Clear Sky Science · pl
Zaletą wysokiej entropii w uogólnianiu sieci neuronowych
Dlaczego to ma znaczenie dla codziennej sztucznej inteligencji
Nowoczesne systemy sztucznej inteligencji potrafią rozpoznawać twarze, tłumaczyć języki i przewidywać ceny domów z niezwykłą precyzją — a jednak nadal nie rozumiemy w pełni, dlaczego działają tak dobrze na nowych, nieznanych danych. Artykuł ten podejmuje się rozwiązania tej zagadki, korzystając z idei zapożyczonych z fizyki. Autorzy pokazują, że najbardziej niezawodne sieci neuronowe to nie te, które jedynie dopasowują się do danych treningowych, lecz te, które znajdują się w „przestronnych” regionach przestrzeni parametrów — cechę nazwaną przez nich przewagą wysokiej entropii.
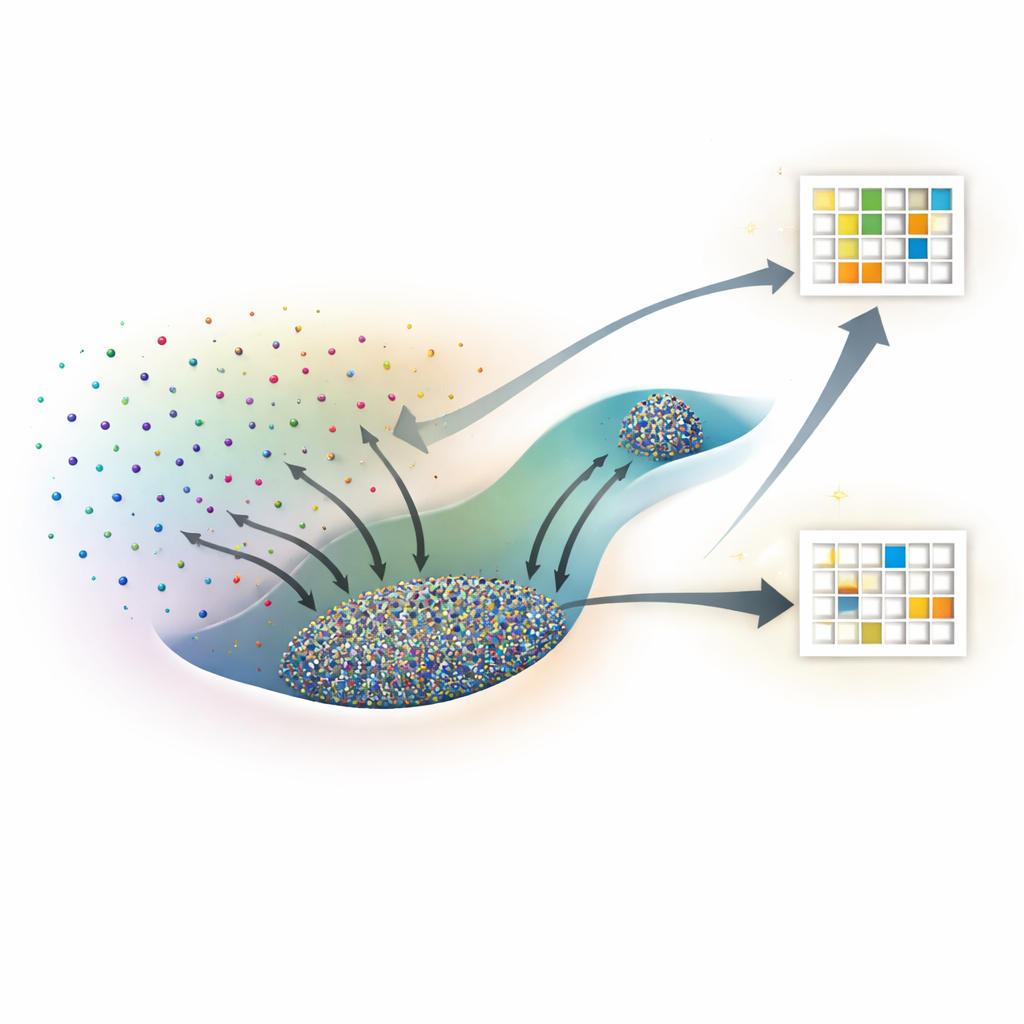
Nowe spojrzenie na wnętrze sieci neuronowych
Zamiast traktować sieć neuronową jak czarną skrzynkę, badacze wyobrażają sobie każde możliwe ustawienie wag jako punkt w rozległym krajobrazie. Wiele różnych punktów może równie dobrze dopasowywać się do danych treningowych, ale niektóre z tych rozwiązań uogólniają na nowe dane, a inne nie. Odwołując się do fizyki statystycznej, traktują każdą konkretną konfigurację wag jako mikrostan, a jej ogólną wydajność — stratę treningową i dokładność testu — jako własności makroskopowe. Kluczową wielkością, którą badają, jest entropia, mierząca tutaj, jak rozległy jest fragment przestrzeni parametrów odpowiadający danemu poziomowi wydajności na zbiorze treningowym i testowym.
Zap借wanie narzędzi z symulacji molekularnych
Bezpośrednie policzenie, ile konfiguracji sieci osiąga określoną wydajność, jest niemożliwe, ponieważ ustawień wag jest nieskończenie wiele w przestrzeni ciągłej. Aby obejść ten problem, autorzy adaptują algorytmy pierwotnie opracowane do badania molekuł, znane jako Monte Carlo Wang–Landau i Wang–Landau Molecular Dynamics. W ich analogii każda waga sieci działa jak współrzędna atomu, a funkcja straty pełni rolę energii potencjalnej. Metody próbkowania pozwalają im zmapować „krajobraz entropii”, który pokazuje, ile przestrzeni parametrów zajmuje każda kombinacja straty treningowej i dokładności testu (lub straty testowej).
Stany o wysokiej entropii wygrywają w wielu zadaniach
Zespół stosuje to ujęcie do czterech bardzo różnych problemów: zabawkowego zadania klasyfikacji spirali, przewidywania cen domów na danych tabelarycznych, rozpoznawania ręcznie pisanych cyfr z zredukowanego zbioru MNIST oraz przewidywania przerw pasmowych polimerów na podstawie ciągów chemicznych. W każdym przypadku porównują typowe sieci trenowane standardowymi optymalizatorami, takimi jak stochastyczny spadek gradientu (oraz Adam w jednym zadaniu regresji), z najwyższymi stanami entropii znalezionymi przy tym samym poziomie straty treningowej. Konsekwentnie stany o wysokiej entropii dorównują lub przewyższają konwencjonalnie trenowane sieci na danych testowych, często z znaczną przewagą przy niskiej stracie treningowej. W zadaniach klasyfikacyjnych stany o wysokiej entropii przy dużej stracie zachowują się jak losowe zgadywanie, podczas gdy przy niskiej stracie skupiają się blisko najlepszej osiągalnej dokładności, co wzmacnia fizyczną spójność podejścia.
Dlaczego efekt jest silniejszy w mniejszych sieciach
Aby zrozumieć, kiedy ta przewaga jest najbardziej widoczna, autorzy zmieniają szerokość sieci na zadaniu regresji spirali i powiązanych benchmarkach. Stwierdzili, że w miarę jak sieci stają się szersze — zbliżając się do reżimu, w którym teoria opisuje je jako procesy Gaussowskie — przewaga wysokiej entropii stopniowo maleje i może nawet zniknąć dla bardzo szerokich modeli. Węższe, nadal nadparametryzowane sieci wykazują wyraźną różnicę: stany o wysokiej entropii uogólniają wyraźnie lepiej niż stany osiągane przez standardowe treningi. Sugeruje to, że w realistycznych sieciach o skończonej szerokości zarówno struktura przestrzeni parametrów, jak i sposób, w jaki algorytmy treningowe ją eksplorują, mają znaczenie dla uogólniania.
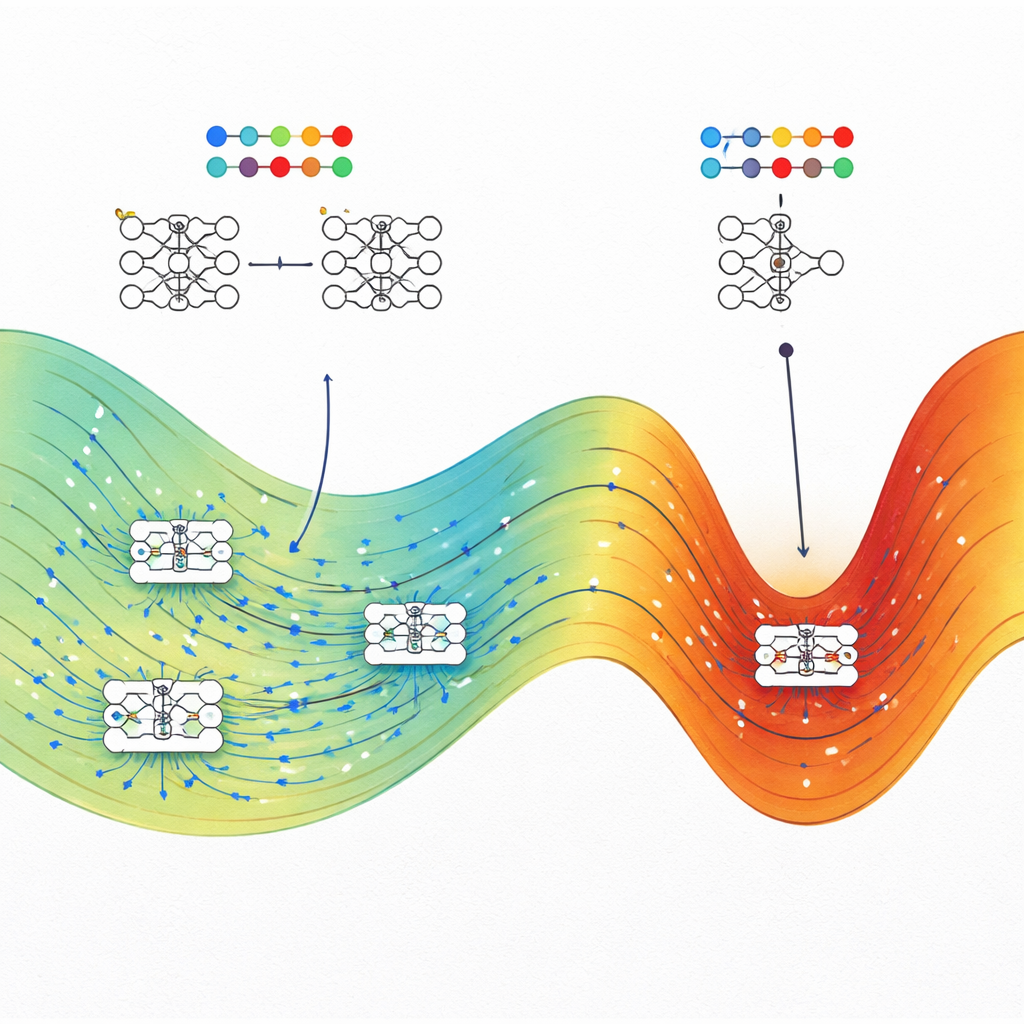
Co to oznacza dla budowy lepszej AI
Główne przesłanie dla czytelników niebędących specjalistami jest takie, że dobre uogólnianie w sieciach neuronowych nie jest przypadkiem. Autorzy pokazują, że przy danym poziomie wydajności treningowej rozwiązania dobrze uogólniające zwykle zajmują znacznie większą „objętość” możliwych ustawień parametrów niż kruche, przeuczone rozwiązania. Metody treningowe, takie jak stochastyczny spadek gradientu, mają skłonność do lądowania w tych dużych regionach, co tłumaczy, dlaczego dzisiejsze nadparametryzowane modele mogą dobrze działać bez agresywnej regularizacji. Praca ta sugeruje również praktyczne strategie: celowe kierowanie treningu w stronę regionów maksymalnej entropii — z użyciem metod optymalizacji inspirowanych fizyką — może pozwolić inżynierom uczynić systemy AI bardziej odporne i wiarygodne, bez konieczności przebudowy architektury od podstaw.
Cytowanie: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Słowa kluczowe: uogólnianie sieci neuronowych, entropia w uczeniu maszynowym, krajobraz funkcji straty, modele nadparametryzowane, fizyka statystyczna AI