Clear Sky Science · he
יתרון אנטרופיה גבוהה ביכולת ההכללה של רשתות עצביות
מדוע זה חשוב לבינה מלאכותית בחיי היומיום
מערכות בינה מלאכותית מודרניות יכולות לזהות פנים, לתרגם שפות ולחזות מחירי דירות בדיוק מדהים — ועדיין אנחנו לא מבינים במלואו מדוע הן עובדות היטב על נתונים חדשים שלא נראו קודם. המאמר הזה מתמודד עם התעלומה באמצעות רעיונות שנלקחו מהפיזיקה. הכותבים מראים שהרשתות העצביות האמינות ביותר אינן רק אלה שמתאימות את נתוני האימון, אלא אלה שגורלותיהן נמצאים באזורי פרמטרים "מרווחים" בתוך מרחב הפרמטרים הפנימי שלהן, תכונה שהם מכנים יתרון אנטרופיה גבוהה.
דרך חדשה להסתכל פנימה לתוך רשתות עצביות
במקום להתייחס לרשת העצבית כקופסה שחורה, החוקרים מדמיינים שכל הגדרות המשקלים האפשריות שלה הן נקודות בנוף עצום. נקודות רבות שונות יכולות להתאים את נתוני האימון באותה מידה, אך חלק מהפתרונות הללו מתכללים על נתונים חדשים ואחרים לא. בהתבסס על פיזיקה סטטיסטית, הם מתייחסים לכל תצורת משקלים כמצב מיקרו ולביצוע הכולל — איבוד אימון ודיוק בבדיקה — כתכונות מקרוסקופיות. הכמות המרכזית שהם חוקרים היא אנטרופיה, שמודדת כאן עד כמה גדול האזור במרחב הפרמטרים שמתאים לרמת ביצוע נתונה באימון ובבדיקה.
הלוואת כלים מסימולציות מולקולריות
ספירה ישירה של כמה תצורות של רשת עושות ביצועים מסוימים היא בלתי אפשרית, כי קיימות אינסוף הגדרות משקל רציפות. כדי להתגבר על כך, המחברים מאמצים אלגוריתמים שתוכננו במקור ללימוד מולקולות, הידועים כ-Wang–Landau Monte Carlo ו-Wang–Landau Molecular Dynamics. באנלוגיה שלהם, כל משקל ברשת מתפקד כמו קורדינטת אטום, ופונקציית האובדן ממלאת את תפקיד אנרגיית הפוטנציאל. שיטות דגימה אלו מאפשרות להם למפות "נוף אנטרופיה" שמראה, עבור כל צירוף של איבוד אימון ודיוק בבדיקה (או איבוד בבדיקה), כמה מהמרחב הפרמטרי תופס אותו הצירוף.
מצבים בעלי אנטרופיה גבוהה מנצחים במשימות רבות
הקבוצה מחילה מסגרת זו על ארבע בעיות שונות מאוד: משימת סיווג ספירלית צעצועית, חיזוי מחירי דירות מנתוני טבלאות, זיהוי ספרות בכתב יד ממערכת MNIST מצומצמת, וחיזוי אנרגיות מרווחי הלהקה של פולימרים מתוך מחרוזות כימיות. בכל מקרה הם משווים בין רשתות טיפוסיות שאומנו בעזרת ממטבים סטנדרטיים, כגון ירידת שיפוע אקראית (או Adam במשימת רגרסיה אחת), לבין המצבים בעלי האנטרופיה הגבוהה ביותר שנמצאו באותו איבוד אימון. בעקביות, המצבים בעלי האנטרופיה הגבוהה מתואמים עם או עוקפים את הרשתות המאומנות קונבנציונלית על נתוני בדיקה, לעתים בהפרש ניכר כאשר איבוד האימון נמוך. בבעיות סיווג, מצבים בעלי אנטרופיה גבוהה בעת איבוד גבוה מתנהגים כניחושים אקראיים, בעוד שבאיבוד נמוך הם מתרכזים קרוב לדיוק הטוב ביותר שניתן להשיג, מה שמחזק את ההתאמה הפיזיקלית של הגישה.
מדוע לרשתות קטנות התופעה בולטת יותר
כדי להבין מתי היתרון הזה בולט ביותר, המחברים משנים את הרוחב של רשתות עצביות במשימת רגרסיית ספירלה ובמדדים מקבילים. הם מגלים שכאשר הרשתות הופכות לרחבות יותר — מתקרבות למשטר שבו התיאוריה אומרת שהן מתנהגות כמו תהליכים גאוסיים — היתרון של אנטרופיה גבוהה מצטמצם בהתמדה ויכול אפילו להיעלם במודלים רחבים מאוד. רשתות צרות יותר, שעדיין בעלות פרמטריזציה-יתר, מציגות פער ברור: מצבים עם אנטרופיה גבוהה מתכללים בצורה ניכרת טוב יותר מהמקומות שאליהם מגיעה האימון הסטנדרטי. זה מרמז שברשתות ברוחב סופי ריאליסטי, גם מבנה מרחב הפרמטרים וגם הדרך שבה אלגוריתמי האימון חוקרים אותו משפיעים על ההכללה.
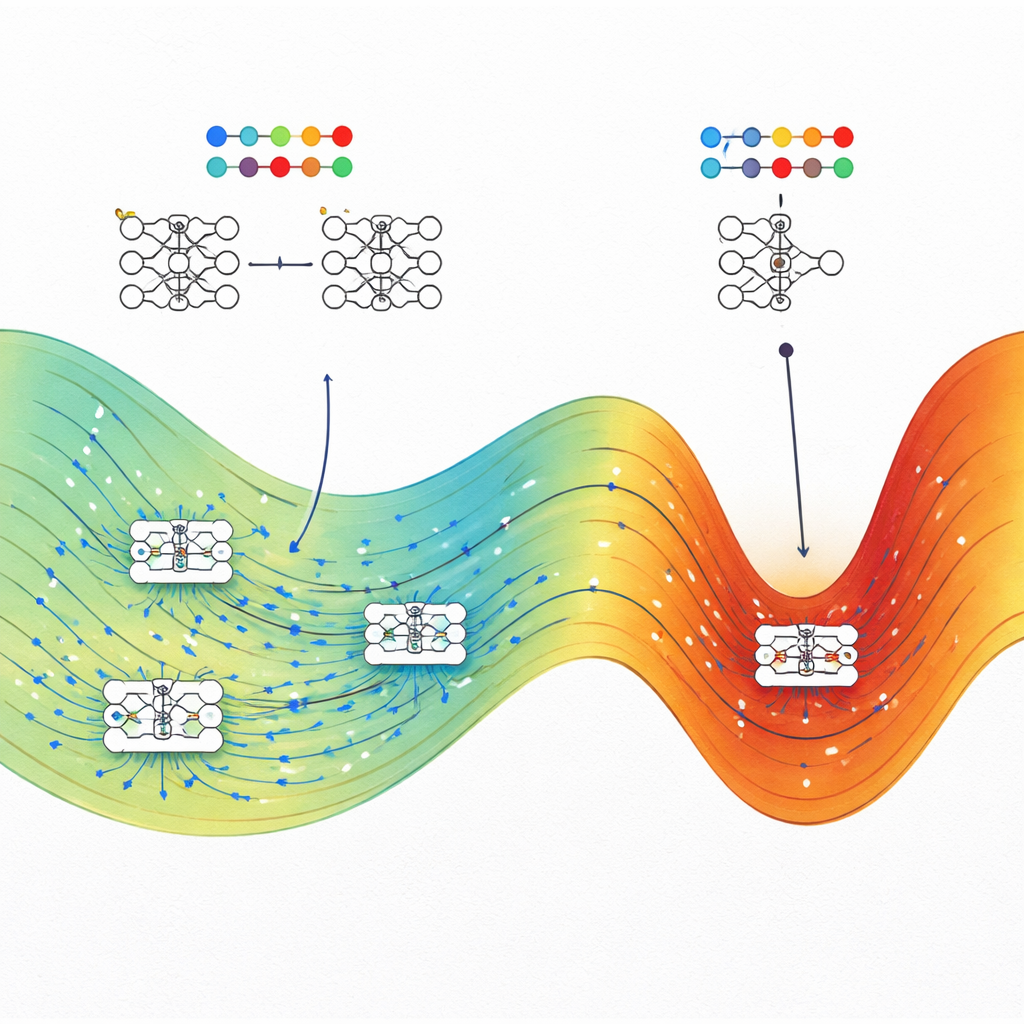
מה המשמעות של זה לבניית בינה מלאכותית טובה יותר
המסר המרכזי לקוראים לא-מומחים הוא שהכללה טובה ברשתות עצביות אינה מקרית. המחברים מראים שבאותו רמת ביצוע על האימון, פתרונות שמתכללים היטב בדרך כלל תופסים "נפח" גדול בהרבה של הגדרות פרמטרים אפשריות מאשר פתרונות שבירים ומתאמי-יתר. שיטות אימון כמו ירידת שיפוע סטוכסטית נוטות לנחות באזורים הגדולים האלה, מה שמסביר מדוע המודלים בעלי פרמטריזציה-יתר של היום עדיין יכולים לעבוד היטב בלי רגולציה כבדה. העבודה גם מרמזת על אסטרטגיות מעשיות: על-ידי הכוונת האימון במכוון לעבר אזורי אנטרופיה-מקסימלית — באמצעות שיטות אופטימיזציה בהשראת פיזיקה — מהנדסים עשויים להפוך מערכות AI לעמידות ומהימנות יותר ללא צורך בעיצוב מחדש של הארכיטקטורות מהיסוד.
ציטוט: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
מילות מפתח: הכללת רשתות עצביות, אנטרופיה בלמידת מכונה, נוף פונקציית האובדן, מודלים עם פרמטריזציה יתרה, פיזיקה סטטיסטית של בינה מלאכותית