Clear Sky Science · ja
ニューラルネットワークの汎化性における高エントロピー優位性
日常のAIにとってなぜ重要か
現代の人工知能システムは顔認識、言語翻訳、住宅価格の予測などを驚くほど高精度にこなしますが、未知のデータへの適用でなぜうまく機能するのかは完全には解明されていません。本論文は物理学から借用したアイデアを用いてこの謎に取り組みます。著者たちは、信頼できるニューラルネットワークとは単に訓練データに適合するものではなく、その内部パラメータ空間の「広い」領域に存在するものであり、これを高エントロピー優位性と呼ぶ性質であると示します。
ニューラルネットワークの内部を見通す新たな視点
ニューラルネットワークをブラックボックスとして扱う代わりに、研究者たちは内部の重みのすべての設定を広大なランドスケープ上の点とみなします。訓練データに同等に適合する多くの点が存在しますが、その中には新たなデータへ良く汎化するものとしないものがあります。統計物理学を応用して、各重みの具体的な設定をミクロ状態と見なし、その全体的な振る舞い(訓練損失やテスト精度)を巨視的な性質として扱います。彼らが注目する主要な量はエントロピーで、ここでは特定の訓練・テスト性能レベルに対応するパラメータ空間の領域の大きさを測る指標です。
分子シミュレーションからの手法借用
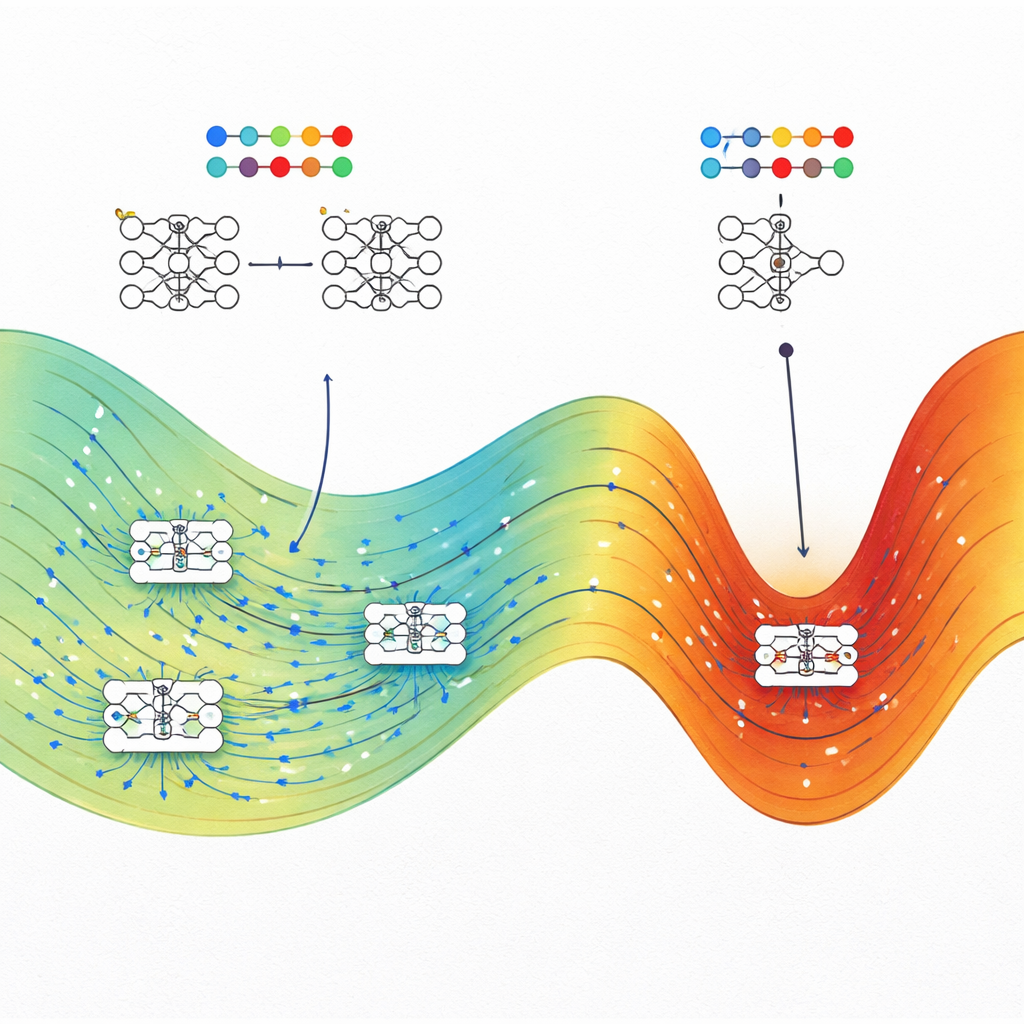
ある性能を達成するネットワーク設定の数を直接数えることは不可能です。重みは連続値で無数に存在するからです。これを回避するために、著者らは分子の研究で開発されたアルゴリズム、具体的にはワン・ランドウ(Wang–Landau)モンテカルロとワン・ランドウ分子動力学を応用します。ここでの比喩では各ネットワーク重みは原子の座標のように振る舞い、損失関数は位置エネルギーに相当します。これらのサンプリング手法により、訓練損失とテスト精度(またはテスト損失)の各組み合わせに対してパラメータ空間がどれだけ占有されているかを示す「エントロピーランドスケープ」を描き出せます。
多様なタスクで勝る高エントロピー状態
研究チームはこの枠組みを、トイのスパイラル分類課題、表形式データからの住宅価格予測、縮小版MNISTデータセットによる手書き数字認識、化学文字列からの高分子バンドギャップエネルギー予測という4つの異なる問題に適用しました。各ケースで、確率的勾配降下法(回帰の1例ではAdam)などの標準的最適化で訓練した典型的なネットワークと、同じ訓練損失で見つかった最高エントロピー状態を比較しています。一貫して、高エントロピー状態はテストデータ上で従来の訓練済みネットワークと同等かそれ以上の性能を示し、特に訓練損失が低い場合には大きな差をつけることが多いです。分類問題では、損失が高い高エントロピー状態はランダム推測者のように振る舞いますが、損失が低いときは到達可能な最高精度付近に集中し、このアプローチの物理的一貫性を裏付けます。
なぜより小さなネットワークで効果が強く出るのか
この優位性がいつ最も顕著になるかを理解するため、著者らはスパイラル回帰課題と関連ベンチマークでネットワークの幅を変化させました。ネットワークが広くなり、理論上ガウス過程のように振る舞う領域に近づくと、高エントロピー優位性は徐々に小さくなり、非常に広いモデルでは消えることさえあります。対照的に、より狭く、それでも過剰パラメータ化されたネットワークでは明確な差が現れます:高エントロピー状態は標準的な訓練で到達した状態よりも明らかに良く汎化します。これは、現実的な有限幅ネットワークではパラメータ空間の構造と訓練アルゴリズムの探索の仕方が汎化に影響することを示唆します。
より良いAIを作るための含意
専門外の読者への中心的なメッセージは、ニューラルネットワークの良好な汎化は偶然ではないということです。著者らは、ある訓練性能レベルにおいて、良く汎化する解が壊れやすい過学習的な解よりもはるかに大きな「体積」を占めることが多いと示しています。確率的勾配降下法のような訓練手法はこれらの大きな領域に落ち着く傾向があり、今日の過剰パラメータ化モデルが強い正則化を加えなくても高性能を発揮できる理由を説明します。本研究はまた実践的な戦略を示唆します:物理学に触発された最適化手法などで訓練を意図的に最大エントロピー領域へ導くことで、アーキテクチャを根本的に作り替えることなくAIシステムをより堅牢で信頼性の高いものにできる可能性があります。
引用: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
キーワード: ニューラルネットワークの汎化, 機械学習におけるエントロピー, 損失ランドスケープ, 過剰パラメータ化モデル, AIの統計物理学