Clear Sky Science · fr
Avantage de haute entropie dans la généralisabilité des réseaux de neurones
Pourquoi cela compte pour l'IA du quotidien
Les systèmes d'intelligence artificielle modernes peuvent reconnaître des visages, traduire des langues et prédire les prix de l'immobilier avec une précision étonnante — et pourtant nous ne comprenons toujours pas complètement pourquoi ils fonctionnent si bien sur des données nouvelles et inédites. Cet article s'attaque à ce mystère en empruntant des concepts à la physique. Les auteurs montrent que les réseaux de neurones les plus fiables ne sont pas seulement ceux qui s'ajustent aux données d'entraînement, mais ceux qui résident dans des régions « spacieuses » de leur espace de paramètres internes, une propriété qu'ils appellent avantage de haute entropie.
Une nouvelle façon d'examiner l'intérieur des réseaux de neurones
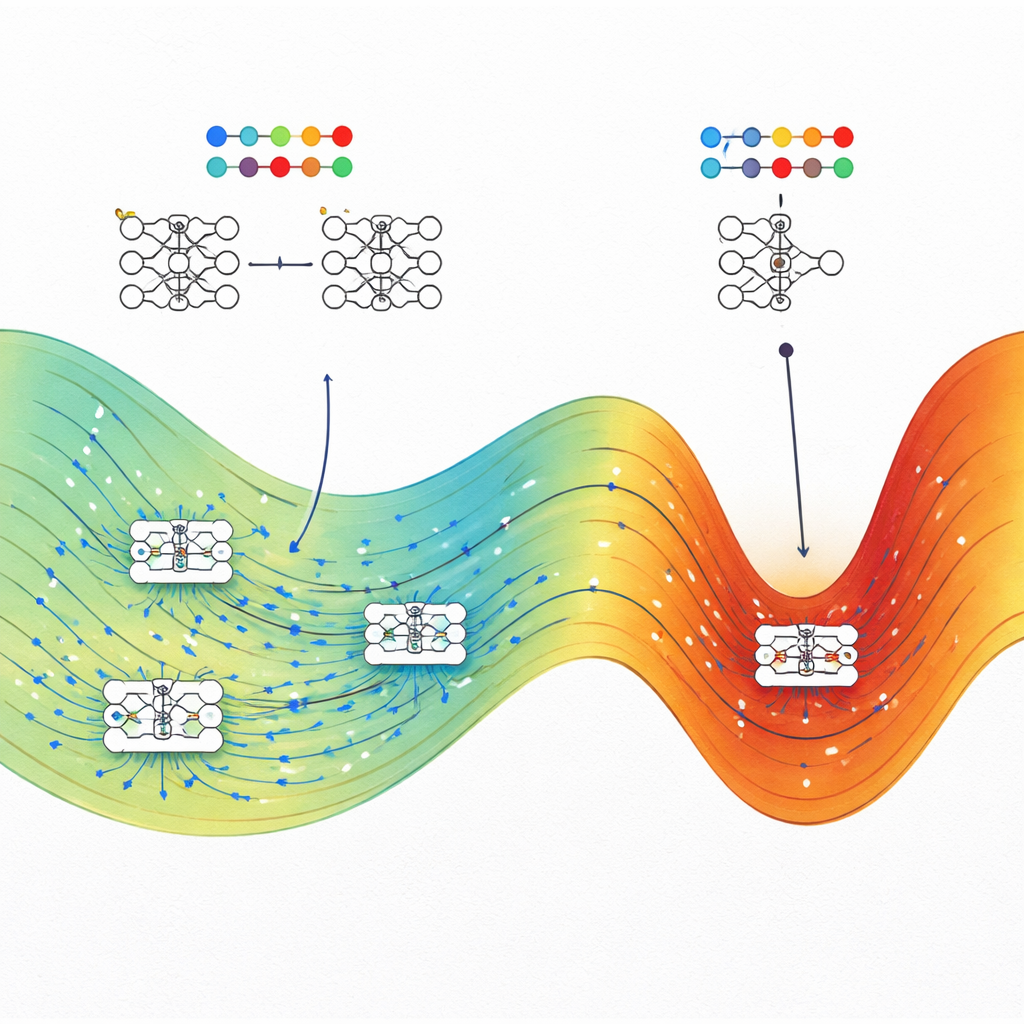
Plutôt que de traiter un réseau de neurones comme une boîte noire, les chercheurs imaginent chaque configuration possible de ses poids internes comme un point dans un vaste paysage. De nombreux points différents peuvent ajuster les données d'entraînement de la même façon, mais certaines de ces solutions se généralisent sur de nouvelles données et d'autres non. S'inspirant de la physique statistique, ils considèrent chaque configuration de poids comme un micro-état et ses performances globales — perte d'entraînement et précision au test — comme des grandeurs macroscopiques. La quantité clé qu'ils étudient est l'entropie, qui mesure ici l'étendue d'une région de l'espace des paramètres correspondant à un certain niveau de performance d'entraînement et de test.
Emprunter des outils aux simulations moléculaires
Compter directement combien de configurations de réseau atteignent une performance donnée est impossible, car il existe une infinité de réglages continus des poids. Pour contourner cet obstacle, les auteurs adaptent des algorithmes initialement développés pour étudier les molécules, connus sous le nom de Monte Carlo de Wang–Landau et de dynamique moléculaire de Wang–Landau. Dans leur analogie, chaque poids du réseau agit comme une coordonnée atomique, et la fonction de perte joue le rôle d'énergie potentielle. Ces méthodes d'échantillonnage leur permettent de cartographier un « paysage d'entropie » qui montre, pour chaque combinaison de perte d'entraînement et de précision au test (ou de perte au test), quelle portion de l'espace des paramètres est occupée.
Les états de haute entropie gagnent sur de nombreuses tâches
L'équipe applique ce cadre à quatre problèmes très différents : une tâche de classification spirale jouet, la prédiction des prix de l'immobilier à partir de données tabulaires, la reconnaissance de chiffres manuscrits sur un jeu de données MNIST réduit, et la prédiction des énergies de bande des polymères à partir de chaînes chimiques. Dans chaque cas, ils comparent les réseaux typiques entraînés avec des optimiseurs standard, tels que la descente de gradient stochastique (ou Adam pour une tâche de régression), aux états de plus haute entropie trouvés pour la même perte d'entraînement. De manière cohérente, les états de haute entropie égalent ou surpassent les réseaux entraînés de façon conventionnelle sur les données de test, souvent de façon marquée lorsque la perte d'entraînement est faible. Dans les problèmes de classification, les états de haute entropie à forte perte se comportent comme des devineurs aléatoires, tandis qu'à faible perte ils se concentrent près de la meilleure précision atteignable, confirmant la cohérence physique de l'approche.
Pourquoi l'effet est plus marqué sur les réseaux plus petits
Pour comprendre quand cet avantage est le plus prononcé, les auteurs font varier la largeur des réseaux sur une tâche de régression spirale et des bancs d'essai associés. Ils constatent que, à mesure que les réseaux s'élargissent — approchant le régime où la théorie prédit qu'ils se comportent comme des processus gaussiens — l'avantage de haute entropie diminue régulièrement et peut même disparaître pour des modèles très larges. Les réseaux plus étroits, encore surparamétrés, présentent un écart net : les états de haute entropie généralisent sensiblement mieux que les états atteints par l'entraînement standard. Cela suggère que, dans des réseaux réalistes de largeur finie, la structure de l'espace des paramètres et la façon dont les algorithmes d'entraînement l'explorent influencent la généralisation.
Ce que cela implique pour construire une IA meilleure
Le message central pour les non-spécialistes est que la bonne généralisation des réseaux de neurones n'est pas un hasard. Les auteurs montrent qu'à un niveau donné de performance d'entraînement, les solutions qui généralisent bien occupent typiquement un « volume » beaucoup plus grand de réglages de paramètres possibles que les solutions fragiles et surajustées. Les méthodes d'entraînement comme la descente de gradient stochastique ont tendance à aboutir dans ces grandes régions, ce qui explique pourquoi les modèles surparamétrés d'aujourd'hui peuvent bien fonctionner sans régularisation lourde. Le travail suggère aussi des stratégies pratiques : en orientant délibérément l'entraînement vers des régions de maximale entropie — en utilisant des méthodes d'optimisation inspirées de la physique — les ingénieurs pourraient rendre les systèmes d'IA plus robustes et fiables sans repenser entièrement leurs architectures.
Citation: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Mots-clés: généralisation des réseaux de neurones, entropie en apprentissage automatique, paysage de perte, modèles surparamétrés, physique statistique de l'IA