Clear Sky Science · es
Ventaja de alta entropía en la generalización de redes neuronales
Por qué esto importa para la IA cotidiana
Los sistemas de inteligencia artificial modernos pueden reconocer rostros, traducir idiomas y predecir precios de viviendas con una precisión asombrosa, pero aún no comprendemos por completo por qué funcionan tan bien con datos nuevos y no vistos. Este artículo aborda ese misterio usando ideas tomadas de la física. Los autores muestran que las redes neuronales más fiables no son solo las que ajustan los datos de entrenamiento, sino las que habitan regiones “espaciosas” de su espacio de parámetros internos, una propiedad que denominan ventaja de alta entropía.
Una nueva manera de mirar dentro de las redes neuronales
En lugar de tratar una red neuronal como una caja negra, los investigadores imaginan cada posible configuración de sus pesos internos como un punto en un vasto paisaje. Muchos puntos distintos pueden ajustar los datos de entrenamiento por igual, pero algunas de esas soluciones generalizan a datos nuevos y otras no. Basándose en la física estadística, tratan cada configuración específica de pesos como un microestado y su rendimiento global—pérdida de entrenamiento y precisión en la prueba—como propiedades macroscópicas. La magnitud clave que estudian es la entropía, que aquí mide qué tan grande es una región del espacio de parámetros que corresponde a un determinado nivel de rendimiento en entrenamiento y prueba.
Tomando herramientas de simulaciones moleculares
Contar directamente cuántas configuraciones de red alcanzan un rendimiento particular es imposible, porque hay infinitas configuraciones continuas de pesos. Para sortear esto, los autores adaptan algoritmos desarrollados originalmente para estudiar moléculas, conocidos como Wang–Landau Monte Carlo y Wang–Landau Molecular Dynamics. En su analogía, cada peso de la red actúa como una coordenada atómica, y la función de pérdida juega el papel de energía potencial. Estos métodos de muestreo les permiten cartografiar un “paisaje de entropía” que muestra, para cada combinación de pérdida de entrenamiento y precisión en la prueba (o pérdida en la prueba), cuánto del espacio de parámetros está ocupado.
Los estados de alta entropía ganan en muchas tareas
El equipo aplica este marco a cuatro problemas muy distintos: una tarea de clasificación de espiral toy, la predicción de precios de viviendas a partir de datos tabulares, el reconocimiento de dígitos escritos a mano a partir de un conjunto MNIST reducido y la predicción de energías de banda de polímeros a partir de cadenas químicas. En cada caso, comparan redes típicas entrenadas con optimizadores estándar, como descenso de gradiente estocástico (o Adam en una tarea de regresión), con los estados de mayor entropía encontrados al mismo nivel de pérdida de entrenamiento. De forma consistente, los estados de alta entropía igualan o superan a las redes entrenadas convencionalmente en datos de prueba, a menudo con una diferencia amplia cuando la pérdida de entrenamiento es baja. En problemas de clasificación, los estados de alta entropía con pérdida alta se comportan como adivinos aleatorios, mientras que con pérdida baja se concentran cerca de la mejor precisión alcanzable, reforzando la consistencia física del enfoque.
Por qué las redes más pequeñas muestran un efecto más marcado
Para entender cuándo esta ventaja es más pronunciada, los autores varían la anchura de las redes neuronales en una tarea de regresión en espiral y en benchmarks relacionados. Encuentran que a medida que las redes se hacen más anchas—acercándose al régimen donde la teoría dice que se comportan como procesos gaussianos—la ventaja de alta entropía disminuye de forma constante y puede incluso desaparecer para modelos muy anchos. Las redes más estrechas, aunque sobreparametrizadas, exhiben una brecha clara: los estados de alta entropía generalizan de manera notablemente mejor que los estados alcanzados por el entrenamiento estándar. Esto sugiere que en redes de anchura finita y realistas, la estructura del espacio de parámetros y la forma en que los algoritmos de entrenamiento lo exploran importan para la generalización.
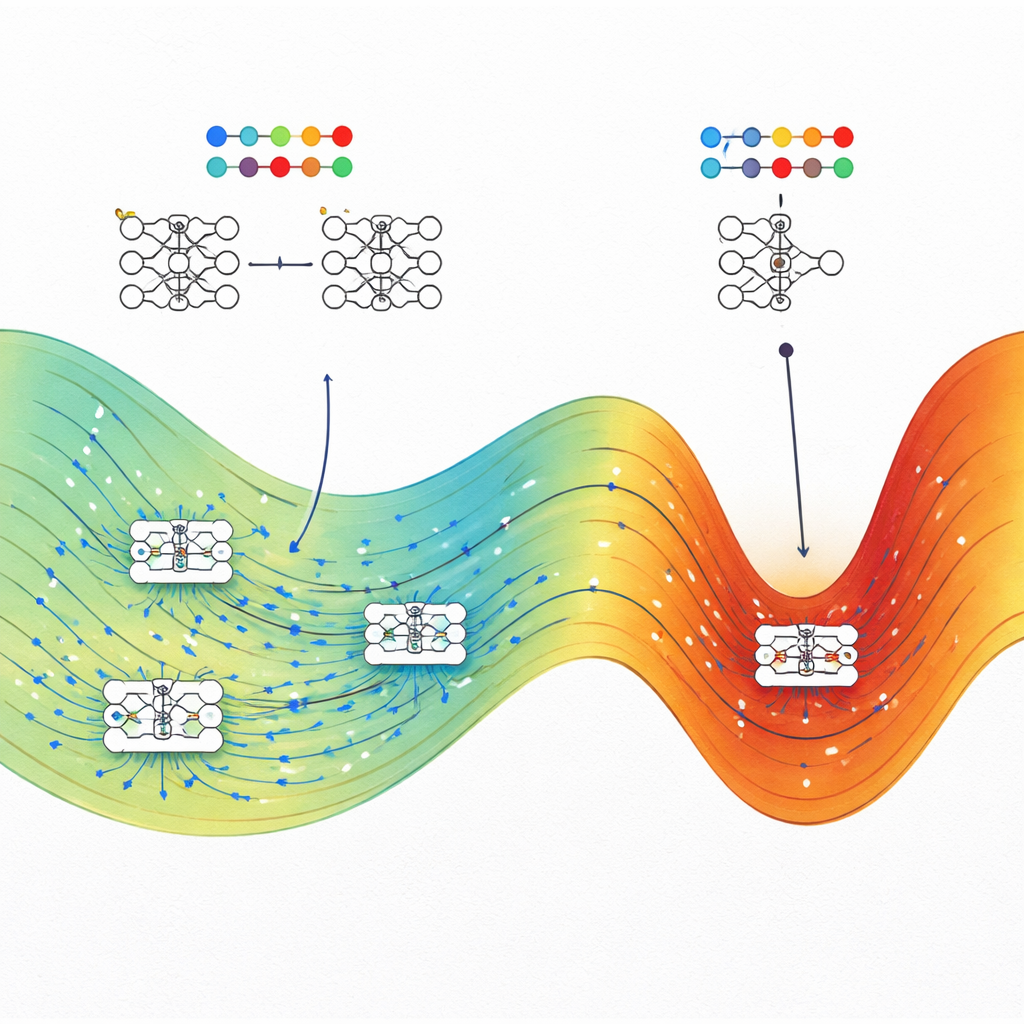
Qué implica esto para construir mejor IA
El mensaje central para no especialistas es que la buena generalización en redes neuronales no es un accidente. Los autores muestran que, a un mismo nivel de rendimiento en entrenamiento, las soluciones que generalizan bien típicamente ocupan un “volumen” mucho mayor de posibles configuraciones de parámetros que las soluciones frágiles y sobreajustadas. Métodos de entrenamiento como el descenso de gradiente estocástico tienden a aterrizar en estas grandes regiones, lo que explica por qué los modelos sobreregulados de hoy pueden seguir funcionando bien sin una regularización excesiva. El trabajo también sugiere estrategias prácticas: al dirigir deliberadamente el entrenamiento hacia regiones de máxima entropía—usando métodos de optimización inspirados en la física—los ingenieros podrían hacer que los sistemas de IA sean más robustos y fiables sin rediseñar sus arquitecturas desde cero.
Cita: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Palabras clave: generalización de redes neuronales, entropía en aprendizaje automático, paisaje de pérdida, modelos sobreregulados, física estadística de la IA