Clear Sky Science · de
Vorteil hoher Entropie für die Generalisierbarkeit neuronaler Netze
Warum das für Alltags-KI wichtig ist
Moderne künstliche Intelligenzsysteme erkennen Gesichter, übersetzen Sprachen und sagen Immobilienpreise mit verblüffender Genauigkeit voraus – trotzdem verstehen wir noch nicht vollständig, warum sie auf neuen, ungesehenen Daten so gut funktionieren. Dieses Papier geht dem Rätsel mit Ideen aus der Physik nach. Die Autorinnen und Autoren zeigen, dass die zuverlässigsten neuronalen Netze nicht nur diejenigen sind, die die Trainingsdaten fitten, sondern jene, die in „geräumigen“ Regionen ihres internen Parameterraums liegen — eine Eigenschaft, die sie als Vorteil hoher Entropie bezeichnen.
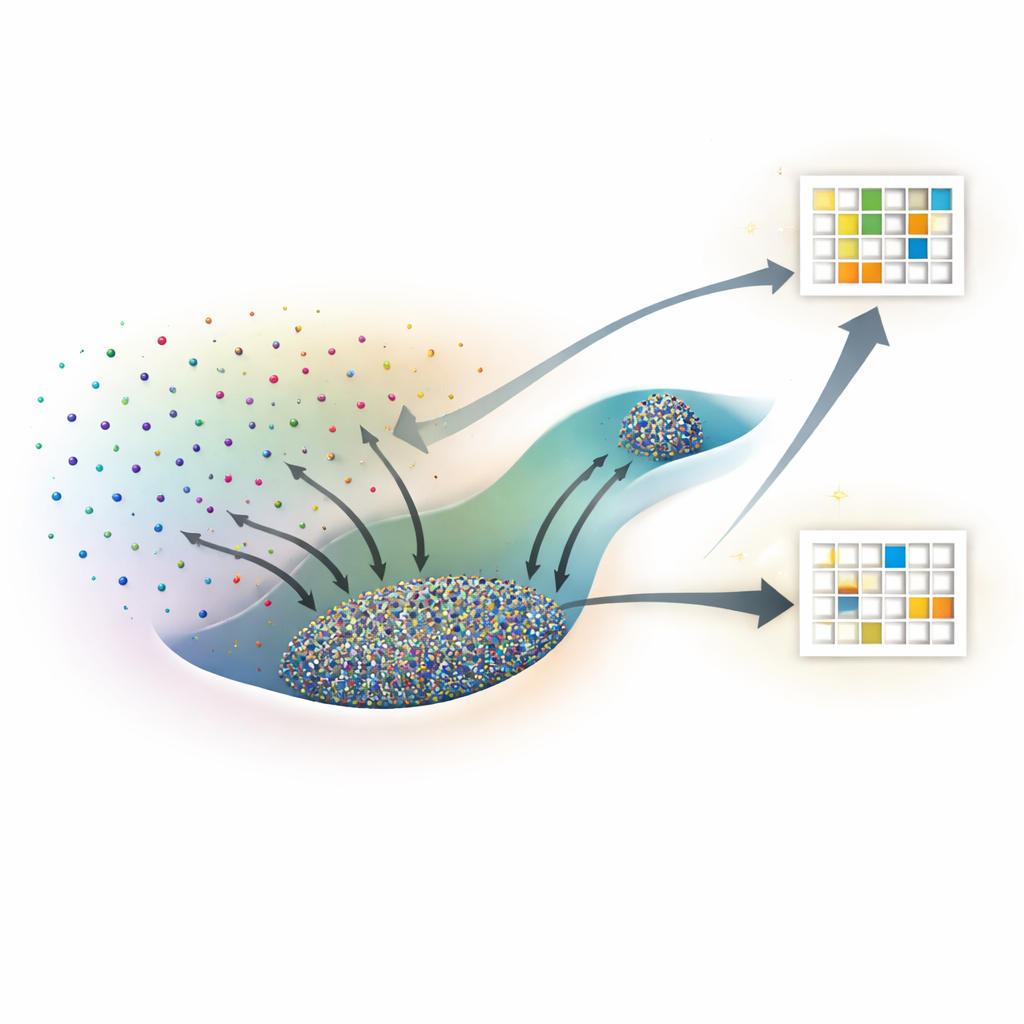
Eine neue Sicht in neuronale Netze
Anstatt ein neuronales Netz als Blackbox zu behandeln, stellen sich die Forschenden jede mögliche Einstellung seiner internen Gewichte als Punkt in einer gewaltigen Landschaft vor. Viele verschiedene Punkte können die Trainingsdaten gleichermaßen gut beschreiben, aber einige dieser Lösungen generalisieren auf neue Daten und andere nicht. Anknüpfend an die statistische Physik behandeln sie jede spezifische Gewichts-Konfiguration als Mikrozustand und ihre Gesamtleistung — Trainingsverlust und Testgenauigkeit — als makroskopische Eigenschaften. Die zentrale Größe, die sie untersuchen, ist die Entropie, die hier misst, wie groß eine Region des Parameterraums ist, die einem bestimmten Niveau von Trainings- und Testleistung entspricht.
Werkzeuge aus der Molekularsimulation
Die direkte Zählung, wie viele Netzwerkkonfigurationen eine bestimmte Leistung erreichen, ist unmöglich, weil es unendlich viele kontinuierliche Gewichtseinstellungen gibt. Um das zu umgehen, adaptieren die Autorinnen und Autoren Algorithmen, die ursprünglich zur Untersuchung von Molekülen entwickelt wurden, bekannt als Wang–Landau Monte Carlo und Wang–Landau Molecular Dynamics. In ihrer Analogie wirkt jedes Netzwerkgewicht wie eine atomare Koordinate, und die Verlustfunktion übernimmt die Rolle der potentiellen Energie. Diese Stichprobenverfahren erlauben es ihnen, eine „Entropielandschaft“ abzubilden, die für jede Kombination aus Trainingsverlust und Testgenauigkeit (oder Testverlust) zeigt, wie viel Parameterraum belegt ist.
High-Entropy-Zustände siegen in vielen Aufgaben
Das Team wendet dieses Rahmenwerk auf vier sehr unterschiedliche Probleme an: eine einfache Spiral-Klassifikationsaufgabe, die Vorhersage von Immobilienpreisen aus tabellarischen Daten, die Erkennung handgeschriebener Ziffern aus einem reduzierten MNIST-Datensatz und die Vorhersage von Polymer-Bandlückenenergien aus chemischen Strings. In jedem Fall vergleichen sie typische Netze, die mit Standardoptimierern trainiert wurden, wie stochastischem Gradientenabstieg (oder Adam in einer Regressionsaufgabe), mit den bei gleichem Trainingsverlust gefundenen Zuständen mit höchster Entropie. Konsistent schneiden die High-Entropy-Zustände bei Testdaten gleich gut oder besser ab als konventionell trainierte Netze, oft mit deutlichem Vorsprung bei niedrigem Trainingsverlust. In Klassifikationsproblemen verhalten sich High-Entropy-Zustände bei hohem Verlust wie zufällige Rater, während sie bei niedrigem Verlust nahe der besten erreichbaren Genauigkeit konzentriert sind, was die physikalische Konsistenz des Ansatzes untermauert.
Warum kleinere Netze einen stärkeren Effekt zeigen
Um zu verstehen, wann dieser Vorteil am deutlichsten ist, variieren die Autorinnen und Autoren die Breite neuronaler Netze bei einer Spiral-Regressionaufgabe und verwandten Benchmarks. Sie finden, dass der High-Entropy-Vorteil mit zunehmender Breite — in Richtung des Bereichs, in dem Theorie ein Verhalten wie ein Gauß-Prozess vorhersagt — stetig schrumpft und bei sehr breiten Modellen sogar verschwinden kann. Schmalere, dennoch überparametrisierte Netze zeigen eine klare Lücke: High-Entropy-Zustände generalisieren spürbar besser als die Zustände, die durch Standardtraining erreicht werden. Das legt nahe, dass in realistischen Netzen mit endlicher Breite die Struktur des Parameterraums und die Art und Weise, wie Trainingsalgorithmen ihn erkunden, beide eine Rolle für die Generalisierung spielen.
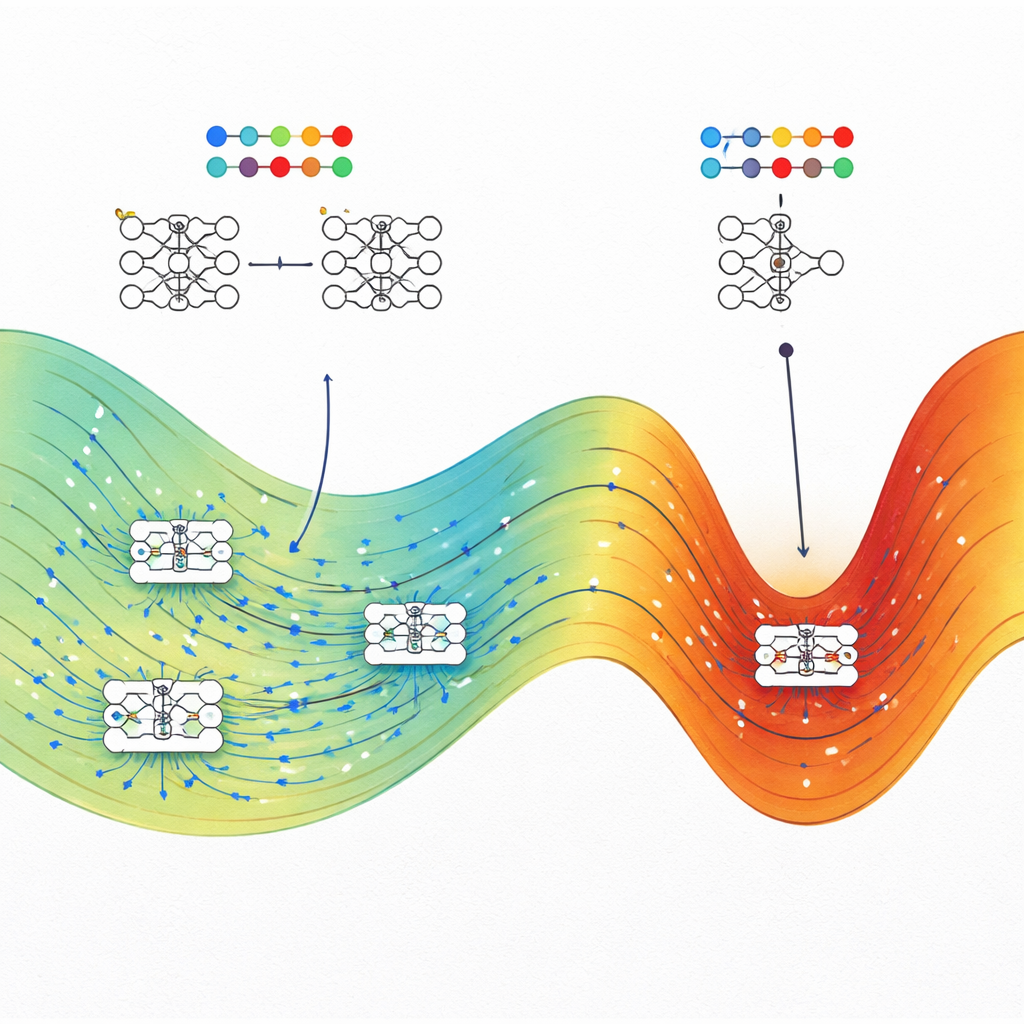
Was das für den Bau besserer KI bedeutet
Die zentrale Botschaft für Nicht-Spezialisten ist, dass gute Generalisierung in neuronalen Netzen kein Zufall ist. Die Autorinnen und Autoren zeigen, dass bei gleichem Trainingsleistungniveau gut generalisierende Lösungen typischerweise ein viel größeres „Volumen“ möglicher Parameterstellungen einnehmen als spröde, überangepasste Lösungen. Trainingsmethoden wie stochastischer Gradientenabstieg landen oft in diesen großen Regionen, was erklärt, warum heutige überparametrische Modelle ohne starke Regularisierung gut funktionieren können. Die Arbeit deutet auch auf praktische Strategien hin: Indem man das Training gezielt in Richtung maximaler Entropie-Regionen steuert — mithilfe physik-inspirierter Optimierungsmethoden — könnten Ingenieurinnen und Ingenieure KI-Systeme robuster und verlässlicher machen, ohne ihre Architekturen von Grund auf neu entwerfen zu müssen.
Zitation: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Schlüsselwörter: Generalisierung neuronaler Netze, Entropie im maschinellen Lernen, Verlustlandschaft, überparametrisierte Modelle, statistische Physik der KI