Clear Sky Science · sv
Fördel med hög entropi för neurala nätverks generaliserbarhet
Varför detta spelar roll för vardaglig AI
Moderna artificiella intelligenssystem kan känna igen ansikten, översätta språk och förutse bostadspriser med förbluffande noggrannhet — ändå förstår vi fortfarande inte fullt ut varför de fungerar så bra på nya, osedda data. Denna artikel tar sig an den gåtan med idéer hämtade från fysiken. Författarna visar att de mest tillförlitliga neurala nätverken inte bara är de som passar träningsdata, utan de som befinner sig i "rymliga" regioner av sitt interna parameterutrymme, en egenskap de kallar fördel med hög entropi.
En ny syn inuti neurala nätverk
I stället för att betrakta ett neuralt nätverk som en svart låda föreställer sig forskarna varje möjlig konfiguration av dess interna vikter som en punkt i ett enormt landskap. Många olika punkter kan passa träningsdatan lika bra, men vissa av dessa lösningar generaliserar till ny data och andra gör det inte. Med hjälp av statistisk fysik behandlar de varje specifik viktkonfiguration som ett mikro-tillstånd och dess övergripande prestanda — träningsförlust och testnoggrannhet — som makroskopiska egenskaper. Den centrala storheten de studerar är entropi, som här mäter hur stor en region av parameterutrymmet är som motsvarar en viss nivå av tränings- och testprestanda.
Lånar verktyg från molekylära simuleringar
Att direkt räkna hur många nätverkskonfigurationer som uppnår en viss prestanda är omöjligt, eftersom det finns oändligt många kontinuerliga viktinställningar. För att komma runt detta anpassar författarna algoritmer ursprungligen utvecklade för att studera molekyler, kända som Wang–Landau Monte Carlo och Wang–Landau Molecular Dynamics. I deras analogi agerar varje nätverksvikt som en atomkoordinat och förlustfunktionen spelar rollen av potentiell energi. Dessa provtagningsmetoder gör det möjligt för dem att kartlägga ett "entropi-landskap" som visar, för varje kombination av träningsförlust och testnoggrannhet (eller testförlust), hur stor del av parameterutrymmet som upptas.
Högentropitillstånd vinner över många uppgifter
Teamet tillämpar detta ramverk på fyra mycket olika problem: en leksakstask för spiralklassificering, att förutsäga bostadspriser från tabulära data, att känna igen handskrivna siffror från en reducerad MNIST-dataset, och att förutsäga polymerers bandgapenergier från kemiska strängar. I varje fall jämför de typiska nätverk tränade med standardoptimerare, såsom stokastisk gradientnedstigning (eller Adam i en regressionsuppgift), med de högentropitillstånd som hittas vid samma träningsförlust. Konsekvent matchar eller överträffar högentropitillstånden de konventionellt tränade näten på testdata, ofta med stor marginal när träningsförlusten är låg. I klassificeringsproblem beter sig högentropitillstånd vid hög förlust som slumpmässiga gissare, medan de vid låg förlust koncentrerar sig nära den bästa möjliga noggrannheten, vilket stärker metodens fysikaliska konsistens.
Varför mindre nätverk visar en starkare effekt
För att förstå när denna fördel är mest uttalad varierar författarna nätverkens bredd i en spiralregressionstask och relaterade benchmarks. De finner att när nätverk blir bredare — och närmar sig det regime där teorin säger att de beter sig som Gaussiska processer — krymper högentropifördelen stadigt och kan till och med försvinna för mycket breda modeller. Smalare, fortfarande överparametriserade nätverk uppvisar en tydlig klyfta: högentropitillstånd generaliserar märkbart bättre än tillstånden som nås genom standardträning. Detta antyder att i realistiska nätverk med ändlig bredd spelar både struktur i parameterutrymmet och hur träningsalgoritmer utforskar det roll för generalisering.
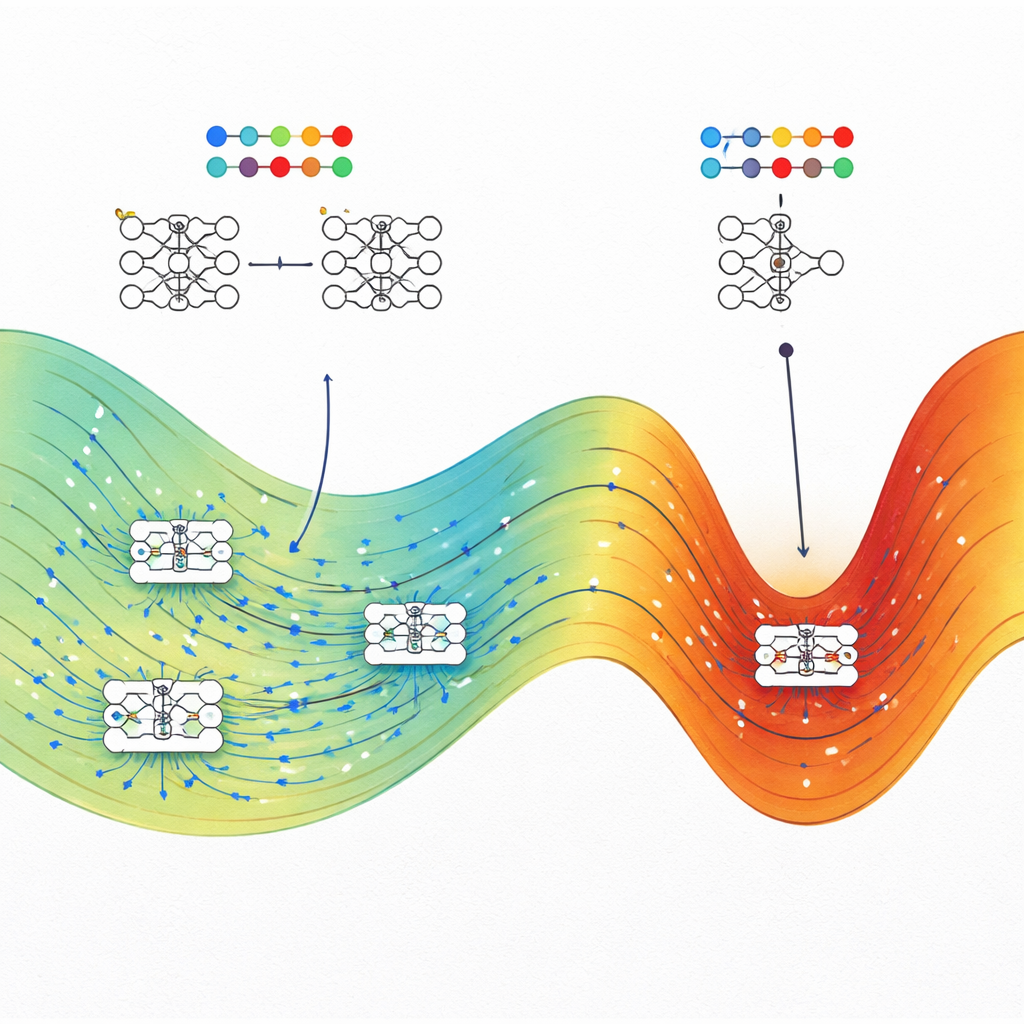
Vad detta betyder för att bygga bättre AI
Huvudbudskapet för icke-specialister är att god generalisering i neurala nätverk inte är en slump. Författarna visar att, vid en given nivå av träningsprestanda, upptar välgeneraliserande lösningar typiskt ett mycket större "volym" av möjliga parameterinställningar än spröda, överanpassade lösningar. Träningsmetoder som stokastisk gradientnedstigning tenderar att hamna i dessa stora regioner, vilket förklarar varför dagens överparametriserade modeller ändå kan prestera bra utan tungt regleringspådrag. Arbetet antyder också praktiska strategier: genom att medvetet styra träningen mot maximala entropiregioner — med fysikinspirerade optimeringsmetoder — kan ingenjörer kanske göra AI-system mer robusta och tillförlitliga utan att behöva omdesigna arkitekturerna från grunden.
Citering: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Nyckelord: neuralt nätverks generalisering, entropi inom maskininlärning, förlustlandskap, överparametriserade modeller, statistisk fysik för AI