld om te bepalen of “witte steen” naar een rots of naar een persoon verwijst.
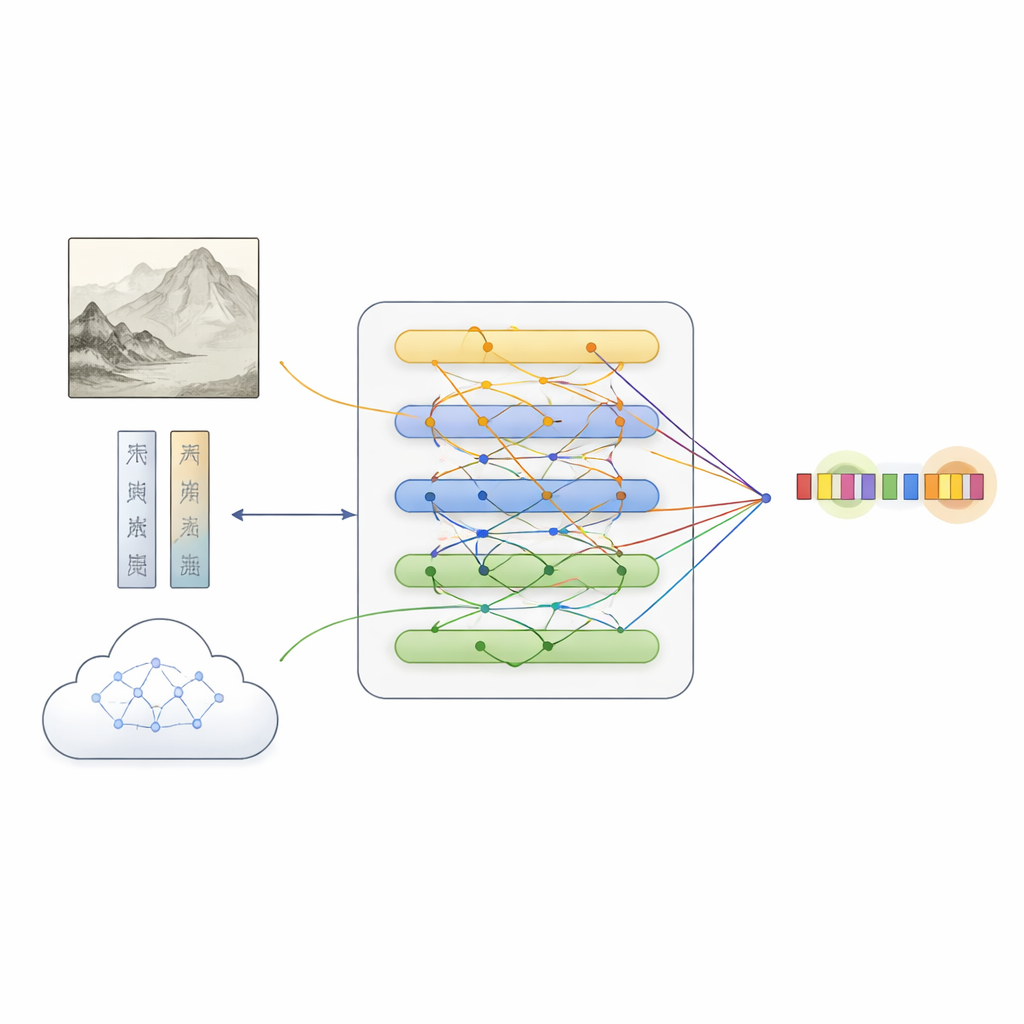
Cultuurhistorische kennis toevoegen om gaten te vullen
MFKA gaat verder door een multimodaal groot taalmodel — een model dat beelden kan zien en tekst kan lezen — te vragen culturele kennis aan te leveren. In een eerste fase vat dit hulpmodel de belangrijkste visuele elementen van het schilderij samen, zoals dieren, planten, gebouwen of figuren. In een tweede fase gebruikt het die samenvatting plus de beschrijving om waarschijnlijke entiteiten en hun typen op te sommen (bijvoorbeeld dat een bepaalde frase een schilderijtitel, een techniek of een zegel is). Deze aanvullende kennis wordt weer in tekst omgezet, gecodeerd en via attentiemechanismen met de oorspronkelijke beschrijving samengevoegd. Een gespecialiseerd fusatiemodule balanceert vervolgens de drie paden — gewone tekst, tekst‑bewuste beeldkenmerken en tekst‑bewuste kennis — waarbij tokens worden benadrukt die waarschijnlijk overeenkomen met entiteiten, terwijl complementaire aanwijzingen uit elke bron behouden blijven.
Wat de experimenten aantonen
Getest op CP‑MNER presteerde MFKA beter dan een breed scala aan toonaangevende tekst‑alleen en multimodale systemen en behaalde de hoogste totale F1‑score (een standaardmaat voor nauwkeurigheid). Het deed het bijzonder goed op categorieën waar visuele context of culturele hint belangrijk is, zoals het onderscheiden van dieren van objecten, of organisaties zoals het Paleismuseum van fysieke plaatsen of gebouwen. Zorgvuldige ablatie‑studies toonden aan dat elk onderdeel van het kader — beeld‑tekstinteractie, kennisverrijking en het verfijnde fusieregime — bijdroeg aan de verbeteringen, en dat het verwijderen ervan de prestaties geleidelijk terugduwde richting gewone tekstgebaseerde modellen. Belangrijk is dat MFKA ook competitief presteerde op een niet‑verwante sociale‑media dataset, wat suggereert dat het ontwerp verder reikt dan de kunstwereld.
Wat dit betekent voor cultureel erfgoed
Voor niet‑specialisten is de conclusie dat de auteurs een computersysteem hebben geleerd Chinese schilderijen veel meer te “lezen” zoals een deskundige conservator dat zou doen, door gezamenlijk te kijken naar wat geschreven is, wat geschilderd is en wat bekend is uit de kunstgeschiedenis. Hun CP‑MNER‑dataset biedt een openbare benchmark voor toekomstig werk, en MFKA toont aan dat het combineren van visuele aanwijzingen met machinaal gegenereerde culturele kennis fijne details kan ontsluiten die voorheen in museumgegevens verborgen waren. Op de lange termijn zouden dergelijke hulpmiddelen slimmer zoeken, rijkere online tentoonstellingen en uitgebreide kennisgrafen kunnen mogelijk maken die kunstenaars, stijlen, materialen en motieven over collecties heen verbinden, waardoor zowel onderzoekers als het publiek Chinese schilderkunst op nieuwe manieren kunnen verkennen.
Bronvermelding: Wan, J., Chen, S., Zeng, Q. et al. A multi-path fusion with knowledge augmentation framework for multimodal NER in Chinese painting. npj Herit. Sci. 14, 265 (2026). https://doi.org/10.1038/s40494-026-02528-1
Trefwoorden: Chinese schilderkunst, multimodale AI, named entity recognition, cultureel erfgoed, kennisgrafen