Clear Sky Science · it
Vantaggio dell'alta entropia nella generalizzabilità delle reti neurali
Perché questo conta per l'IA di tutti i giorni
I sistemi di intelligenza artificiale moderni sono in grado di riconoscere volti, tradurre lingue e prevedere i prezzi delle case con sorprendente accuratezza—eppure non comprendiamo ancora del tutto perché funzionino così bene su dati nuovi e non visti. Questo articolo affronta il mistero usando idee tratte dalla fisica. Gli autori mostrano che le reti neurali più affidabili non sono solo quelle che si adattano ai dati di addestramento, ma quelle che risiedono in regioni “ampie” dello spazio dei loro parametri interni, una proprietà che chiamano vantaggio dell'alta entropia.
Un nuovo modo di guardare dentro le reti neurali
Invece di trattare una rete neurale come una scatola nera, i ricercatori immaginano ogni possibile configurazione dei suoi pesi interni come un punto in un vasto paesaggio. Molti punti diversi possono adattarsi ugualmente bene ai dati di addestramento, ma alcune di quelle soluzioni generalizzano ai nuovi dati e altre no. Attraendo concetti dalla fisica statistica, considerano ogni configurazione specifica dei pesi come un microstato e le sue prestazioni complessive—loss di addestramento e accuratezza sul test—come proprietà macroscopiche. La quantità chiave che studiano è l'entropia, che qui misura quanto è estesa una regione dello spazio dei parametri corrispondente a un dato livello di prestazioni in addestramento e test.
Pescare strumenti dalle simulazioni molecolari
Contare direttamente quante configurazioni di rete raggiungono una particolare prestazione è impossibile, perché esistono infiniti valori continui dei pesi. Per ovviare a questo, gli autori adattano algoritmi sviluppati originariamente per studiare le molecole, noti come Wang–Landau Monte Carlo e Wang–Landau Molecular Dynamics. Nella loro analogia, ogni peso di rete agisce come una coordinata atomica e la funzione di loss assume il ruolo di energia potenziale. Questi metodi di campionamento consentono di mappare un “paesaggio di entropia” che mostra, per ogni combinazione di loss di addestramento e accuratezza sul test (o loss sul test), quanta parte dello spazio dei parametri è occupata.
Gli stati ad alta entropia vincono in molti compiti
Il team applica questo quadro a quattro problemi molto diversi: un compito giocattolo di classificazione a spirale, la previsione dei prezzi delle case da dati tabulari, il riconoscimento di cifre scritte a mano su una versione ridotta di MNIST e la previsione delle energie di bandgap dei polimeri a partire da stringhe chimiche. In ciascun caso confrontano reti tipiche addestrate con ottimizzatori standard, come lo stochastic gradient descent (o Adam in un task di regressione), con gli stati di entropia massima trovati allo stesso valore di loss di addestramento. Coerentemente, gli stati ad alta entropia eguagliano o superano le reti addestrate convenzionalmente sui dati di test, spesso con un margine ampio quando la loss di addestramento è bassa. Nei problemi di classificazione, gli stati ad alta entropia ad alta loss si comportano come ipotesi casuali, mentre a bassa loss si concentrano vicino alla migliore accuratezza raggiungibile, rafforzando la coerenza fisica dell'approccio.
Perché le reti più piccole mostrano un effetto più forte
Per capire quando questo vantaggio è più pronunciato, gli autori variano la larghezza delle reti neurali in un compito di regressione a spirale e in benchmark correlati. Trovano che, man mano che le reti diventano più larghe—avvicinandosi al regime in cui la teoria le tratta come processi gaussiani—il vantaggio dell'alta entropia diminuisce costantemente e può anche scomparire per modelli molto larghi. Reti più strette, pur sovra-parametrizzate, mostrano un divario evidente: gli stati ad alta entropia generalizzano significativamente meglio rispetto agli stati raggiunti dall'addestramento standard. Questo suggerisce che, nelle reti realistiche a larghezza finita, sia la struttura dello spazio dei parametri sia il modo in cui gli algoritmi di training lo esplorano contano per la generalizzazione.
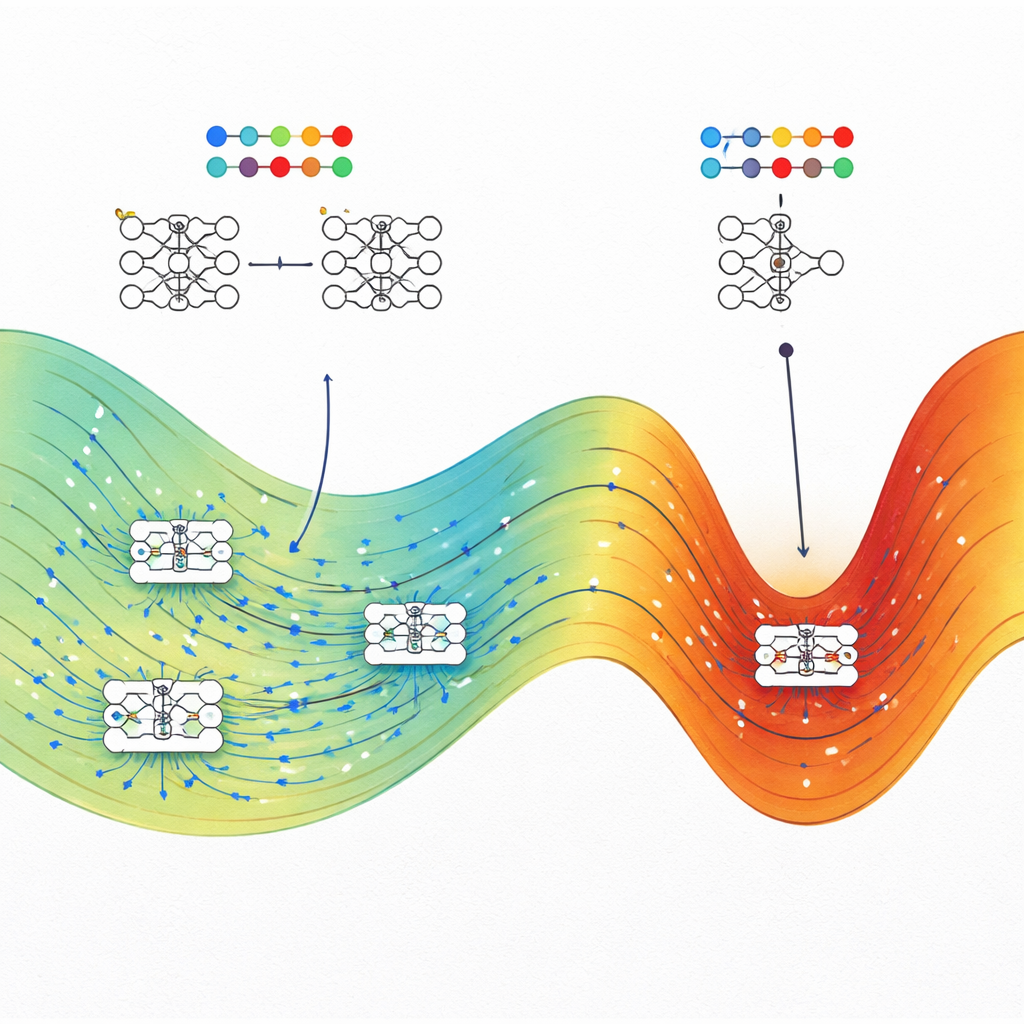
Cosa significa questo per costruire IA migliori
Il messaggio centrale per i non specialisti è che una buona generalizzazione nelle reti neurali non è un caso. Gli autori mostrano che, a parità di prestazioni di addestramento, le soluzioni che generalizzano bene occupano tipicamente un "volume" molto più grande di possibili configurazioni di parametri rispetto a quelle fragili e overfitted. Metodi di training come lo stochastic gradient descent tendono a fermarsi in queste ampie regioni, spiegando perché i modelli sovra-parametrizzati di oggi possono comunque funzionare bene senza ricorrere a regolarizzazioni pesanti. Il lavoro suggerisce anche strategie pratiche: orientando intenzionalmente l'addestramento verso regioni a entropia massima—usando metodi di ottimizzazione ispirati alla fisica—gli ingegneri potrebbero rendere i sistemi di IA più robusti e affidabili senza riprogettare da zero le architetture.
Citazione: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Parole chiave: generalizzazione delle reti neurali, entropia nel machine learning, paesaggio della loss, modelli sovra-parametrizzati, fisica statistica dell'IA