Clear Sky Science · tr
Sinir ağlarının genelleştirilebilirliğinde yüksek entropinin avantajı
Günlük yapay zeka için neden önemli
Modern yapay zeka sistemleri yüzleri tanıyabilir, dilleri çevirebilir ve ev fiyatlarını şaşırtıcı derecede isabetli tahmin edebilir — yine de yeni, görülmemiş veriler üzerinde neden bu kadar iyi çalıştıklarını tam olarak anlamıyoruz. Bu makale, fiziğin kavramlarından yararlanarak bu gizemi ele alıyor. Yazarlar, en güvenilir sinir ağlarının yalnızca eğitim verisine uyanlar olmadığını, aynı zamanda içsel parametre uzayında "ferah" bölgelerde bulunanlar olduğunu; buna yüksek entropi avantajı adını verdiklerini gösteriyorlar.
Sinir ağlarının içine bakmanın yeni bir yolu
Bir sinir ağını kara kutu olarak ele almak yerine araştırmacılar, iç ağırlıklarının her olası ayarını uçsuz bucaksız bir peyzajda bir nokta olarak tasavvur ediyor. Eğitim verisine eşit derecede uyan birçok farklı nokta olabilir, ancak bu çözümlerden bazıları yeni verilere genelleşir bazıları genelleşmez. İstatistiksel fizikten yararlanarak, her bir ağırlık konfigürasyonunu bir mikrodurum ve onun genel performansını — eğitim kaybı ve test doğruluğu — makroskobik özellikler olarak ele alıyorlar. İnceledikleri ana nicelik entropi; burada entropi, belirli bir eğitim ve test performans düzeyine karşılık gelen parametre uzayının ne kadar geniş olduğunu ölçüyor.
Moleküler simülasyonlardan araç ödünç almak
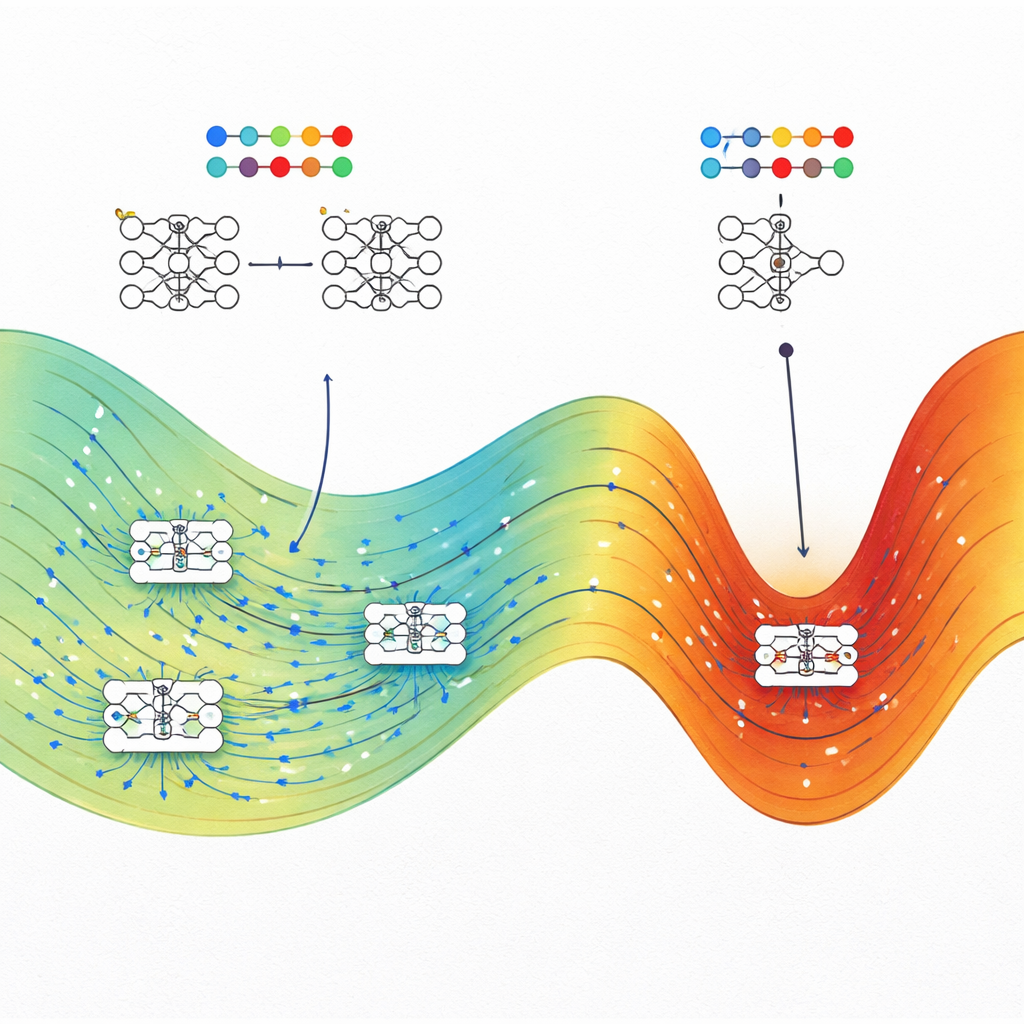
Belirli bir performansı hangi ağ konfigürasyonlarının sağladığını doğrudan saymak imkansızdır; çünkü sürekli ağırlık ayarları sonsuzdur. Bunu aşmak için yazarlar, başlangıçta molekülleri incelemek için geliştirilmiş olan Wang–Landau Monte Carlo ve Wang–Landau Moleküler Dinamik algoritmalarını uyarlıyorlar. Benzeşimlerinde her ağ ağırlığı bir atomik koordinat gibi davranıyor ve kayıp fonksiyonu potansiyel enerji rolünü üstleniyor. Bu örnekleme yöntemleri, her eğitim kaybı ve test doğruluğu (veya test kaybı) kombinasyonu için parametre uzayının ne kadarının işgal edildiğini gösteren bir "entropi peyzajı" haritalamalarına olanak tanıyor.
Çoklu görevlerde yüksek entropili durumlar üstün
Ekip bu çerçeveyi dört çok farklı probleme uyguluyor: oyuncak bir spiral sınıflandırma görevi, tabüler verilerden konut fiyatı tahmini, indirgenmiş MNIST veri setinden el yazısı rakam tanıma ve kimyasal dizilerden polimer bant aralığı enerjisi tahmini. Her durumda, standart optimizatörlerle (örneğin stokastik gradyan inişi ya da bir regresyon görevinde Adam) eğitilmiş tipik ağları, aynı eğitim kaybında bulunan en yüksek entropili durumlarla karşılaştırıyorlar. Tutarlı biçimde, yüksek entropili durumlar test verisinde geleneksel eğitimle elde edilen ağlarla eşleşiyor ya da onların önüne geçiyor; özellikle eğitim kaybı düşük olduğunda fark sıklıkla büyük oluyor. Sınıflandırma problemlerinde, yüksek kayıptaki yüksek entropili durumlar rastgele tahminciler gibi davranırken, düşük kayıpta en iyi ulaşılabilir doğruluğun yakınında yoğunlaşıyor; bu da yaklaşımın fiziksel tutarlılığını güçlendiriyor.
Neden daha küçük ağlarda etki daha güçlü
Bu avantajın ne zaman en belirgin olduğunu anlamak için yazarlar bir spiral regresyon görevi ve ilgili kıyaslamalarda sinir ağlarının genişliğini değiştiriyorlar. Ağlar genişledikçe — teoriye göre Gaussian süreçlere yaklaşan rejime doğru — yüksek entropi avantajının sürekli olarak küçüldüğünü ve çok geniş modellerde kaybolabileceğini buluyorlar. Yine de aşırı parametrik ama daha dar ağlar belirgin bir fark sergiliyor: yüksek entropili durumlar, standart eğitimle ulaşılmış durumlara kıyasla bariz şekilde daha iyi genelleşme gösteriyor. Bu, gerçekçi, sonlu genişlikteki ağlarda parametre uzayının yapısının ve eğitim algoritmalarının bunu nasıl keşfettiğinin genelleşme üzerinde önemli olduğu anlamına geliyor.
Daha iyi yapay zekâ inşası için çıkarımlar
Uzman olmayanlar için temel mesaj şudur: sinir ağlarında iyi genelleşme tesadüf değildir. Yazarlar, belirli bir eğitim performans düzeyinde iyi genelleyen çözümlerin genellikle kırılgan, aşırı uyumlu çözümlerden çok daha büyük bir "hacme" sahip olabileceğini gösteriyor. Stokastik gradyan inişi gibi eğitim yöntemleri bu büyük bölgelere ulaşmaya eğilimli olup, günümüzün aşırı parametrik modellerinin ağır düzenlemelere gerek kalmadan iyi performans göstermesini açıklıyor. Çalışma ayrıca pratik stratejilere işaret ediyor: eğitimi kasıtlı olarak maksimum entropi bölgelerine yönlendirmek — fizikten esinlenen optimizasyon yöntemleri kullanarak — mühendislerin yapay zekâ sistemlerini mimarilerini kökten değiştirmeden daha sağlam ve güvenilir hale getirmesini sağlayabilir.
Atıf: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Anahtar kelimeler: sinir ağı genelleştirmesi, makine öğreniminde entropi, kayıp peyzajı, aşırı parametrik modeller, Yapay zekanın istatistiksel fiziği