Clear Sky Science · pt
Vantagem de alta entropia na generalização de redes neurais
Por que isso importa para a IA do dia a dia
Sistemas modernos de inteligência artificial conseguem reconhecer rostos, traduzir idiomas e prever preços de imóveis com precisão impressionante — e, ainda assim, não entendemos completamente por que se saem tão bem em dados novos e não vistos. Este artigo aborda esse mistério usando ideias emprestadas da física. Os autores mostram que as redes neurais mais confiáveis não são apenas as que se ajustam aos dados de treino, mas aquelas que habitam regiões “espaciosas” do espaço de parâmetros internos, uma propriedade que eles chamam de vantagem de alta entropia.
Uma nova maneira de olhar dentro das redes neurais
Em vez de tratar uma rede neural como uma caixa preta, os pesquisadores imaginam cada possível configuração de seus pesos internos como um ponto em uma vasta paisagem. Muitos pontos diferentes podem ajustar igualmente bem os dados de treino, mas algumas dessas soluções generalizam para novos dados e outras não. Com base na física estatística, eles tratam cada configuração específica de pesos como um microestado e seu desempenho global — perda de treino e acurácia no teste — como propriedades macroscópicas. A grande quantidade que estudam é a entropia, que aqui mede quão grande é a região do espaço de parâmetros correspondente a um dado nível de desempenho de treino e de teste.
Emprestando ferramentas de simulações moleculares
Contar diretamente quantas configurações de rede alcançam um desempenho particular é impossível, porque existem infinitas configurações contínuas de pesos. Para contornar isso, os autores adaptam algoritmos originalmente desenvolvidos para estudar moléculas, conhecidos como Monte Carlo de Wang–Landau e Dinâmica Molecular de Wang–Landau. Na analogia deles, cada peso da rede atua como uma coordenada atômica, e a função de perda desempenha o papel de energia potencial. Esses métodos de amostragem permitem mapear uma “paisagem de entropia” que mostra, para cada combinação de perda de treino e acurácia de teste (ou perda de teste), quanto do espaço de parâmetros está ocupado.
Estados de alta entropia vencem em várias tarefas
A equipe aplica esse quadro a quatro problemas muito diferentes: uma tarefa-teste de classificação em espiral, prever preços de imóveis a partir de dados tabulares, reconhecer dígitos manuscritos em uma versão reduzida do MNIST e prever energias de bandgap de polímeros a partir de sequências químicas. Em cada caso, eles comparam redes típicas treinadas com otimizadores padrão, como gradiente estocástico (ou Adam em uma das tarefas de regressão), com os estados de maior entropia encontrados para a mesma perda de treino. Consistentemente, os estados de alta entropia igualam ou superam as redes treinadas convencionalmente em dados de teste, muitas vezes por uma margem ampla quando a perda de treino é baixa. Em problemas de classificação, estados de alta entropia com perda alta se comportam como chutes aleatórios, enquanto em perda baixa concentram-se perto da melhor acurácia alcançável, reforçando a consistência física da abordagem.
Por que redes menores mostram um efeito mais forte
Para entender quando essa vantagem é mais pronunciada, os autores variam a largura das redes neurais em uma tarefa de regressão em espiral e benchmarks relacionados. Eles descobrem que, conforme as redes ficam mais largas — aproximando-se do regime em que a teoria prevê comportamento como processos gaussianos — a vantagem de alta entropia diminui continuamente e pode até desaparecer para modelos muito largos. Redes mais estreitas, ainda assim superparametrizadas, exibem uma lacuna clara: estados de alta entropia generalizam de forma perceptivelmente melhor do que os estados alcançados pelo treinamento padrão. Isso sugere que, em redes realistas de largura finita, tanto a estrutura do espaço de parâmetros quanto a forma como os algoritmos de treino o exploram importam para a generalização.
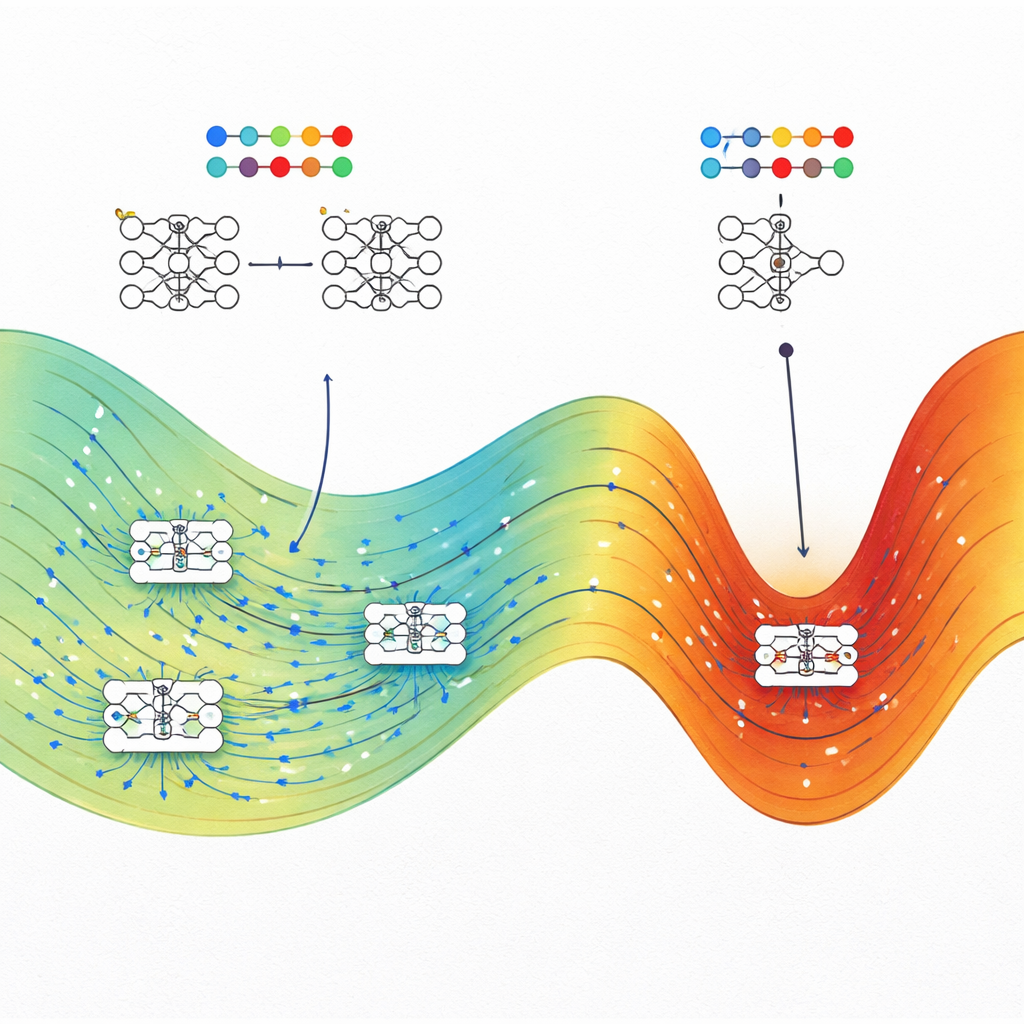
O que isso significa para construir IA melhores
A mensagem central para não especialistas é que a boa generalização em redes neurais não é um acidente. Os autores mostram que, para um dado nível de desempenho de treino, soluções que generalizam bem tipicamente ocupam um “volume” muito maior de possíveis configurações de parâmetros do que soluções frágeis e sobreajustadas. Métodos de treinamento como o gradiente estocástico tendem a cair nessas grandes regiões, explicando por que os modelos atualmente superparametrizados ainda podem ter bom desempenho sem regularização excessiva. O trabalho também indica estratégias práticas: ao direcionar deliberadamente o treinamento para regiões de máxima entropia — usando métodos de otimização inspirados na física — engenheiros podem tornar sistemas de IA mais robustos e confiáveis sem redesenhar suas arquiteturas do zero.
Citação: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Palavras-chave: generalização de redes neurais, entropia em aprendizado de máquina, paisagem de perda, modelos superparametrizados, física estatística da IA